
GiNZAは、pipコマンドだけでインストール可能です。
実は、Mecabよりも簡単にインストールできてしまいます。
WindowsへのMecabのインストールは、結構面倒です。
形態素解析を行う選択肢の一つとして、GiNZAもありかもしれません。
何と言っても、機械学習による形態素解析がGiNZAの特徴でもありますからね。
本記事の内容
- GiNZAとは?
- GiNZAのシステム要件
- GiNZAのインストール
- GiNZAの動作確認
それでは、上記に沿って解説していきます。
GiNZAとは?
GiNZAとは、オープンソースの日本語自然言語処理ライブラリです。
GiNZAには、言語処理に関する機能が複数用意されています。
しかし、この記事では形態素解析に絞って説明を進めます。
この場合、GiNZAは機械学習による形態素解析ツールと言えます。
そして、GiNZAは次の2つの基盤技術で成り立っています。
- spaCy
- SudachiPy
spaCyが、機械学習部分を担当します。
SudachiPyが、形態素解析器となります。
つまり、GiNZAという形態素解析器が存在するわけではないのです。
Mecabと同列で語るならば、本来はSudachiPyを語るべきとなります。
GiNZAのイメージとしては、spaCyとSudachiPyの合わせ技という感じです。
合わせることにより、機械学習による形態素解析が実現できています。
なお、SudachiPyは単体でも形態素解析器として機能します。
以上、GiNZAに関する説明でした。
次は、GiNZAのシステム要件を確認していきます。
GiNZAのシステム要件
現時点(2021年4月末)でのGiNZAの最新バージョンは、4.0.5となります。
この最新バージョンは、2020年10月1日にリリースされています。
サポートOSに関しては、以下を含むクロスプラットフォーム対応のはず。
明確には記載されていない場合は、ほぼクロスプラットフォーム対応となります。
- Windows
- macOS
- Linux
実際には、WindowsとLinux(Ubuntu)で動作確認済です。
そして、サポート対象となるPythonのバージョンは3.5以降となります。
setup.pyより
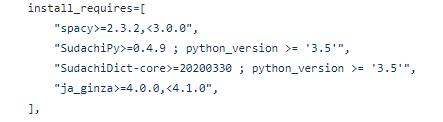
ただし、公式ページでは次のような表記もあります。

まあ、古いPythonでなければOKということでしょう。
なお、私は現時点で最新バージョンとなるPythonで検証しています。
>python -V Python 3.9.4
あと、GiNZAの依存するライブラリには注意が必要です。
GiNZAの基盤技術となる以下の2つですね。
- spaCy
- SudachiPy(Python版Sudachi)
上記で示したsetup.pyにもそれぞれのバージョンが記載されています。
ちなみに、現時点でのそれぞれの最新バージョンは以下。
| spaCy | 3.0.6 |
| SudachiPy | 0.5.2 |
spaCyに関しては、3.0.0以降はアウトのようです。
SudachiPyに関しては、逆に0.4.9以降ならOK。
もし、すでに上記がインストール済みなら、バージョンを合わせる必要があるでしょう。
未インストールなら、何も考える必要はありません。
自動的に適したバージョンがインストールされます。
以上、GiNZAのシステム要件の説明でした。
次は、GiNZAをインストールしていきます。
GiNZAのインストール
最初に、現状のインストール済みパッケージを確認しておきます。
>pip list Package Version ---------- ------- pip 21.1 setuptools 56.0.0
次にするべきことは、pip自体の更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip
では、GiNZAのインストールです。
GiNZAのインストールは、以下のコマンドとなります。
pip install ginza
インストールは、しばらく時間がかかります。
では、どんなパッケージがインストールされたのかを確認しましょう。
>pip list Package Version ---------------- -------------- blis 0.7.4 catalogue 1.0.0 certifi 2020.12.5 chardet 4.0.0 cymem 2.0.5 Cython 0.29.23 dartsclone 0.9.0 ginza 4.0.5 idna 2.10 ja-ginza 4.0.0 murmurhash 1.0.5 numpy 1.20.2 pip 21.1 plac 1.1.3 preshed 3.0.5 requests 2.25.1 setuptools 56.0.0 sortedcontainers 2.1.0 spacy 2.3.5 srsly 1.0.5 SudachiDict-core 20201223.post1 SudachiPy 0.5.2 thinc 7.4.5 tqdm 4.60.0 urllib3 1.26.4 wasabi 0.8.2
多くのパッケージが、インストールされました。
この結果を見ると、GiNZAを既存の環境に導入するのは容易ではないかもしれません。
依存パッケージが多いという点は、注意する必要があるでしょう。
なお、spaCyは2系の最終バージョンがインストールされています。
以上、GiNZAのインストールの説明でした。
最後に、GiNZAの動作確認を行います。
GiNZAの動作確認
GiNZAの動作確認は、以下の二つで行います。
- コマンドラインツール
- Python API
それぞれを下記で確認していきましょう。
コマンドラインツール
「ginza」と入力して、そのあとに形態素解析をしたい文章を入力します。
>ginza DOS窓では、基本的には日本語がアウトです # text = DOS窓では、基本的には日本語がアウトです 1 DOS DOS NOUN 名詞-普通名詞-一般 _ 2 compound _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=CONT|NP_B|Reading=ドス 2 窓 窓 NOUN 名詞-普通名詞-一般 _ 11 obl _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SEM_HEAD|NP_I|Reading=マド 3 で で ADP 助詞-格助詞 _ 2 case _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Reading=デ 4 は は ADP 助詞-係助詞 _ 2 case _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Reading=ハ 5 、 、 PUNCT 補助記号-読点 _ 2 punct _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=CONT|Reading=、 6 基本的 基本的 ADJ 名詞-普通名詞-形状詞可能 _ 11 dislocated _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|Reading=キホンテキ 6 基本的 基本的 ADJ 名詞-普通名詞-形状詞可能 _ 11 dislocated _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|Reading=キホンテキ 7 に だ AUX 助動詞 _ 6 aux _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Inf=助動詞-ダ,連用形-ニ|Reading=ニ 8 は は ADP 助詞-係助詞 _ 6 case _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Reading=ハ 9 日本語 日本語 NOUN 名詞-普通名詞-一般 _ 11 nsubj _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|NP_B|Reading=ニホンゴ|NE=B-LANGUAG E|ENE=B-National_Language 10 が が ADP 助詞-格助詞 _ 9 case _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Reading=ガ 11 アウト アウト NOUN 名詞-普通名詞-一般 _ 0 root _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=ROOT|NP_B|Reading=アウト 12 です です AUX 助動詞 _ 11 cop _ SpaceAfter=No|BunsetuBILabel=I|Bunse
Mecabと同じような出力形式にする場合は、以下のようにします。
>ginzame DOS窓では、基本的には日本語がアウトです DOS 名詞,普通名詞,一般,*,*,*,DOS,ドス,* 窓 名詞,普通名詞,一般,*,*,*,窓,マド,* で 助詞,格助詞,*,*,*,*,で,デ,* は 助詞,係助詞,*,*,*,*,は,ハ,* 、 補助記号,読点,*,*,*,*,、,、,* 基本 名詞,普通名詞,一般,*,*,*,基本,キホン,* 的 接尾辞,形状詞的,*,*,*,*,的,テキ,* に 助動詞,*,*,*,助動詞-ダ,連用形-ニ,だ,ニ,* は 助詞,係助詞,*,*,*,*,は,ハ,* 日本 名詞,固有名詞,地名,国,*,*,日本,ニホン,* 語 名詞,普通名詞,一般,*,*,*,語,ゴ,* が 助詞,格助詞,*,*,*,*,が,ガ,* アウト 名詞,普通名詞,一般,*,*,*,アウト,アウト,* です 助動詞,*,*,*,助動詞-デス,終止形-一般,です,デス,* EOS
ここまで動作確認できれば、コマンドラインツールとしては問題ありません。
Python API
システムに組み込むなら、APIとして使う方がメインになります。
GiuHubで紹介されているコードから、対象とする文章を変更しただけです。
import spacy
nlp = spacy.load('ja_ginza')
doc = nlp('DOS窓では、基本的には日本語がアウトです')
for sent in doc.sents:
for token in sent:
print(token.i, token.orth_, token.lemma_, token.pos_, token.tag_, token.dep_, token.head.i)
print('EOS')
上記を実行した結果は、以下。
0 DOS DOS NOUN 名詞-普通名詞-一般 compound 1 1 窓 窓 NOUN 名詞-普通名詞-一般 obl 10 2 で で ADP 助詞-格助詞 case 1 3 は は ADP 助詞-係助詞 case 1 4 、 、 PUNCT 補助記号-読点 punct 1 5 基本的 基本的 ADJ 名詞-普通名詞-形状詞可能 dislocated 10 6 に だ AUX 助動詞 aux 5 7 は は ADP 助詞-係助詞 case 5 8 日本語 日本語 NOUN 名詞-普通名詞-一般 nsubj 10 9 が が ADP 助詞-格助詞 case 8 10 アウト アウト NOUN 名詞-普通名詞-一般 ROOT 10 11 です です AUX 助動詞 cop 10 EOS
形態素解析した結果は、「ginza」コマンドと同じです。
コードを見ると、やはりspaCyがメインとなります。
あくまで、spaCyが読み込む解析モデルがGiNZAで訓練したモノということです。
以上、GiNZAの動作確認の説明でした。

