
Animagine XL 3.0とは?
Animagine XL 3.0は、SDXLベースのカスタムモデルです。
アニメモデルとして、最高になることを目指していると記載されています。
過去バージョンのAnimagine XL 2.0が、ベースになっています。
ただし、V 3.0の学習では大きな変更を加えているということです。
それは、NovelAI Diffusion V3と関係しています。
NovelAIは昨年、第3世代であるNovelAI Diffusion V3を発表しています。
その表現力については、以下のページで以前のバージョンとの比較で公開されています。
https://blog.novelai.net/introducing-novelai-diffusion-anime-v3-6d00d1c118c3
とにかく、大幅な進化だったわけです。
そして、その進化のカギが学習時におけるタグの順序と言われています。
NovelAIは、その調査結果を公開しています。
NovelAI Diffusion V3の公開資料
https://docs.novelai.net/image/tags.html#tag-ordering
この資料によると、次のような順番でプロンプトを構成することがポイントになります。
1boy/1girl, what character, from which series, everything else in random order*
「everything else in random order」
ここには、何でも入れてOKということのようです。
Animagine XL 3.0も同じようにして、学習したと言われています。
その結果、以下のようなプロンプトを入力することで表現力豊かな画像が生成されるようです。
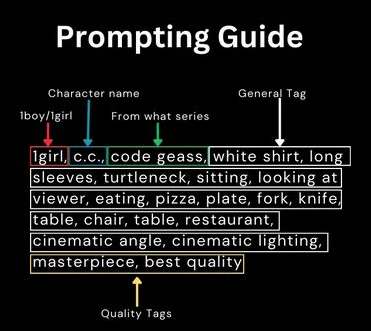
Quality Tagsには、以下を設定できるようになっています。
- masterpiece
- best quality
- high quality
- normal quality
- low quality
- worst quality
なお、Quality Tagsの有無でかなり結果は変わるようです。
また、年代タグ(Year Tags)で画風を制御することができます。

Animagine XL 3.0の動作確認
モデルは、上記ページからダウンロードできます。
ツールは、Stable Diffusion Web UI(AUTOMATIC1111版)でもComfyUIでも何でもOKです。
私は、Fooocusを利用しています。
まず、プロンプトを用意しましょう。
今回は、chichi-puiからダウンロードした画像をDescribeにアプロードします。

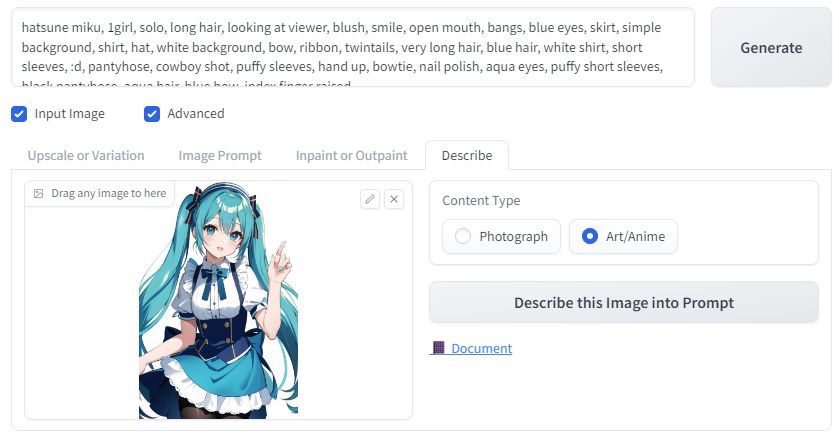
このプロンプトを利用して、同じSEEDで生成したのが以下の画像です。

プロンプトのルールに従ったのが、どちらの画像であるかわかりますか?
左の画像は、次のプロンプトで生成しています。
masterpiece,best quality,hatsune miku, 1girl, solo, 共通
右の画像は、次のプロンプトになります。
1girl,hatsune miku, hatsune miku, 共通, masterpiece,best quality
よって、右の画像がAnimagine XL 3.0のルールに従っています。
ただ、「from what series」に入力すべきモノが不明だったので「Character name」と同じにしています。
同じようにして生成した比較画像を以下に載せておきます。
右がルールに従って生成した画像になります。
「Character name」と「from what series」は、「GIRL, student」にしています。

「Character name」と「from what series」は、「GIRL, girl」にしています。

劇的な違いは、感じません。
しかし、ルールに従った方が良い画像だとは言えそうです。
「from what series」については、次の記事でその利用方法を説明しています。


