
「テキストから音声を生成したい」
「既存の音楽にテキストを加えて、新たな音楽を作成したい」
このような場合には、Audiocraftがオススメです。
この記事では、テキストから音楽を生成できるAudiocraftについて解説しています。
本記事の内容
- Audiocraftとは?
- Audiocraftのシステム要件
- Audiocraftのインストール
- Audiocraftの動作確認
それでは、上記に沿って解説していきます。
Audiocraftとは?
Audiocraftとは、音声生成処理が可能なPythonライブラリです。
PyTorchを前提にしているため、PyTorchライブラリと公式では表現されています。
このAudiocraftの本体は、MusicGenと言えます。
MusicGenとは、音楽生成のためのシンプルで制御可能なモデルになります。
シンプルな制御とは、「happy rock」や「sad jazz」などのテキストで音楽を生成できるということです。
簡単に言うと、Stable Diffusionの音楽版と言えます。
以下の音声ファイルは、Audiocraftで実際に生成した音楽です。
どのようなプロンプトを入力したのか、わかりますか?
答えは、「Audiocraftの動作確認」に記載されています。
個人的には、イメージに近い音楽となって驚きです。
機能に話を戻しましょう。
Audiocraftでは、アップロードした音声ファイルをベースに音楽を生成することも可能です。
Stable Diffusionにおけるimg2imgのような機能と言えます。
また、MusicGenの学習には2万時間のライセンス付音楽が用いられています。
Meta社がMusicGenを開発しているので、権利関係は安心と言えるでしょう。
以上、Audiocraftについて説明しました。
次は、Audiocraftのシステム要件を説明します。
Audiocraftのシステム要件
Audiocraftのシステム要件としては、以下が挙げられています。
- Python 3.9
- PyTorch 2.0.0
- GPU 16GB
- FFmpeg
それぞれを下記で説明します。
Python 3.9
基本的には、PyTorch 2.0.0がインストールできればOKです。
そのため、Python 3.9以降であれば問題ないと言えます。
実際、Python 3.10でも問題なく機能しています。
PyTorch 2.0.0
現状の最新版は、2.0.1となります。

PyTorch 2.0.1でAudiocraftの動作確認を取れています。
そのため、PyTorch 2.0.0以降という認識で問題ないでしょう。
また、GPU版のインストールが必須です。
Windowsへのインストールは、次の記事で解説しています。

GPU 16GB
おそらく、これが最もハードルが高いはずです。
コンシューマー向けのGPUだと、以下しか思い浮かびません。
- GeForce RTX 3090
- GeForce RTX 3090 Ti
- GeForce RTX 4080
- GeForce RTX 4090
ただし、16GBというのは推奨になります。
それ以下でも、smallモデルを利用する場合は処理可能のようです。
もしかしたら、VRAM 8GBでも動くかもしれません。
この辺は、各自でチャレンジしてみてください。
FFmpeg
公式ページには、次のような注意書きがあります。
新しいバージョンのtorchaudioを使用する場合は、ffmpegがインストールされていることを確認してください。
最新のPyTorchをインストールする場合は、該当する状況になるはずです。
仮にそうでなくても、FFmpegはインストールしておきましょう。
FFmpegのインストールは、以下の記事が参考になります。


以上、Audiocraftのシステム要件を説明しました。
次は、Audiocraftのインストールを説明します。
Audiocraftのインストール
Audiocraftのインストールは、Python仮想環境の利用をオススメします。
Python仮想環境は、次の記事で解説しています。

検証は、次のバージョンのPythonで行います。
> python -V Python 3.10.4
では、Audiocraftのインストールを進めていきましょう。
ただし、事前にGPU版PyTorchはインストール済みとします。
そうであれば、Audiocraftは次のコマンドで一撃です。
pip install audiocraft
Audiocraft自体は、これでインストールできます。
これに加えて、GUIのデモプログラムもインストールしましょう。
git clone https://github.com/facebookresearch/audiocraft.git
デモプログラムは、Gradioに依存しています。

そのため、追加でGradioをインストールします。
pip install gradio
以上、Audiocraftのインストールを説明しました。
次は、Audiocraftの動作確認を説明します。
Audiocraftの動作確認
Audiocraftの動作確認を行います。
ダウンロードしたソース内のapp.pyを起動します。
次のコマンドでデモプログラムを起動できます。
python app.py
コンソールに次のように表示されたら、起動はOKです。
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
ブラウザで「http://127.0.0.1:7860」にアクセス。
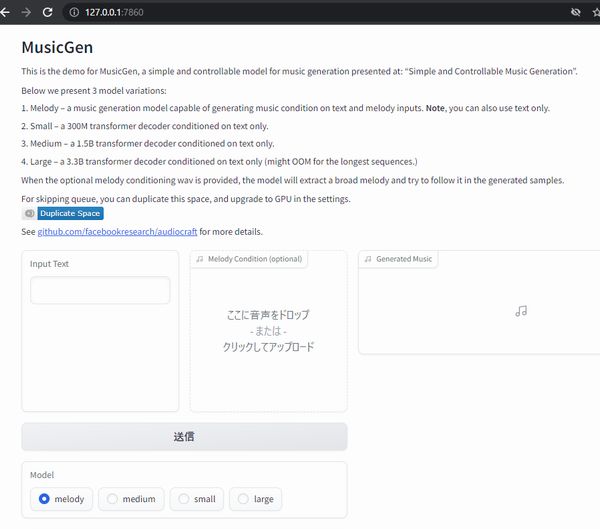
このような画面が表示されます。
今回は、基本的な動作を検証しましょう。
「Input Text」に英語でプロンプトを入力します。
「ローマ帝国の滅亡」の音楽を作成してもらいましょう。
Fall of the Roman Empire
そして、「Model」を選択します。
モデルに関しては、デモ画面の上部に記載があります。

Largeのファイルサイズは、以下。
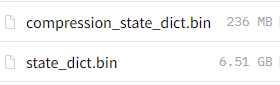
そこまで大きなファイルサイズではありません。
と言っても、GPU次第でしょうね。
ちなみに、GeForce RTX 3090(24GB)でLargeが動くことは確認できています。
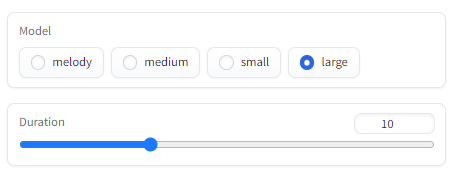
あと、再生時間は「Duration」で設定できます。

最大で「30」秒まで可能となっています。
今回は、次の条件で作成します。
なお、モデルは初回利用時にダウンロードするようになっています。
実際は、キャッシュとして存在するかどうかによります。
Windowsなら、以下の場所になります。
C:\Users\ユーザー\.cache\huggingface\hub
LargeとMediumをダウンロード済みなら、次のようにフォルダが作成されます。
ということで、初回時はそこそこの時間を待つことなります。
そして、音楽が生成されると次のように表示されます。
今回の条件であれば、1分以内に生成できています。
以上、Audiocraftの動作確認を説明しました。

