
「DALL-E 3、ヤバすぎ・・・」
「AI美女生成のレベルをアップさせたい」
このような場合には、この記事の内容が参考になります。
この記事では、DALL-E 3とStable Diffusionを統合したAI美女生成の方法を解説しています。
本記事の内容
- DALL-E 3によるAI美女生成
- Stable DiffusionとDALL-E 3の統合
- Stable DiffusionとDALL-E 3の統合方法【AI美女画像】
それでは、上記に沿って解説していきます。
DALL-E 3によるAI美女生成
DALL-E 3を試しましたか?
無料でも利用できるので、まだの方は試してみましょう。
そのDALL-E 3を用いて、AI美女を生成することが可能です。
適当にプロンプトを作成して、DALL-E 3で生成したのが次のAI美女の画像になります。

それでこのレベルです。
質が高いのはもちろんですが、Stable Diffusionで見かけるAI美女とは顔が異なります。
どちらが上とか言うのではなく、明らかな違いを感じます。
そりゃ、当然と言えば当然ですね。
これは、モデル(学習素材)の違いというレベルではありません。
そもそものAIシステムが異なるのですからね。
システムが異なると言えば、DALL-E 3は企業のWebサービスで提供されています。
そのため、少しでも怪しいコンテンツはNGの対象になります。
規制が緩い方のBing版でも、想定以上にNSFW判定を受けてしまいます。

正直、基準はわかりません。
例えば、次のプロンプトはセーフです。
Portrait of a young woman with straight dark hair and bangs, looking directly at the camera. She wears a lace high-neck top and has statement earrings with multiple pearls. She holds her hand gracefully near her chin, showcasing her elegant nail polish. The background is a uniform soft peach color
これで生成した結果は、以下となります。

しかし、これに「japanese」を加えただけでNGになってしまいます。
1箇所に「japanese」を足しただけです。
Portrait of a young japanese woman with straight・・・
3回試しましたが、すべて同じ結果になります。
「japanese」なしは、3回ともOK。
「japanese」ありは、3回ともNG。
本当に意味不明です。
よって、DALL-E 3では必要以上に安全なプロンプトの入力をオススメします。
なお、適当に作成したプロンプトはCahtGPTに作成させています。
興味のある方は、次の記事をご覧ください。

以上、DALL-E 3によるAI美女生成を説明しました。
次は、Stable DiffusionとDALL-E 3の統合を説明します。
Stable DiffusionとDALL-E 3の統合
DALL-E 3は、かなり魅力的です。
とは言え、Stable Diffusionでの自由度を手放すことはできません。
そこで、DALL-E 3で生成した画像をStable Diffusionで活用しようということです。
それを少し大げさですが、Stable DiffusionとDALL-E 3の統合と表現しています。
統合するには、ControlNetをメインで利用することになります。
DALL-E 3で生成した画像をControleNetで制御して、求める画像を生成します。
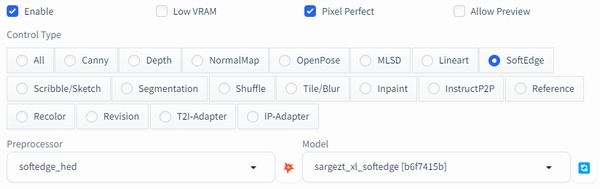
その際に用いるプリプロセッサは、以下。
- SoftEdge
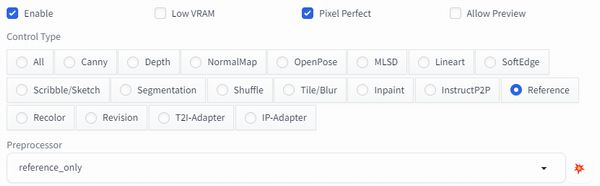
- Reference
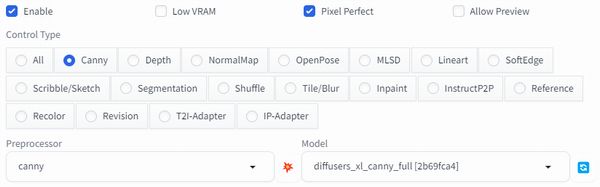
- Canny
基本的には、SoftEdgeとReferenceの組み合わせです。
DALL-E 3製の画像に最大限で似せたい場合は、さらにCannyを組み合わせます。
SoftEdgeとReferenceについては、以下の記事が参考になります。


ただし、プリプロセッサを組み合わせる場合はGPUのメモリ不足に注意が必要です。
以上、Stable DiffusionとDALL-E 3の統合を説明しました。
次は、Stable DiffusionとDALL-E 3の統合方法【AI美女画像】を説明します。
Stable DiffusionとDALL-E 3の統合方法【AI美女画像】
Stable DiffusionとDALL-E 3の統合方法を説明します。
その際には、DALL-E 3で生成したAI美女の画像を活用します。
次の画像は、実際にDALL-E 3で生成した画像になります。

この画像を各Unit毎にアップロードします。

それぞれの設定値は、基本的には触りません。
デフォルトのままで問題ないということです。
Unit 0[SoftEdge]
Unit 1[Reference]
Unit 2[Canny]
プロンプトに関しては、ChatGPTに作成させたモノを利用します。
Digital photography of a young woman with flowing brown hair, soft gaze directed towards the viewer, subtle makeup highlighting her clear complexion and natural beauty, close-up facial portrait, soft and ambient lighting emphasizing her features, high-resolution, with a blurred interior background for depth
あと、FreeUを適用しています。

ここでは、3パターンの画像を生成しています。
左からパターンA、B、Cとなります。

各パターンは、次の条件となっています。
| SoftEdge | Reference | プロンプト | Canny | |
| A | 〇 | 〇 | ||
| B | 〇 | 〇 | 〇 | |
| C | 〇 | 〇 | 〇 | 〇 |
パターンAは、プロンプト(以降)がない場合ですね。
トレースは上手くいっています。
しかし、着色が意味不明な状況です。
パターンBは、プロンプトがある場合になります。
この場合では、そこそこ元画像を再現できています。
しかし、今回はまだ元画像を再現できてはいません。
パターンCは、Cannyでさらに再現率を高めています。
今回の画像でも、DALL-E 3で生成した画像を再現できていると言えるでしょう。
髪色や肌色などの細かい部分は、モデルやプロンプトを変えることで対応可能です。
上記の画像は、fuduki_mixをモデルに利用しています。

モデルを変えた結果は、以下。

それぞれ順番に以下のモデルによる結果となります。




モデルによっては、外国人になってしまっています。
確かに、プロンプトに「japanese」というワードがありませんからね。
さて、ここまでDALL-E 3で生成した画像を再現する方法を説明してきました。
別の言い方をすれば、Stable DiffusionとDALL-E 3の統合方法です。
再現することがゴールではなく、これは始まりに過ぎません。
モデルやプロンプトを用いて、さらに画像をブラッシュアップしていくことがメインとなっていくことでしょう。
以上、Stable DiffusionとDALL-E 3の統合方法【AI美女画像】を説明しました。

