「すでにある画像をベースにして画像生成を行いたい」
「IP-Adapterがインストールできない・・・」
このような場合には、この記事の内容が参考になります。
この記事では、IP-Adapterについて解説しています。
本記事の内容
- IP-Adapterとは?
- IP-Adapterのインストール
- IP-Adapterの動作確認
それでは、上記に沿って解説していきます。
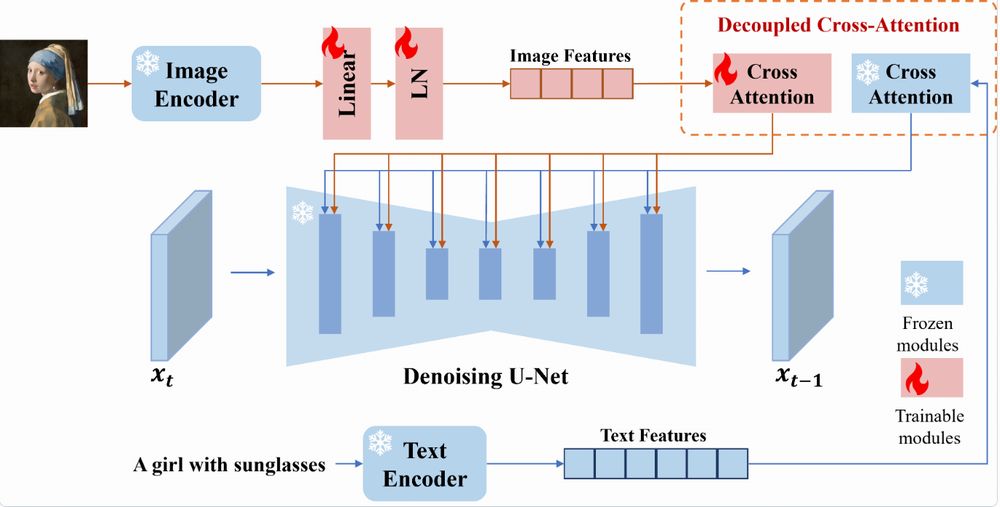
IP-Adapterとは?
IP-Adapterとは、画像生成AIの補助ツールになります。
画像生成自体は、Stable Diffusionで行います。
その際、テキストだけでは伝える情報として限界があります。
例えば、「犬が街の中を歩いている」をプロンプトにするとします。
この場合、あなたのイメージする犬があるはずです。
それを言葉で表現して、さらに英語に変換する必要があります。
そうなってくると、なかなか自分のイメージを伝え切ることはできません。
そんな中で、次のような画像をヒントに渡せればどうでしょうか?

そして、プロンプトは以下を入力するだけです。
walk, in the city
その結果、次のような画像が生成されるようになります。

ヒントとして渡した画像の犬が街を歩いています。
この画像は、実際にIP-Adapterを用いて生成した画像です。
他にも、二つの画像を用いて以下のようなことが可能となります。

共通しているのは、テキストではなく画像を主な入力データとして用いるところになりますね。
そして、ControlNetも利用可能となっています。
また、以下の両方をサポートしています。
- SD 1.5
- SDXL 1.0
SDXL 1.0に対応しているのは、大きいポイントになります。
どうしても世間の注目は、SDXLに向かっていますからね。
以上、IP-Adapterについて説明しました。
次は、IP-Adapterのインストールを説明します。
IP-Adapterのインストール
追記 2023年9月11日
web UIでもIP-Adapterを利用できます。

IP-Adapterのインストールについて説明していきます。
インストールは、Python仮想環境を利用しましょう。

検証は、次のバージョンのPythonで行います。
> python -V Python 3.10.4
まずは、IP-Adapterをダウンロードします。
git clone https://github.com/tencent-ailab/IP-Adapter.git cd IP-Adapter
そして、リポジトリルートに移動しましょう。
通常であれば、ここにrequirements.txtかenvironment.yamlを確認できます。
しかし、IP-Adapterにはそのようなファイルが存在していません。
ということで、コードをもとに必要なモノを導き出します。
- PyTorch
- Diffusers
- Transformers
- Accelerate
とりあえず、上記があれば今回の動作確認は可能です。
Accelerateはなくても動きますが、処理時間を劇的に短縮してくれます。




すべて最新版をインストールしておきます。
python -m pip install --upgrade pip setuptools pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 pip install diffusers pip install transformers pip install accelerate
Diffusersは、0.19.3以降である必要があります。
でも、最新版を入れておけば問題ありません。
あと、モデルをダウンロードしないといけません。
ここで言うモデルは、IP-Adapter用のモデルです。
そのモデルは、以下のページからダウンロードできます。

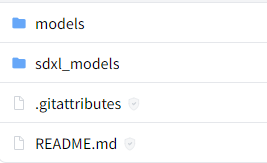
「models」は、SD 1.5用です。
「sdxl_models」は、SDXL 1.0用になります。
とりあえず、両方ダウンロードしておきましょう。
手動で落としても良いですが、gitコマンドを使えば簡単にダウンロードできます。
git clone https://huggingface.co/h94/IP-Adapter
ダウンロードできたら、リポジトリルート直下に保存します。
以上、IP-Adapterのインストールを説明しました。
次は、IP-Adapterの動作確認を説明します。
IP-Adapterの動作確認
デモプログラムは、Jupyter Notebookファイルで用意されています。
上記ファイルをそのまま起動させたい場合は、以下を利用しましょう。

面倒だなという方は、以下のファイルをリポジトリルートに保存しましょう。
ip_adapter_multimodal_prompts_demo.ipynbを参考に作成しています。
test_sd15.py
import torch
from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline, StableDiffusionInpaintPipelineLegacy, DDIMScheduler, AutoencoderKL
from PIL import Image
from ip_adapter import IPAdapter
base_model_path = "runwayml/stable-diffusion-v1-5"
vae_model_path = "stabilityai/sd-vae-ft-mse"
image_encoder_path = "models/image_encoder/"
ip_ckpt = "models/ip-adapter_sd15.bin"
device = "cuda"
noise_scheduler = DDIMScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
steps_offset=1,
)
vae = AutoencoderKL.from_pretrained(vae_model_path).to(dtype=torch.float16)
# load SD pipeline
pipe = StableDiffusionPipeline.from_pretrained(
base_model_path,
torch_dtype=torch.float16,
scheduler=noise_scheduler,
vae=vae,
feature_extractor=None,
safety_checker=None
)
# read image prompt
image = Image.open("assets/images/woman.png")
resize_image = image.resize((256, 256))
# load ip-adapter
ip_model = IPAdapter(pipe, image_encoder_path, ip_ckpt, device)
# generate image variations
generate_image = ip_model.generate(pil_image=image,
num_samples=1,
num_inference_steps=50,
seed=1000,
prompt="best quality, high quality, wearing a cap on the beach",
scale=0.6
)
generate_image[0].save("generate_image.png")
上記を実行すれば、generate_image.pngがリポジトリルートに作成されます。
以下の画像では、左がwoman.pngで右がgenerate_image.pngになります。

ただ、実はなかなか上手くキャップを表現できませんでした。
scaleやseedを調整して、上手く出せたモノを選んでいます。
それでも、ビーチを表現できていません。
同じことをSDXL 1.0ベースのモデルで行ってみましょう。
test_sdxl10.py
import torch
from diffusers import StableDiffusionXLPipeline
from PIL import Image
from ip_adapter import IPAdapterXL
base_model_path = "stabilityai/stable-diffusion-xl-base-1.0"
image_encoder_path = "sdxl_models/image_encoder"
ip_ckpt = "sdxl_models/ip-adapter_sdxl.bin"
device = "cuda"
# load SDXL pipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
base_model_path,
torch_dtype=torch.float16,
add_watermarker=False
)
# load ip-adapter
ip_model = IPAdapterXL(pipe, image_encoder_path, ip_ckpt, device)
# read image prompt
image = Image.open("assets/images/woman.png")
resize_image = image.resize((512, 512))
resize_image.save("resize_image.png")
# generate image variations with only image prompt
num_samples = 1
images = ip_model.generate(pil_image=resize_image,
num_samples=num_samples,
num_inference_steps=50,
seed=45,
prompt="best quality, high quality, wearing a cap on the beach",
scale=0.6
)
images[0].save("generate_image.png")
SDXL 1.0の場合だと、ほぼ100%でキャップ(みたいなモノ)は被ってくれます。
そして、ビーチもちゃんと表現しています。

こうやって比較してみると、SDXL 1.0の性能の高さを感じますね。
SDXLと言えば、画質が良いことばかりに目が行きがちになります。
でも、プロンプト(今回は画像も)の解釈や表現に関してもSDXLはレベルが高いですね。
あと、SD 1.5・SDXL 1.0のどちらにおいても他のカスタムモデルを利用できます。
以下は、SDXL 1.0用のモデルで生成した画像になります。

左から、次のモデルを利用しています。
- Copax TimeLessXL
- DynaVision XL
- NightVision XL
- Realities Edge XL
上記のモデルについては、以下の記事で説明しています。




以上、IP-Adapterの動作確認を説明しました。

