
「Stable Diffusion XL Inpaintingを試したい」
「ローカルマシンでSDXL 1.0のInpaintingを動かしたい」
このような場合には、この記事の内容が参考になります。
この記事では、Stable Diffusion XL Inpaintingについて解説しています。
本記事の内容
- Stable Diffusion XL Inpaintingとは?
- Stable Diffusion XL Inpaintingツールの導入方法
- Stable Diffusion XL Inpaintingツールの動作確認
- 出力画像サイズの固定から可変への変更
それでは、上記に沿って解説していきます。
Stable Diffusion XL Inpaintingとは?
Stable Diffusion XL Inpaintingとは、SDXL 1.0ベースのInpaintingのことです。
ここでは、SDXL 1.0ベースのInpainting用モデルのことを指します。
Inpainting用モデルでなくても、Inpaintingは実行可能です。
しかし、その結果は次のように残念なモノとなります。

かなり下手な合成になってしまいます。
それに対して、Inpainting用モデルを利用すると自然な合成となります。

SDXL 1.0ベースになって、その合成スキルがさらにUPしています。
SD 1.5ベースのInpaintingよりも、さらに使えるInpaintingになっています。
そんなワクワクするSDXL 1.0ベースのInpainting用モデルは、まだ利用できる環境が限られています。
現時点(2023年9月22日)では、diffusersとComfyUIだけです。
diffusers版のInpaintingモデルは、2023年9月初旬にリリースされています。
https://huggingface.co/diffusers/stable-diffusion-xl-1.0-inpainting-0.1
ComfyUI版のInpaintingモデルは、2023年9月16日にリリース済です。
https://civitai.com/models/146028/sdxl-inpainting-01-official-reupload
しかし、AUTOMATIC1111版web UIではまだ利用できません。
webUIとInpaintingなんて、ゴールデンコンビなんですけどね。
個人的には、diffusers版のリリース時点でwebUI版もそのうちリリースされるだろうと思っていました。
でも、9月末になってもまだリリースされていません。
そうは言っても、2023年9月(遅くても10月)中にはwebUI版もリリースされるとは思いますけどね・・・
それまでは、次のデモページを利用するという選択肢があります。
(※ComfyUIは最初から対象外とします)

と言っても、現実的には無理があります。
共有ページであるため、混雑するとまともには使えません。
そこで、このデモページ(ツール)をローカルマシンに導入してやろうということです。
web UI版のInpainting用モデルがリリースされたら、このツールはお役御免になるかもしれません。
しかし、処理速度の比較結果次第ではInpainting専用ツールとして生き残る可能性があります。
そのような可能性もあり、デモページのローカルマシンへの導入は意味があると言えます。
以上、Stable Diffusion XL Inpaintingについて説明しました。
次は、Stable Diffusion XL Inpaintingツールの導入方法を説明します。
Stable Diffusion XL Inpaintingツールの導入方法
Stable Diffusion XL Inpaintingツールのインストールには、Python仮想環境の利用をオススメします。

検証は、次のバージョンのPythonで行っています。
> python -V Python 3.10.4
インストールを始める前に、次のおまじないを唱えておきましょう。
python.exe -m pip install --upgrade pip setuptools
では、Stable Diffusion XL Inpaintingツールのインストールを始めていきます。
まずは、ファイル一式をダウンロードしましょう。
デモページにアクセスして、「Clone repository」を選択します。
そうすると、次のポッポアップが表示されます。
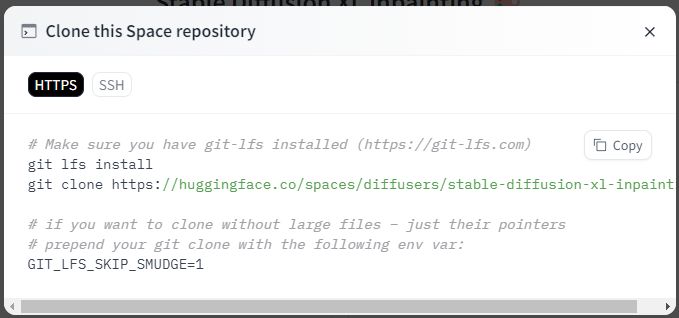
「git clone」のコマンドをコピーして、実行します。
ダウンロードできたら、リポジトリルートに移動しておきます。
git clone https://huggingface.co/spaces/diffusers/stable-diffusion-xl-inpainting cd stable-diffusion-xl-inpainting
リポジトリルートには、requirements.txtが設置されています。
このファイルの最終行に「gradio」を追加します。
requirements.txt
--extra-index-url https://download.pytorch.org/whl/cu118 torch git+https://github.com/huggingface/diffusers.git transformers accelerate ftfy numpy matplotlib uuid opencv-python gradio
追記すると、requirements.txtの内容は上記のようになります。
CUDA 11.8以外であれば、それに合わせてPyTorchのインストール部分を書き換えます。
ファイルの内容に問題なければ、次のコマンドを実行します。
pip install -r requirements.txt
ライブラリがインストールされたら、Stable Diffusion XL Inpaintingツールのインストールは完了です。
以上、Stable Diffusion XL Inpaintingツールのインストールを説明しました。
次は、Stable Diffusion XL Inpaintingツールの動作確認を説明します。
Stable Diffusion XL Inpaintingツールの動作確認
Stable Diffusion XL Inpaintingツールの動作確認を行います。
リポジトリルートにあるapp.pyを起動します。
python app.py
初回実行時(モデルが存在しない場合)は、必要モデルのダウンロードが実施されます。
その場合は、ダウンロードが終わるまで待ちましょう。
ツールの起動自体は、次の表示で確認できます。
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
上記を確認できたら、そのURLにアクセスします。
アクセスすると、次のような画面を確認できます。
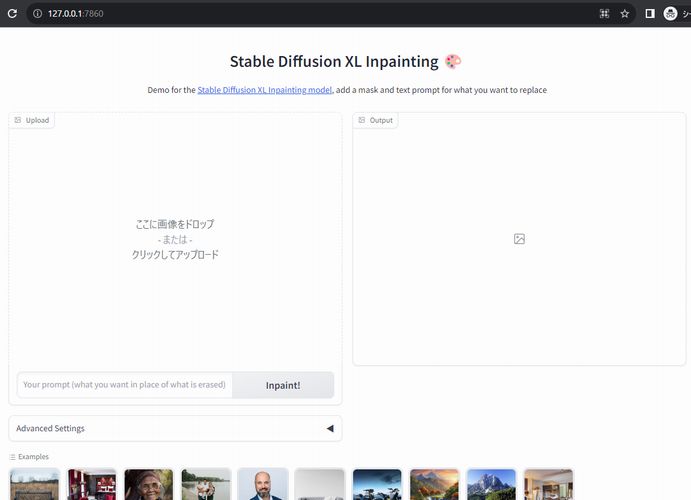
Hugging Face上のデモ画面と全く同じです。
あとは、同じように利用することができます。
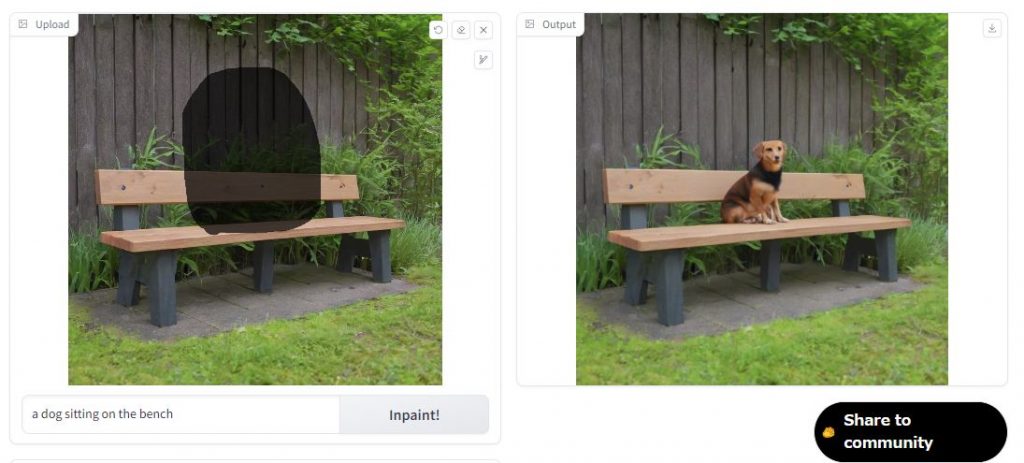
言っても所詮は、デモツールです。
そのため、足りない機能はたくさんあります。
LoRAの適用、SEEDの設定なども機能としては欲しいところです。
でも、画像サイズが固定されているのはちょっと不便過ぎます。
出力される画像が、1024 x 1024でサイズ固定となっています。
そのため、アスペクト比が元画像とは異なってしまいます。
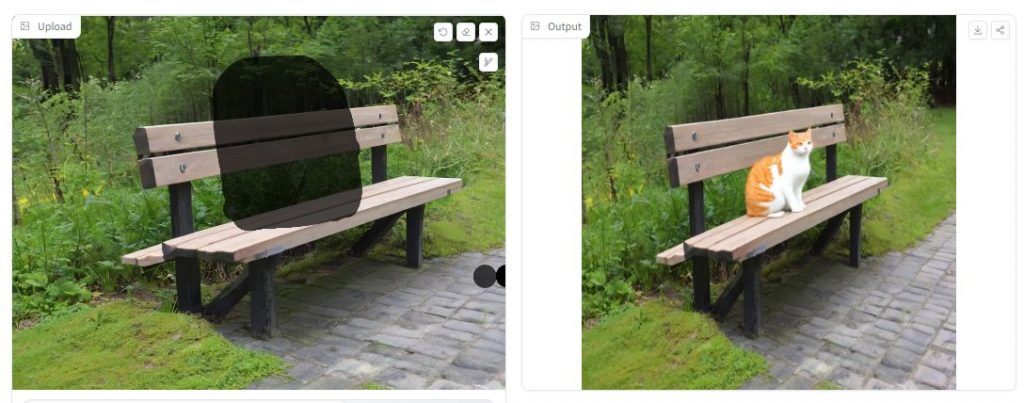
これでは、さすがに使い物にはなりません。
ということで、出力画像サイズの固定から可変への変更を行います。
以上、Stable Diffusion XL Inpaintingツールの動作確認を説明しました。
最後は、出力画像サイズの固定から可変への変更を説明します。
出力画像サイズの固定から可変への変更
app.pyを修正します。
修正前に app.pyのバックアップを取ることをオススメします。
修正内容は、以下となります。
- インポート文の追加
- crop_black_border関数の追加
- predict関数の変更
それぞれを以下で説明します。
インポート文の追加
コードの先頭付近に追加します。
from PIL import Image, ImageChops, ImageOps
おそらく、ライブラリは自動的にインストールされているはずです。
ライブラリが存在しない場合は、インストールしましょう。
crop_black_border関数の追加
新規に追加します。
場所は、predict関数の手前でよいでしょう。
def crop_black_border(image):
"""Crop the black border from the image."""
bg = Image.new(image.mode, image.size, image.getpixel((0, 0)))
diff = ImageChops.difference(image, bg)
diff = ImageChops.add(diff, diff, 2.0, -100)
bbox = diff.getbbox()
return image.crop(bbox)
predict関数の変更
既存のpredict関数を丸ごと以下のコードに置き換えます。
def predict(dict, prompt="", negative_prompt="", guidance_scale=7.5, steps=20, strength=1.0, scheduler="EulerDiscreteScheduler"):
if negative_prompt == "":
negative_prompt = None
scheduler_class_name = scheduler.split("-")[0]
add_kwargs = {}
if len(scheduler.split("-")) > 1:
add_kwargs["use_karras"] = True
if len(scheduler.split("-")) > 2:
add_kwargs["algorithm_type"] = "sde-dpmsolver++"
scheduler = getattr(diffusers, scheduler_class_name)
pipe.scheduler = scheduler.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", subfolder="scheduler",
**add_kwargs)
original_size = dict["image"].size
aspect_ratio = original_size[0] / original_size[1]
if aspect_ratio > 1:
new_size = (1024, int(1024 / aspect_ratio))
else:
new_size = (int(1024 * aspect_ratio), 1024)
init_image = dict["image"].convert("RGB").resize(new_size, Image.BILINEAR)
mask = dict["mask"].convert("RGB").resize(new_size, Image.BILINEAR)
delta_w = 1024 - new_size[0]
delta_h = 1024 - new_size[1]
padding = (delta_w // 2, delta_h // 2, delta_w - (delta_w // 2), delta_h - (delta_h // 2))
init_image = ImageOps.expand(init_image, padding)
mask = ImageOps.expand(mask, padding)
output = pipe(prompt=prompt, negative_prompt=negative_prompt, image=init_image, mask_image=mask,
guidance_scale=guidance_scale, num_inference_steps=int(steps), strength=strength)
# Crop the black border from the output image
cropped_output = crop_black_border(output.images[0])
# Resize the cropped image to the original size
resized_output = cropped_output.resize(original_size)
return resized_output, gr.update(visible=True)
この変更により、次のようにアスペクト比が維持されるようになります。
維持と言うか、アップロードした画像と同じサイズになるということです。
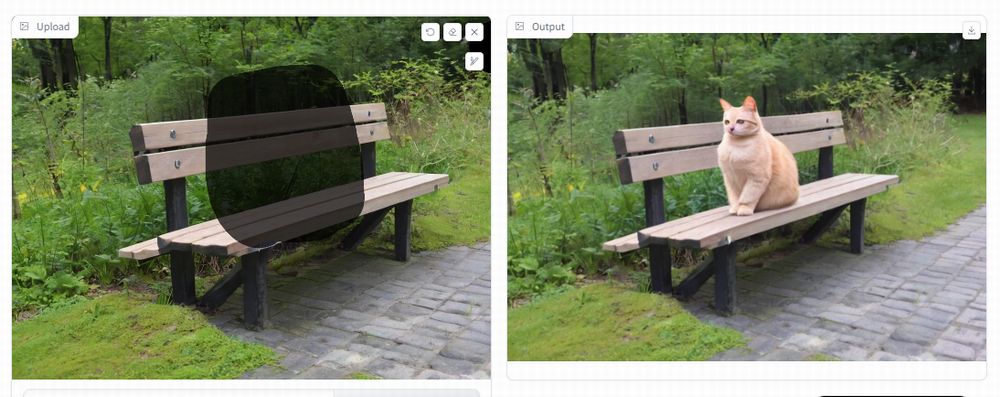
ただし、これはこれで注意が必要です。
アップロードする画像のサイズが大きいと、その分だけGPUメモリは食うでしょうね。
その辺りを意識して、アップロードする画像のサイズには注意しましょう。
以上、出力画像サイズの固定から可変への変更を説明しました。

