
この記事では、エン転職(エン・ジャパン|en-japan)における募集内容をスクレイピングしていきます。
リクナビNEXTに続いて、転職サイトの第2弾というところです。
第1弾のリクナビNEXTは、以下の記事で解説しています。

上記記事でも書きましたが、AmazonやTwitterと比べれば需要はないでしょう。
でも、転職サイトのデータを残すことには価値があります。
価値があると主張する理由は、次の記事でまとめています。
簡単に言えば、ブラック企業の撲滅です。

本記事では、エン転職のメインページとなる募集ページをスクレイピングしていきます。
本記事の内容
- エン転職の求人募集ページをスクレイピングする
- エン転職の求人募集ページをスクレイピングするサンプルコード
上記に沿って解説を進めていきます。
エン転職の求人募集ページをスクレイピングする
ここでは仕様的な話がメインとなります。
まず、エン転職の求人募集ページには、以下の2種類があります。
- 正規の掲載
- engageからの掲載
正規の掲載
エン転職に広告料を払って、掲載するパターンです。
通常、みなさんがイメージするのはこのパターンになるでしょう。
正規の掲載の場合、求人募集ページのURLは以下となります。
https://employment.en-japan.com/desc_1027990/
基本的には、こちらのページがメインです。
両パターンをスクレイピングしますが、必要な情報はこちらのパターンにあります。
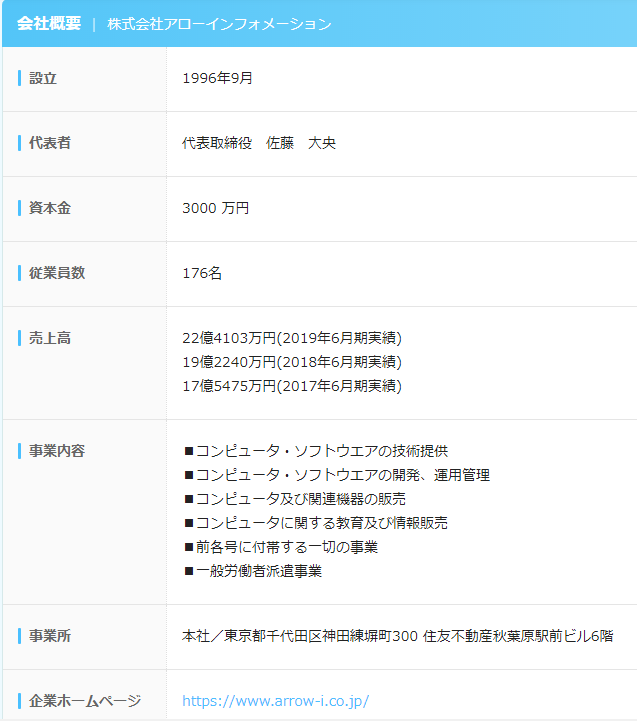
資本金・売上高・従業員数という情報が、必要な情報です。
正規の掲載のみ、これらの必要な情報が掲載されているのです。
engageからの掲載
エン転職が提供する「engage」に登録した情報が掲載されるパターンです。
https://en-gage.net/
0円から使えるengageなら、基本機能の利用に 「初期費用」「月額費用」「成功報酬費用」は一切かかりません。
このようにアピールしています。
エン転職のサイト以外では、以下のサービスにも掲載が可能のようです。
- Indeed
- LINEキャリア
- Google しごと検索
- Yahoo!しごと検索
- 求人ボックス
なお、基本機能とは次のモノということです。
- 応募者の選考管理
- チャットでの面接設定サービス
- 連携サービス
- 録画面接ツール「VideoInterview(ビデオインタビュー)」
- オンライン適性テスト「TalentAnalytics(タレントアナリティクス)」
- 入社者の活躍支援ツール「HR OnBoard(エイチアールオンボード)」
- 複数のengageアカウントの利用
- 求人広告メディア・人材紹介会社経由の応募者等を一元管理できる「Hirehub(ハイヤーハブ)」
他社サービスとの協力ではなく、すべて自社サービスみたいです。
engageからの掲載の場合、求人募集ページのURLは以下となります。
https://employment.en-japan.com/desc_eng_272023/
「desc_eng_272023」に注目してください。
descと272023の間に「eng」とあります。
おそらく、engageの略でしょう。
engageからの掲載の場合、会社に関する情報は以下だけです。
資本金・売上高・従業員数の表示がありません。

このパターンの求人募集ページは、一応スクレイピングしておきます。
ただ、この会社情報部分はjsで動的に表示しています。
この部分では、画像や動画を表示できるため、その対応として動的コンテンツなのでしょう。
しかし、それは価値のない情報です。
価値のない情報のため動的コンテンツ対応をするのも勿体ないです。
だから、静的コンテンツのみを取得するようにします。
エン転職の求人募集ページをスクレイピングするサンプルコード
コピペで動くはずです。
ただし、必要なライブラリがインストールされていることは前提です。
2020年08月16日時点ではバリバリ動いています。
import requests
import re
from bs4 import BeautifulSoup
# User-Agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"
# 募集概要マスター
def get_master_offer():
d = {}
d["job"] = "仕事内容"
d["capacity"] = "応募資格"
d["backbone"] = "募集背景"
d["user"] = "雇用形態"
d["area"] = "勤務地・交通"
d["time"] = "勤務時間"
d["money"] = "給与"
d["vacation"] = "休日休暇"
d["benefit"] = "福利厚生・待遇"
return d
# 会社概要マスター
def get_master_company_info():
d = {}
d["company_name"] = "会社名"
d["date"] = "設立"
d["representative"] = "代表者"
d["capital"] = "資本金"
d["employees"] = "従業員数"
d["sales"] = "売上高"
d["business"] = "事業内容"
d["office"] = "事業所"
d["web"] = "企業ホームページ"
return d
def get_text_by_elem(elem):
try:
text = elem.text
text = text.strip()
return text
except Exception as e:
return None
def get_html(url, params=None, headers=None):
try:
# データ取得
resp = requests.get(url, params=params, headers=headers)
resp.encoding = 'utf8' # 文字コード
# 要素の抽出
soup = BeautifulSoup(resp.text, "html.parser")
return soup
except Exception as e:
return None
def get_key_from_value(d, val):
keys = [k for k, v in d.items() if v == val]
if keys:
return keys[0]
return None
def extract_date(s):
date_pattern = re.compile('(\d{4})/(\d{1,2})/(\d{1,2})')
result = date_pattern.search(s)
if result:
y, m, d = result.groups()
return str(y) + str(m.zfill(2)) + str(d.zfill(2))
else:
return None
def get_check_key(d, val):
if val in d:
return val
return None
def get_page_info(url, company_info, offer):
# 結果
result = {}
l_tmp = url.split('/')
page_code = l_tmp[3]
l_tmp_code = page_code.split('_')
page_flg = ""
if len(l_tmp_code)==2:
offer_id = l_tmp_code[1]
else:
page_flg = "eng"
offer_id = l_tmp_code[2]
result["offer_id"] = offer_id
# データ取得
params = {}
headers = {"User-Agent": user_agent}
soup = get_html(url, params, headers)
if soup != None:
try:
# タイトル
title = ""
company_id = ""
if page_flg=="eng":
title_elem = soup.find(class_="fixHeightChildCatch")
else:
title_elem = soup.find(class_="nameSet")
company_id_elem = soup.find(class_="companyName").find("a")
if company_id_elem:
company_id = company_id_elem["href"]
company_id = re.sub(r"\D", "", company_id)
if title_elem:
title = get_text_by_elem(title_elem)
result["title"] = title
result["company_id"] = company_id
# 会社名
company_name_elem = soup.find(class_="company")
result["company_name"] = get_text_by_elem(company_name_elem)
# 期間
period = ""
period_elems = soup.find(class_="publish").find_all("span")
if period_elems:
if len(period_elems)==4:
period_start = extract_date("20" + get_text_by_elem(period_elems[1]))
period_end = extract_date("20" + get_text_by_elem(period_elems[3]))
else:
period_start = extract_date("20" + get_text_by_elem(period_elems[1]))
period_end = ""
result["period"] = period
result["period_start"] = period_start
result["period_end"] = period_end
if not page_flg=="eng":
elems_company_info = soup.find(class_="dataCompanyInfoSummary").find_all("tr")
for elem_company_info in elems_company_info:
elem_item = elem_company_info.find(class_="item")
elem_data = elem_company_info.find(class_="data")
heading = elem_item.text
text = elem_data.text
key = get_key_from_value(company_info, heading)
if key:
result[key] = text
# 募集概要
elems_offer_info = soup.find(class_="dataWork").find_all("tr")
for elem_offer_info in elems_offer_info:
elem_item = elem_offer_info.find(class_="item")
elem_data = elem_offer_info.find(class_="data")
heading = elem_item["class"][2]
text = elem_data.text
key = get_check_key(offer, heading)
if key:
result[key] = text
except Exception as e:
return None
else:
print("エラー")
return result
if __name__ == '__main__':
# 募集概要マスタ取得
d_offer = get_master_offer()
# 会社概要マスタ取得
d_company_info = get_master_company_info()
page_url = 'https://employment.en-japan.com/desc_1027990/'
#page_url = 'https://employment.en-japan.com/desc_eng_272023/'
page_info = get_page_info(page_url, d_company_info, d_offer)
print(page_info)
現状では、正規の掲載をスクレイピングするようになっています。
page_url = 'https://employment.en-japan.com/desc_1027990/'
#page_url = 'https://employment.en-japan.com/desc_eng_272023/'
なお、正規の掲載のみ掲載期間が決まっています。
「掲載期間20/08/13~20/10/07」
このように終了日があるということです。
逆に、engageからの掲載の場合は、掲載期間が決まっていません。
「掲載期間 20/08/14 ~」
このように終了日がありません。
理屈上は、無料だから永遠に掲載できるということですね。

