
「音声データの前処理を効率的に行いたい」
「音声ファイルを音声部分毎に分割したい」
このような場合には、この記事の内容が参考になります。
この記事では、音声区間検出による音声データの前処理を行う方法を解説します。
本記事の内容
- 音声区間検出(VAD)とは?
- 音声区間検出のシステム要件
- 音声区間検出のスクリプト
それでは、上記に沿って解説していきます。
音声区間検出(VAD)とは?
音声区間検出は、英語ではVoice Activity Detectionとなります。
略して、VADです。
音声信号の中から実際に話者が発声している部分を特定します。
無音や背景ノイズなどの非発声区間を区別する技術です。
この技術は、音声認識システムや通信システムにおいて重要な役割を果たしています。
- 音声と非音声の区別
- 帯域幅の節約と効率化
- 音声認識の精度向上
具体的には、以下のシステムやアプリケーションで応用されることになります。
- 電話システム
- 自動音声応答(IVR)システム
- 音声認識アプリケーション
- セキュリティシステム
音声区間検出は、多岐にわたる分野で使用される重要な技術です。
この技術により、システムは必要な音声データのみを処理することができます。
結果的に、無駄を省きつつ、ユーザー体験を向上させることが可能になります。
音声区間検出のシステム要件
音声区間検出は、様々な方法が公開されています。
その中でも、Silero VADは精度が高いモデルとして有名です。
GitHubのStarも結構な数値となっています。
オープンソースでありながら、商用製品を上回る精度を持つとのことです。
そんなSilero VADを利用するには、PyTorchが必要になります。
公式には、以下のバージョンでサポートされています。
- pytorch >= 1.12.0
- torchaudio >= 0.9.0
処理は速い方がいいので、GPU版をインストールしましょう。

また、ややこしいのですがSilero VADはモデルに過ぎません。
PyTorchの関数を用いて、以下のようなコードでモデルを利用することになります。
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True,
onnx=USE_ONNX)
あとは、このモデルを利用して音声区間検出を行います。
そのためには、音声ファイルを読み込む必要があります。
その際に用いるのは、次のライブラリです。

音声区間検出だけなら、PyTorchとSoundfileでOK。
ただ、音声区間検出で取得できるのは次のようなデータになります。
{'start': 5664, 'end': 184800},
{'start': 207904, 'end': 284128},
{'start': 354848, 'end': 486880},
{'start': 506912, 'end': 584672},
{'start': 607264, 'end': 753120},
{'start': 784928, 'end': 945120},
{'start': 970272, 'end': 1053152},
{'start': 1071648, 'end': 1255904},
{'start': 1283616, 'end': 1410016},
{'start': 1441312, 'end': 1513440},
{'start': 1538592, 'end': 1616864},
{'start': 1634848, 'end': 1710560},
{'start': 1727520, 'end': 1767904}]
ミリ秒で表示された区間に音声があると言えます。
でも、本当にやりたいことは音声ファイルを上記区間毎に分割することなんですよね。
そんなときには、Pydubが役に立ちます。
PydubはFFmpegをPythonから操作するためのライブラリです。

あと、追加でtqdmも必要になります。

大きなサイズの音声ファイルを分割する場合、処理時間が長くなる可能性があります。
その場合に、処理の進捗状況を確認できることは重要です。
ここまでを整理しましょう。
- PyTorch
- Soundfile
- Pydub
- tqdm
少なくとも、これらのインストールが必要となります。
音声区間検出のスクリプト
音声区間検出と言いながら、ファイル分割まで処理に含みます。
そのためのスクリプトは、以下。
SpeechSegmenter.py
import argparse
import os
import shutil
import torch
from pydub import AudioSegment
from tqdm import tqdm
# モデルとユーティリティのロード
vad_model, utils = torch.hub.load(repo_or_dir="snakers4/silero-vad", model="silero_vad", onnx=False)
(get_speech_timestamps, _, read_audio, *_) = utils
# グローバル設定
SAMPLING_RATE = 16000
MARGIN = 200
AUDIO_FRAME_RATE = 44100
def get_stamps(audio_file, min_silence_dur_ms=700, min_sec=2):
"""
音声ファイルから発話のタイムスタンプを取得する。
Args:
audio_file (str): 入力の.wavファイルのパス。
min_silence_dur_ms (int): 無音と判断する最小ミリ秒。
min_sec (int): 無視する最小秒数。
Returns:
list of dict: 発話のタイムスタンプリスト。
"""
wav = read_audio(audio_file, sampling_rate=SAMPLING_RATE)
return get_speech_timestamps(
wav, vad_model, sampling_rate=SAMPLING_RATE,
min_silence_duration_ms=min_silence_dur_ms,
min_speech_duration_ms=min_sec * 1000)
def split_wav(audio_file, target_dir, max_sec=12, min_silence_dur_ms=700, min_sec=2):
upper_bound_ms = max_sec * 1000
speech_timestamps = get_stamps(audio_file, min_silence_dur_ms, min_sec)
audio = AudioSegment.from_wav(audio_file).set_frame_rate(AUDIO_FRAME_RATE).set_channels(1)
total_ms = len(audio)
file_name = os.path.splitext(os.path.basename(audio_file))[0]
os.makedirs(target_dir, exist_ok=True)
total_time_ms = 0
for i, ts in enumerate(speech_timestamps):
start_ms = max(ts["start"] / 16 - MARGIN, 0)
end_ms = min(ts["end"] / 16 + MARGIN, total_ms)
if end_ms - start_ms > upper_bound_ms:
continue
segment = audio[start_ms:end_ms]
segment.export(os.path.join(target_dir, f"{file_name}-{i}.wav"), format="wav")
total_time_ms += end_ms - start_ms
return total_time_ms / 1000
def main(input_dir, target_dir, max_sec, min_sec, min_silence_dur_ms):
if os.path.exists(target_dir):
print(f"{target_dir}フォルダが存在するので、削除します。")
shutil.rmtree(target_dir)
wav_files = [f for f in os.listdir(input_dir) if f.lower().endswith(".wav")]
total_sec = 0
for wav_file in tqdm(wav_files, desc="Processing WAV files"):
time_sec = split_wav(
os.path.join(input_dir, wav_file), target_dir,
max_sec, min_silence_dur_ms, min_sec)
total_sec += time_sec
print(f"Done! Total time: {total_sec / 60:.2f} min.")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--input_dir", type=str, default="inputs")
parser.add_argument("--target_dir", type=str, default="raw")
parser.add_argument("--max_sec", type=int, default=12)
parser.add_argument("--min_sec", type=int, default=2)
parser.add_argument("--min_silence_dur_ms", type=int, default=700)
args = parser.parse_args()
main(args.input_dir, args.target_dir, args.max_sec, args.min_sec, args.min_silence_dur_ms)
これは、以下を参考にしています。
https://github.com/litagin02/slice-and-transcribe/blob/main/slice.py
処理内容は踏襲して、リファクタリングを行っています。
利用方法は、次のようにして実行します。
python SpeechSegmenter.py --input_dir inputs --target_dir raw
実行する前に、「–input_dir」で指定するディレクトリには音声ファイルを設置しておきます。
複数もOK。
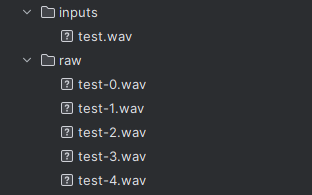
処理が完了すると、「–target_dir」で指定したディレクトリに分割されたファイルが保存されます。

