「検索エンジンの検索結果から画像を大量に取得したい」
「画像を一括でダウンロードしたい」
このような場合には、icrawlerがオススメです。
この記事では、画像の一括ダウンロードができるicrawlerについて解説しています。
本記事の内容
- icrawlerとは?
- icrawlerのシステム要件
- icrawlerのインストール
- icrawlerの動作確認
それでは、上記に沿って解説していきます。
icrawlerとは?
icrawlerとは、Webクローラのミニフレームワークです。
Scrapyの軽量版と言えます。
そして、icrawlerは以下の検索エンジンに対応しています。
- Bing
- Baidu
これらの検索エンジンでの検索結果をクローリングすることができます。
つまり、検索エンジンの検索結果をスクレイピングできるということです。
検索エンジンを対象にする以外では、以下のサイト・方法でクローリングが可能になります。
- Flickr
- General greedy crawl(ウェブサイトからの画像収集)
- UrlList(urlリストで指定されたすべての画像の取得)
icrawlerは、基本的には画像収集で利用されることが多いです。
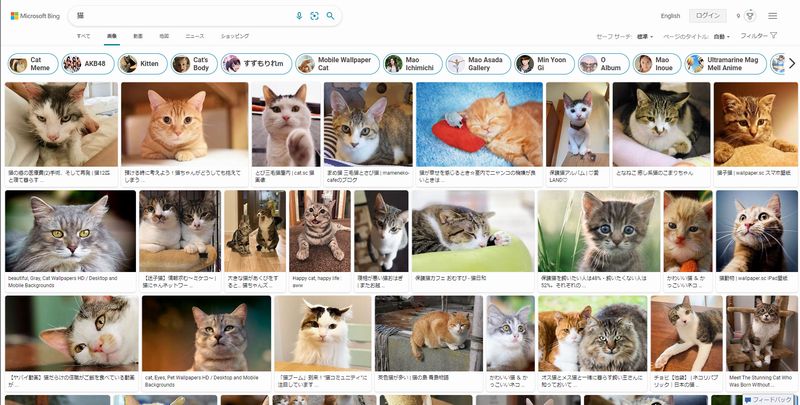
例えば、「猫」の画像をたくさん必要となった場合にBingで検索したとします。
icrawlerを用いれば、これらの画像を一気に取得することが可能になります。
なお、icrawlerは動画やテキストなども取得することが可能です。
以上、icrawlerについて説明しました。
次は、icrawlerのシステム要件を説明します。
icrawlerのシステム要件
現時点(2022年7月末)でのicrawlerの最新バージョンは、0.6.6となります。
この最新バージョンは、2021年8月14日にリリースされています。
サポートOSに関しては、以下を含むクロスプラットフォーム対応です。
- Windows
- macOS
- Linux
サポート対象となるPythonのバージョンは、以下となっています。
- Python 2.7
- Python 3.5
- Python 3.6
- Python 3.7
メンテナンスが行き届いていないように感じます。
基本的には、以下のPython公式開発サイクルに準拠していることが望ましいです。
| バージョン | リリース日 | サポート期限 |
| 3.6 | 2016年12月23日 | 2021年12月23日 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
Python3.7で動けば、それ以降でも問題はないとは思います。
実際、Python 3.10でも機能していますからね。
以上、icrawlerのシステム要件を説明しました。
次は、icrawlerのインストールを説明します。
icrawlerのインストール
検証は、次のバージョンのPythonで行います。
$ python -V Python 3.10.2
まずは、現状のインストール済みパッケージを確認しておきます。
$ pip list Package Version ---------- ------- pip 22.2 setuptools 63.2.0 wheel 0.36.2
次にするべきことは、pipとsetuptoolsの更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip setuptools
では、icrawlerのインストールです。
icrawlerのインストールは、以下のコマンドとなります。
pip install icrawler
icrawlerのインストールには、少し時間がかかります。
終了したら、どんなパッケージがインストールされたのかを確認します。
$ pip list Package Version ------------------ ----------- beautifulsoup4 4.11.1 certifi 2022.6.15 charset-normalizer 2.1.0 icrawler 0.6.6 idna 3.3 lxml 4.9.1 Pillow 9.2.0 pip 22.2 requests 2.28.1 setuptools 63.2.0 six 1.16.0 soupsieve 2.3.2.post1 urllib3 1.26.11 wheel 0.36.2
icrawlerは、そこそこの数のパッケージに依存しています。
それも、知名度のあるパッケージが多い印象です。
以上、icrawlerのインストールを説明しました。
次は、icrawlerの動作確認を説明します。
icrawlerの動作確認
icrawlerの動作確認を行います。
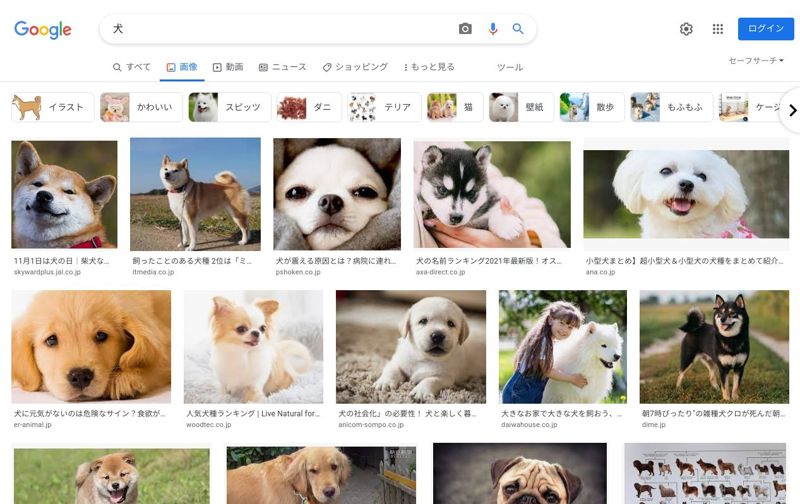
icrawlerを用いて、Googleの検索結果から画像を取得してみましょう。
用いるコードは、以下。
from icrawler.builtin import GoogleImageCrawler
google_crawler = GoogleImageCrawler(storage={'root_dir': 'result'})
google_crawler.crawl(keyword='犬', max_num=100)
コードの内容は、「犬」の検索結果から最大で100個の画像を取得します。
ただし、実際に100個取得できるわけではありません。
上記コードを実行した結果は、以下のように表示されます。
2022-07-27 20:42:54,502 - INFO - icrawler.crawler - start crawling... 2022-07-27 20:42:54,502 - INFO - icrawler.crawler - starting 1 feeder threads... 2022-07-27 20:42:54,502 - INFO - feeder - thread feeder-001 exit 2022-07-27 20:42:54,503 - INFO - icrawler.crawler - starting 1 parser threads... 2022-07-27 20:42:54,503 - INFO - icrawler.crawler - starting 1 downloader threads... 2022-07-27 20:42:59,504 - INFO - downloader - downloader-001 is waiting for new download tasks 2022-07-27 20:43:00,156 - INFO - parser - parsing result page https://www.google.com/search?q=%E7%8A%AC&ijn=0&start=0&tbs=&tbm=isch 2022-07-27 20:43:05,926 - INFO - downloader - image #1 https://skywardplus.jal.co.jp/wp-content/uploads/2020/07/shosai_dogday_main.jpg 2022-07-27 20:43:06,054 - INFO - downloader - image #2 https://image.itmedia.co.jp/business/articles/2204/17/l_mk_inu_000.jpg 2022-07-27 20:43:06,235 - INFO - downloader - image #3 https://pshoken.co.jp/uploads/2020/01/27/dog-symptom019a.jpg 〜 2022-07-27 20:43:23,252 - INFO - downloader - image #84 https://img.wanqol.com/2021/04/c351ea11-sigh_p01.jpg 2022-07-27 20:43:23,401 - INFO - downloader - image #85 https://www.aeonpet.com/assets/ap_special_detail/ap_special_detail-img-285.jpg 2022-07-27 20:43:23,571 - INFO - downloader - image #86 https://kahoku.news/images/2022/05/03/20220503khn000020/001_size3.jpg 2022-07-27 20:43:24,792 - INFO - parser - no more page urls for thread parser-001 to parse 2022-07-27 20:43:24,792 - INFO - parser - thread parser-001 exit 2022-07-27 20:43:28,572 - INFO - downloader - no more download task for thread downloader-001 2022-07-27 20:43:28,572 - INFO - downloader - thread downloader-001 exit 2022-07-27 20:43:29,540 - INFO - icrawler.crawler - Crawling task done!
結果的には、86個の画像を収集できています。
処理にかかった時間は、30秒ちょっとですね。
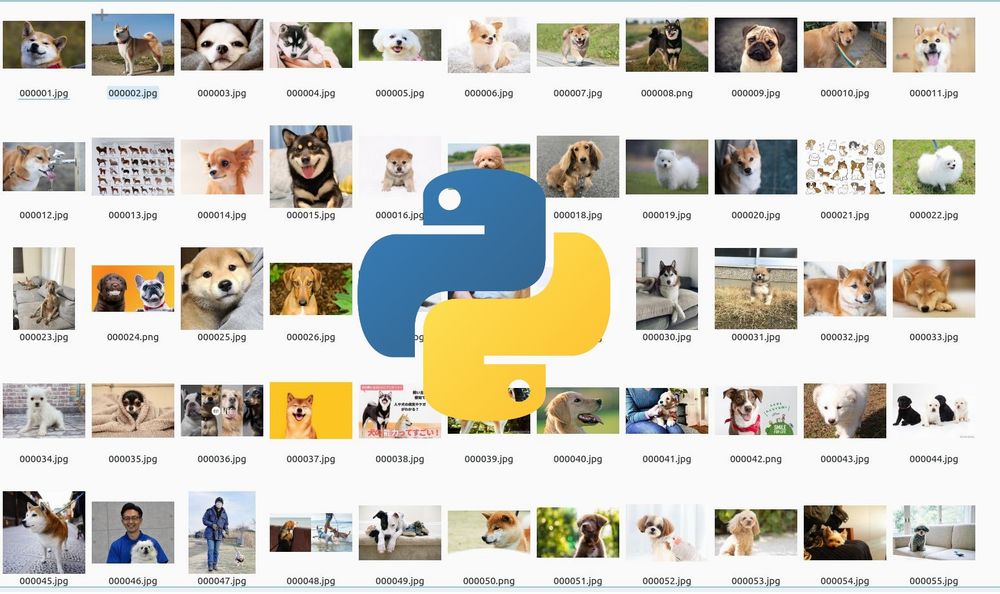
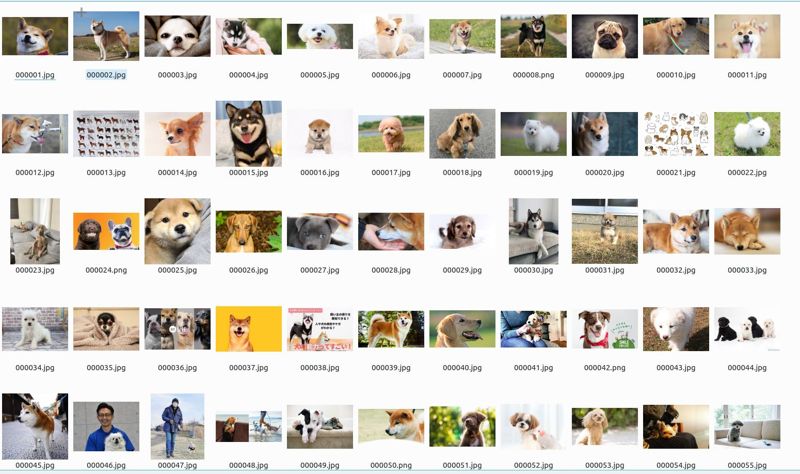
画像は、「result」ディレクトリに保存されています。
ディレクトリは自動的に作成されるため、予め作成する必要はありません。
「result」ディレクトリは、次のような状況です。
Googleで「犬」を検索した結果画面とほぼ同じモノを確認できます。
以上、icrawlerの動作確認を説明しました。

