
「文章からキーワードを抽出したい」
キーワードは、文章におけるキーとなるワードのことです。
つまり、その文章を表す用語のことですね。
このことが実現できれば、文章の要約が簡単になります。
さらには、文章のカテゴリー分けも可能となるでしょう。
TermExtractを使えば、Pythonでこれらのことが可能です。
本記事の内容
- TermExtractとは?
- TermExtractのシステム要件
- TermExtractのインストール
- TermExtractの動作確認
それでは、上記に沿って解説していきます。
TermExtractとは?
TermExtractは、文章からキーワードを抽出するPythonモジュールです。
キーワードが判明すると、その文章がどんな内容なのかがわかります。
つまり、文章の自動要約が可能になると言えそうです。
これが可能であれば、文章のカテゴリー分けにも応用できるかもしれません。
また、TermExtractはもともとはPerlで開発されていました。
それをPythonでも動くようにしたモノが、Python3モジュールtermextractとなります。
なお、TermExtractには文章から単語を抽出する機能(分かち書き)はありません。
そのため、形態素解析器を別途インストールする必要があります。
単語を抽出したそれ以降は、TermExtractが単語の重要度を決定します。
その重要度の高いモノが、キーワードとなります。
以上、TermExtractについての説明でした。
次は、TermExtractのシステム要件を確認します。
TermExtractのシステム要件
現時点(2021年7月)でのTermExtractの最新バージョンは、0.12b0となります。
この最新バージョンは、2018年2月24日以降にリリースされています。
バージョン0.01のリリースが、2018年2月24日です。
それ以降のリリースに関しての情報が、見当たりませんでした。
そのため、2018年2月24日以降と表示しています。
pipで公開されていない以上、このあたりは適当なのでしょう。
こんな感じのTermExtractのシステム要件は、注意深く見ていかないといけません。
以下の3つがポイントになるでしょう。
- OS
- Pythonバージョン
- 形態素解析器
それぞれを以下で説明します。
OS
サポートOSに関しては、以下を含むクロスプラットフォーム対応でしょう。
あくまで推測です。
- Windows
- macOS
- Linux
公式サイトでは、以下のように記載されています。
Linux/Windows環境のいずれでも使えます。
Linuxで動けば、macOSでも動きます。
ソースを見る限り、macOSがアウトになる要素もありません。
Pythonバージョン
サポート対象となるPythonのバージョンについては・・・
情報が、ありません。
あるとすれば、公式にある以下の表示ぐらいです。
専門用語自動抽出Python3モジュール"termextract" 0.01をリリース!
Python 3系がOKということでしょうか。
実際、以下のバージョンで動くことは確認済みです。
>python -V Python 3.9.6
また、以下のPythonの公式開発サイクルも参考になります。
| バージョン | リリース日 | サポート期限 |
| 3.6 | 2016年12月23日 | 2021年12月 |
| 3.7 | 2018年6月27日 | 2023年6月 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
TermExtractのリリース日から推察すると、TermExtractはPython 3.6で開発されている可能性が高いです。
そうだとすると、Python 3.6以降であれば問題はないでしょう。
いずれにせよ、古いバージョンを使わない方がよいのは確かです。
形態素解析器
別途インストールが必要です。
日本語の形態素解析器では、以下の2つが候補になります。
- Mecab
- Janome
それぞれのインストール方法は、以下の記事で説明しています。

今回は、Janomeのインストールを前提で話を進めます。
Janomeは、pipだけで簡単にインストールができます。
以上、TermExtractのシステム要件についての説明でした。
次は、TermExtractのインストールしていきます。
TermExtractのインストール
TermExtractのインストールを行っていきます。
ただし、TermExtractはpipでインストールはできません。
と言っても、複雑なインストールではありません。
そうだと言っても、pipよりは手間になります。
- ダウンロード
- インストール
そこで、上記の手順毎に説明します。
ダウンロード
TermExtract公式
http://gensen.dl.itc.u-tokyo.ac.jp/pytermextract/
上記のページにアクセス。
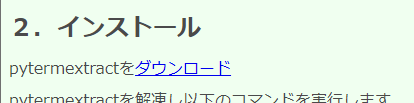
「ダウンロード」をクリックします。
クリックすると、ファイルのダウンロードが始まります。
ダウンロードが完了すると、「pytermextract-0_01.zip」が保存されています。
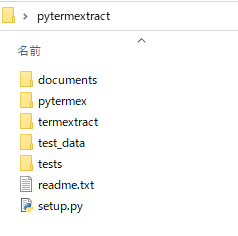
そして、このzipを解凍します。
「pytermextract-0_01」というフォルダが作成されます。
フォルダ名を「pytermextract」と変更します。
TermExtractのダウンロードに関しては、以上です。
インストール
まずは、現状のインストール済みパッケージを確認しておきます。
Janomeをインストール済みです。
>pip list Package Version ---------- ------- Janome 0.4.1 pip 21.1.3 setuptools 57.2.0
次にするべきことは、pipとsetuptoolsの更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip setuptools
では、TermExtractのインストールです。
ダウンロードして解凍したフォルダに移動。
そこで、以下のコマンドを実行します。
python setup.py install
インストールは、すぐに終わります。
では、どんなパッケージがインストールされたのかを確認しましょう。
>pip list Package Version ----------- ------- Janome 0.4.1 pip 21.1.3 setuptools 57.2.0 termextract 0.12b0
termextractパッケージが、インストールされています。
依存するパッケージはないようです。
以上、TermExtractのインストールについて説明しました。
次は、TermExtractの動作確認を行います。
TermExtractの動作確認
TermExtractの動作確認を行っていきます。
そのためのコードは、以下。
import termextract.janome
import termextract.core
from janome.tokenizer import Tokenizer
import collections
# ファイルパス
file_path = "pytermextract/test_data/jpn_sample.txt"
# 日本語テキストの読み込み
f = open(file_path, "r", encoding="utf-8")
text = f.read()
f.close
# 形態素解析器で日本語処理
t = Tokenizer()
tokenize_text = t.tokenize(text)
# Frequency生成=複合語抽出処理(ディクショナリとリストの両方可)
frequency = termextract.janome.cmp_noun_dict(tokenize_text)
# FrequencyからLRを生成する
lr = termextract.core.score_lr(
frequency,
ignore_words=termextract.mecab.IGNORE_WORDS,
lr_mode=1, average_rate=1)
# FrequencyとLRを組み合わせFLRの重要度を出す
term_imp = termextract.core.term_importance(frequency, lr)
# collectionsを使って重要度が高い順に表示
data_collection = collections.Counter(term_imp)
for cmp_noun, value in data_collection.most_common():
print(termextract.core.modify_agglutinative_lang(cmp_noun), value, sep="\t")
読み込むファイルは、解凍したフォルダの中にあります。
# ファイルパス file_path = "pytermextract/test_data/jpn_sample.txt"
上記コードの実行結果は、以下となります。
多すぎるので、上位10個をピックアップ。
人工知能 477.401125619928 AI 117.77945491468365 知能 108.83014288330233 人間 32.526911934581186 研究 23.237900077244504 システム 22.360679774997898 計算知能 19.934680700343144 エキスパートシステム 16.548754598234364 人工知能学会 13.456666729201407 手法 12.727922061357857
「人口知能」がもっとも重要なキーワードだと判定したようです。
正解と言えば、正解になります。
読み込んでいるファイルが、Wikipediaにおける「人口知能」の内容だからです。
以上、TermExtractの動作確認を説明しました。

