
「テキスト音声合成(TTS)をローカルマシンで行いたい」
「テキストから高品質で自然な音声を生成したい」
このような場合には、Bert-VITS2がオススメです。
この記事では、Bert-VITS2について解説しています。
本記事の内容
- Bert-VITS2とは?
- Bert-VITS2のシステム要件
- Bert-VITS2のインストール
- Bert-VITS2の動作確認
それでは、上記に沿って解説していきます。
Bert-VITS2とは?
追記 2024年4月28日
日本語の音声合成なら、以下のツールをオススメします。

Bert-VITS2とは、テキスト音声合成(TTS)プロジェクトです。
技術的には、多言語BERTを使用したVITS2をベースにしています。
VITS2は、テキスト音声合成(TTS)のための深層学習モデルです。
高品質で自然な音声を生成することが特徴となっています。
日本語のサンプル音声は、次のページで公開されています。

Bert-VITS2のシステム要件
Bert-VITS2のシステム要件は、特に明記されてはいません。
この記事では、WindowsでBert-VITS2を動かす方法を解説します。
その際のシステム要件としては、PyTorchが事前にインストールされていることになります。
処理速度を考えたらGPU版PyTorchがオススメと言えます。

ただ、CPUだけでもBert-VITS2は動くみたいです。
なお、PyTorchのバージョンは何でも大丈夫な感じです。
現時点における最新版でも、Bert-VITS2は機能しています。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121

Bert-VITS2のインストール
Bert-VITS2のインストールは、Python仮想環境の利用を推奨します。

Bert-VITS2のインストール自体は、簡単です。
まず、プロジェクトをダウンロードします。
git clone https://github.com/fishaudio/Bert-VITS2.git cd Bert-VITS2
リポジトリルートへ移動しておきます。
そして、次のコマンドを実行すればインストールが開始されます。
pip install -r requirements.txt
このコマンドを実行する前に、PyTorchのインストールは済ませておきましょう。
Bert-VITS2のインストールには、そこそこ時間がかかります。
処理が終わったら、Bert-VITS2のインストールは完了です。
Bert-VITS2の動作確認
ここでは、Bert-VITS2の動作確認はテキスト音声合成に絞ります。
いきなり、独自モデルの学習などしようとするとハードルが上がり過ぎです。
まずは、公開されている学習済みモデルを利用してテキスト音声合成を行います。
それを行うために、最適なデモ画面があります。
このデモ画面を利用して、動作確認を行います。
そのためには、準備が必要となります。
まず、リポジトリルートで次のコマンドを実行します。
python webui.py
実行すると、処理に必要なモデルのダウンロードが始まります。
4個ほどダウンロードされて、「bert」以下のディレクトリに配置されます。

コマンド実行の結果は、次のようなエラーで終わるはずです。
FileNotFoundError: [Errno 2] No such file or directory: 'Data/config.json'
今回は、これでOKです。
あくまで、モデルの自動ダウンロードが目的でしたので。
次は、手動でモデルをダウンロードします。
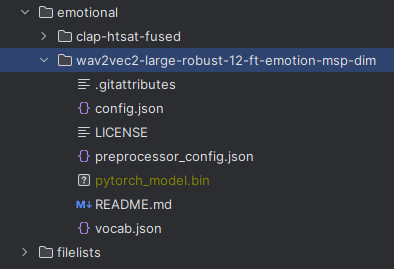
「emotional」ディレクトリ以下にあるモデルを取得することになります。

clap-htsat-fused

上記ページにアクセスして、次のファイルをダウンロードします。
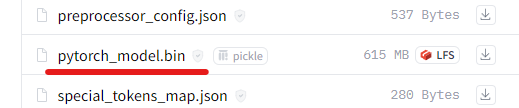
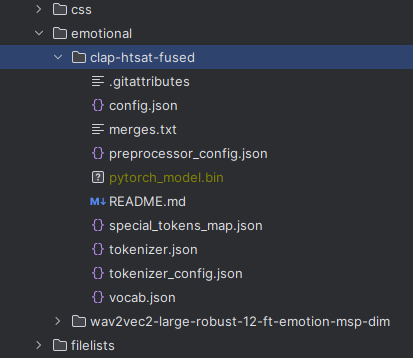
そして、次のように保存します。
wav2vec2-large-robust-12-ft-emotion-msp-dim

上記ページにアクセスします。
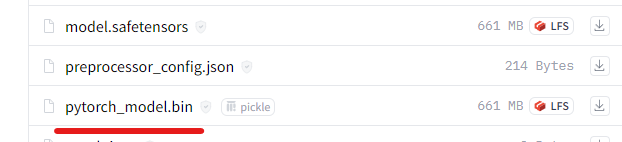
同じようにモデルをダウンロードして、以下のように配置します。
ここまで準備できたら、次は上記で載せたデモ画面に注目です。

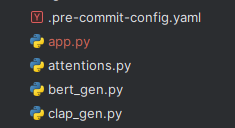
やることは、app.pyのダウンロードと学習済みモデルのダウンロードです。
app.pyは、次のようにリポジトリ直下に保存します。
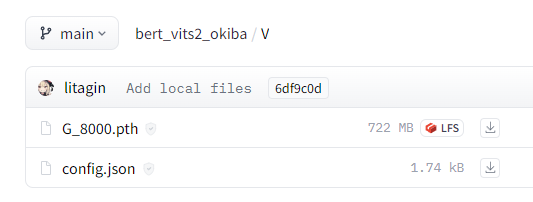
学習済みモデルに関しては、各自で適当に選んでください。
ここでは、「V」のモデルを選びます。
それぞれをダウンロードします。
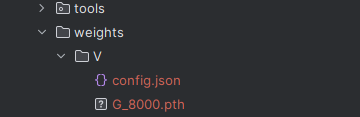
「weights」ディレクトリは、リポジトリルートの直下に作成しています。
ダウンロードしたファイルを次のような構成で保存します。
ここまで行えば、次のコマンドを実行しましょう。
python app.py
起動したら、コンソールに以下が表示されます。
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
ブラウザで「http://127.0.0.1:7860」にアクセスします。
Hugging Face上のデモ画面と同じモノを確認できます。
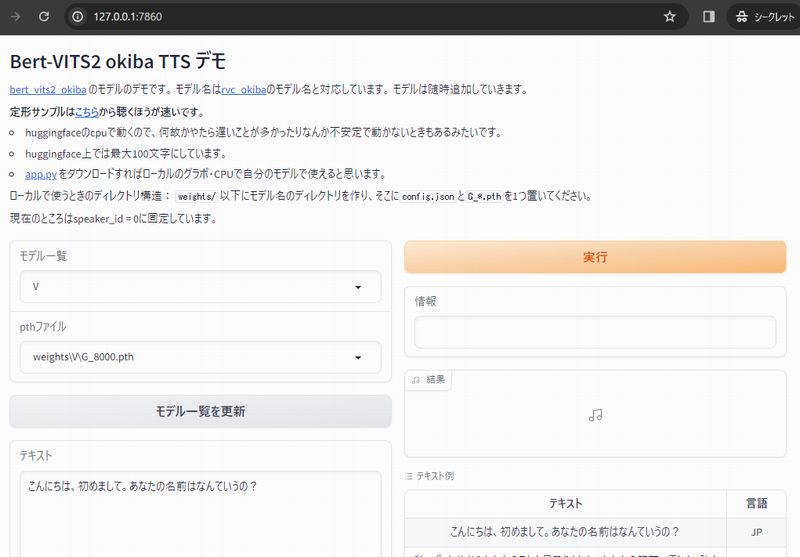
「実行」ボタンを押して、次のように音声ファイルが作成されればOKです。
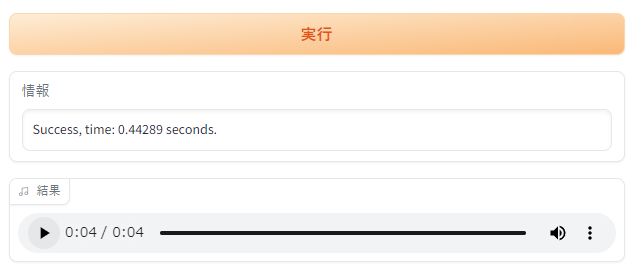
これで、Bert-VITS2のテキスト音声合成の動作は確認できました。
なお、app.pyにはテキストが最大100文字までしか入力できないという制限があります。
その制限は、以下の箇所で設定されています。

この値を変更すれば、長文の音声を生成することが可能です。

