「img2imgをGUIでサクサクと行いたい」
「AUTOMATIC1111ではなく、シンプルなツールを探している」
このような場合には、この記事の内容が参考になります。
この記事では、img2imgのGUIツールを導入する方法を解説しています。
本記事の内容
- img2imgのGUIツール
- img2img GUIツールのインストール
- img2img GUIツールの動作確認
それでは、上記に沿って解説していきます。
img2imgのGUIツール
img2imgとは、画像から画像を生成する機能を指します。
img2imgの詳細については、次の記事で説明しています。

上記記事では、GUIツールは関係ありません。
どちらかと言うと、img2imgに関するコードを説明しています。
バッチ処理で自動的に動かす場合には、それなりに参考にはなるでしょう。
しかし、img2imgを用いて試行錯誤を繰り返す場合には不向きです。
やはり、そのような場合にはGUIの画面で気軽に操作できる環境が必要となります。
今なら、AUTOMATIC1111が人気のGUIツールと言えます。
ただ、このAUTOMATIC1111はあまりに大きすぎます。
ここでは、気軽に修正できるツールを紹介します。
追記 2023年2月12日
下記URLは、もう消されたようです。
と言うより、私は完全に宗旨替えしました。
AUTOMATIC1111を気軽に利用できる方法を見つけました。
AUTOMATIC1111のimg2imgを利用することをオススメします。
Stable Diffusion Image to Image Pipeline CPU https://huggingface.co/spaces/Manjushri/SD-IMG2IMG-CPU
ただし、デモで動きは確認できない可能性が高いです。
GPU未使用のため、まともに動かないと思われます。
上記ツールは、img2imgに機能を絞っています。
そのため、コードも非常にシンプルです。
あと、CPU版と記載されていますが、GPUで動くように変更します。
CPUだけでimg2imgをするなんて、苦行でしかありません・・・
以上、img2imgのGUIツールについて説明しました。
次は、img2imgのGUIツールのインストールを説明します。
img2imgのGUIツールのインストール
Stable Diffusion Image to Image Pipeline CPUのファイル https://huggingface.co/spaces/Manjushri/SD-IMG2IMG-CPU/tree/main
ファイルは、たったこれだけです。
実質、「app.py」だけと言っても過言でありません。
ファイル数が多いと、次のようなツールで一括にファイルをダウンロードします。

しかし、今回は1ファイルで済みます。
そのため、手動で適当にダウンロードしましょう。
あと、インストールすべきモノがrequirements.txtに記載されています。
これについては、ダウンロードせずに自分で作成しましょう。
requirements.txt
diffusers ftfy scipy transformers torch
これは過不足があるので、次のように変更しましょう。
gradio accelerate diffusers ftfy scipy transformers
torchは、ここではインストール対象から外します。
なぜなら、PyTorchは事前にインストールしておくからです。

すでに述べたように、GPUでimg2imgのGUIツールを動かします。
そのため、GPU版のPyTorchをインストールする必要があるのです。
そして、それに伴ってaccelerateをインストールする必要が出てきます。
高速に処理を行う上では、accelerateは必要なパッケージです。
高速処理と言いつつ、Accelerateはあくまでどんな環境でも動くことを目指しているライブラリになります。

gradioについては、GUI画面を表示するために必要となります。
gradioについては、次の記事で解説しています。

では、PyTorchがインストール済みの状態で次のコマンドを実行します。
pip install requirements.txt
処理が完了すると、img2imgのGUIツールのインストールは完了です。
以上、img2img GUIツールのインストールを説明しました。
次は、img2img GUIツールの動作確認を説明します。
img2img GUIツールの動作確認
ダウンロードしたapp.pyを次のように変更します。
import gradio as gr
import torch
from PIL import Image
from diffusers import StableDiffusionImg2ImgPipeline
device = "cuda"
model_id = "runwayml/stable-diffusion-v1-5"
YOUR_TOKEN = "コピーしたアクセストークン"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id, use_auth_token=YOUR_TOKEN)
pipe.to(device)
def resize(value, img):
img = Image.open(img)
img = img.resize((value, value))
return img
def infer(source_img, prompt, guide, steps, seed, Strength):
generator = torch.Generator(device).manual_seed(seed)
source_image = resize(512, source_img)
source_image.save('source.png')
image = \
pipe([prompt], init_image=source_image, strength=Strength, guidance_scale=guide, num_inference_steps=steps).images[
0]
return image
gr.Interface(fn=infer, inputs=[gr.Image(source="upload", type="filepath", label="Raw Image"),
gr.Textbox(label='Prompt Input Text'),
gr.Slider(2, 15, value=7, label='Guidence Scale'),
gr.Slider(10, 50, value=25, step=1, label='Number of Iterations'),
gr.Slider(
label="Seed",
minimum=0,
maximum=2147483647,
step=1,
randomize=True),
gr.Slider(label='Strength', minimum=0, maximum=1, step=.05, value=.5)
], outputs='image', title="Stable Diffusion Image to Image Pipeline GPU",
description="Upload an Image (must be .PNG and 512x512-2048x2048) enter a Prompt, or let it just do its "
"Thing, then click submit. 10 Iterations takes about 300 seconds currently. For more "
"informationon about Stable Diffusion or Suggestions for prompts, keywords, artists or "
"styles see https://github.com/Maks-s/sd-akashic",
article="Code Monkey: <a href=\"https://huggingface.co/Manjushri\">Manjushri</a>").queue(
max_size=10).launch(enable_queue=True, debug=True)
主に次の修正を加えました。
- GPUへのデバイス変更
- 不要なパッケージの除去
- Stable Diffusion 1.5vへのモデル変更
- ファイル整形
Stable Diffusion 1.5vの利用方法は、次の記事で説明しています。
「”コピーしたアクセストークン”」については、記事内で言及しています。

app.pyを実行すると、コンソールに次のように表示されます。
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
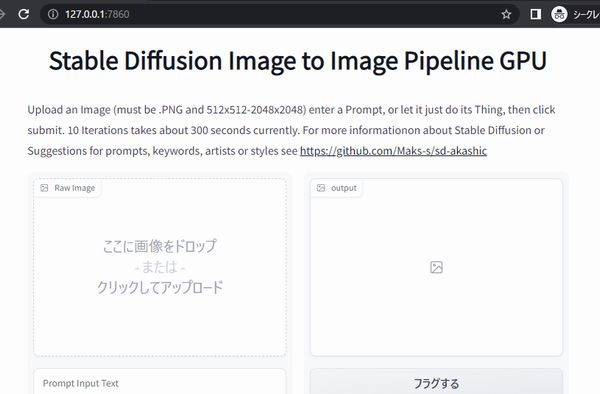
このように表示されたら、ブラウザで「http://127.0.0.1:7860」にアクセスします。
次の画面が表示されたら、起動は成功と言えます。
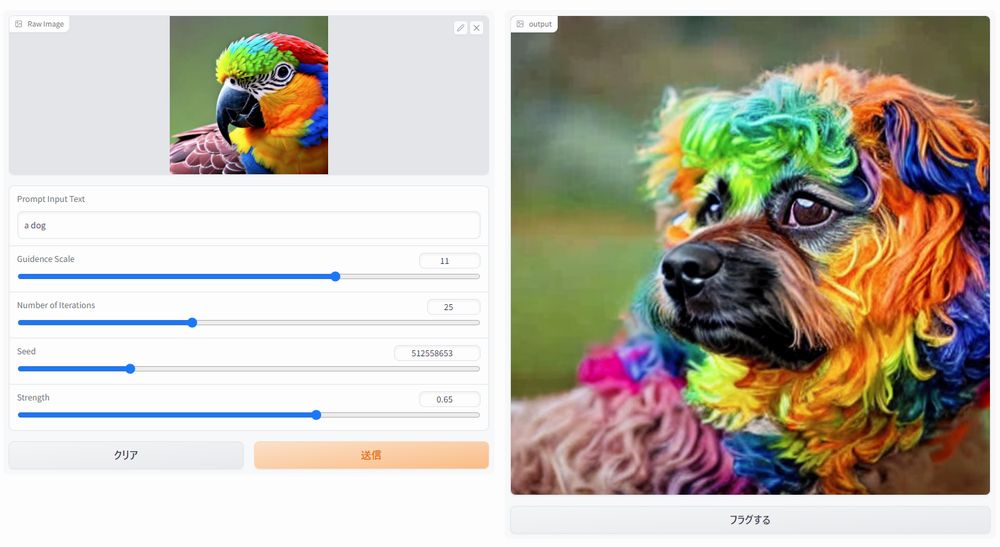
あとは、img2imgを好きなだけ試しましょう。

