
日本語音声認識の分野は進化を続けています。
新たな技術が次々と登場し、それらはより正確で迅速な認識を可能にしています。
その中でもReazonSpeech v2.0は、特筆すべき存在です。
この記事では、そのインストール方法と基本的な使い方を紹介します。
本記事の内容
- ReazonSpeech v2.0とは?
- ReazonSpeech v2.0のインストール
- ReazonSpeech v2.0の動作確認
それでは、上記に沿って解説していきます。
ReazonSpeech v2.0とは?
ReazonSpeechとは、音声認識モデルです。
2024年2月14日、その最新バージョン v2.0が公開されました。
公式ページでは、次のグラフでReazonSpeech v2.0の性能がアピールされています。
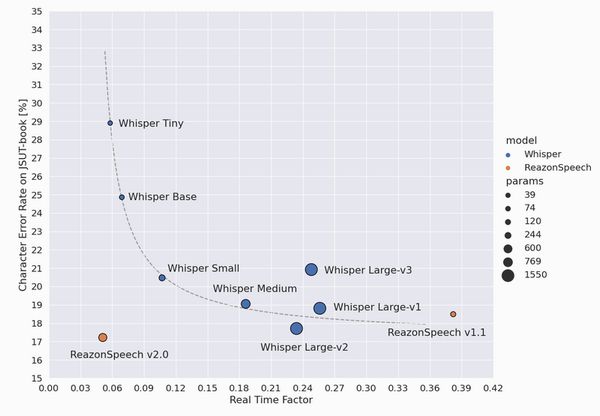
この図は、様々な音声認識モデルの性能を比較した散布図(スキャッタープロット)になります。
| 横軸(X軸) | Real Time Factor(実時間係数) |
| 縦軸(Y軸) | Character Error Rate on JSUT-book [%](文字誤認識率) |
Real Time Factor (RTF)は、モデルが1秒の音声を処理するのに要する時間を表します。
例えば、RTFが0.5であれば、1秒の音声を処理するのに0.5秒かかることを意味します。
これが1より小さい値であればリアルタイムで処理が可能であることを示します。
Character Error Rate (CER)は、文字レベルでの誤認識率をパーセンテージで表しています。
これは、認識結果と真のテキストとの間で発生する誤りの割合を示しており、低いほど性能が良いことを意味します。
このグラフが正しいなら、ReazonSpeech v2.0が最高のモデルだと言えます。
最も高速でありながら、最も認識精度が高いモデルと言うことになりますから。
ReazonSpeech v2.0のインストール
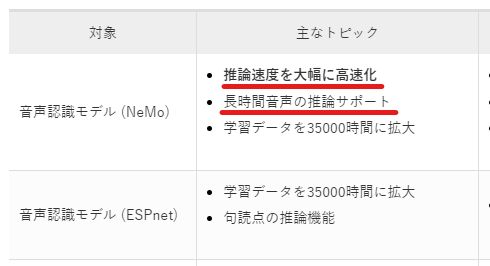
ReazonSpeech v2.0では、以下の技術をベースにしたモデルが公開されるようになっています。
- NVIDIA NeMo
- ESPnet
従来は、ESPnetだけでした。
ESPnetは、基本的にはWindowsでは動きません。
しかし、NVIDIA NeMoはWindowsでも動きます。
よって、ReazonSpeech v2.0はWindowsユーザーでも利用できます。
もちろん、LinuxでもNeMo版は利用可能です。
そして、NeMo版の方が高性能のように見えます。
したがって、ここではNeMo版のインストールを紹介します。
導入方法は、次の記事で説明されています。

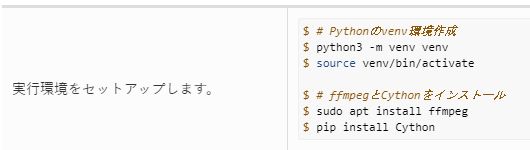
Python仮想環境については、次の記事で解説しています。

FFmpegについては、以下を参考にしてください。


Cythonについては、Cの関数を操作するために必要ということでしょう。
次のコマンドを流しておきます。
pip install Cython
準備ができたら、リポジトリをダウンロードします。
git clone https://github.com/reazon-research/ReazonSpeech
ダウンロードできたら、ディレクトリは移動せずに以下のコマンドを実行。
pip install ReazonSpeech/pkg/nemo-asr
これで必要なモノが一気にインストールされます。
時間は、そこそこかかります。
処理が終わったら、ReazonSpeech v2.0のインストールは完了です。
ReazonSpeech v2.0の動作確認
サンプルコードが、公開されています。
test.py
from reazonspeech.nemo.asr import load_model, transcribe, audio_from_path
# 実行時にHugging Faceからモデルを取得します (2.3GB)
model = load_model(device='cuda')
# ローカルの音声ファイルを読み込む
audio = audio_from_path('speech-001.wav')
# 音声認識を適用する
ret = transcribe(model, audio)
print(ret.text)
音声は、以下のURLからダウンロード可能です。
https://research.reazon.jp/_downloads/a8f2c35bb3d351a76212b2257d5bfc85/speech-001.wav
上記コードを実行してみましょう。
Windowsの場合は、次のようなエラーが出ると思います。
AssertionError: Torch not compiled with CUDA enabled
このエラーの原因は、CPU版のPyTorchがインストールされているからです。
そのため、手動でGPU版のPyTorchをインストールします。
GPU版PyTorchについては、以下の記事で解説しています。

インストール(置き換える)するのは、最新版でOK。
私の環境では、以下のコマンドでインストールしています。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
コードが上手く実行されると、以下がコンソールに表示されます。
気象庁は雪や路面の凍結による交通への影響、暴風雪や高波に警戒するとともに雪崩や屋根からの落雪にも十分注意するよう呼びかけています。
ここまで確認できれば、ReazonSpeech v2.0の動作確認は完了です。

