
「Pythonでボーカル抽出を行いたい」
「Spleeterの代わりとなるライブラリを探している」
「機械学習による音源分離を試したい」
このような場合には、Open-Unmixがおススメです。
本記事の内容
- Open-Unmixとは?
- Open-Unmixのシステム要件
- Open-Unmixのインストール
- Open-Unmixの学習済みモデル
- Open-Unmixの動作確認
それでは、上記に沿って解説していきましょう。
Open-Unmixとは?
Open-Unmixは、PyTorchをベースにした音楽ソース分離ライブラリです。
機能としては、音楽を次の4つの音源に分類します。
- ボーカル
- ドラム
- ベース
- その他
つまり、Open-Unmixはボーカル抽出のために利用できるということです。
では、その品質はどうかとなります。
実際にOpen-Unmixでボーカル抽出したボーカル音源を確認しましょう。
結構高いレベルでボーカル抽出ができています。
高いレベルとは、Spleeterと比較した結果を述べています。

Spleeterと同じか、それ以上かというレベルですね。
とにかく、選択肢が増えることは良いことです。
PyTorchで動くことより、モデル自体を自分で作成できます。
そうは言っても、結局データセットをどうするのかが問題ですけどね。
以上、Open-Unmixについての説明でした。
次は、Open-Unmixのシステム要件を確認します。
Open-Unmixのシステム要件
現時点(2021年10月)でのOpen-Unmixの最新バージョンは、1.2.1となります。
この最新バージョンは、2021年7月23日にリリースされています。
Open-Unmixのシステム要件を以下に分けて確認します。
※Windowsを対象としています
- OS
- Python
- PyTorch
- PySoundFile
OS
サポートOSに関しては、以下を含むクロスプラットフォーム対応です。
- Windows
- macOS
- Linux
Python
サポート対象となるPythonのバージョンは、以下となります。
- Python 3.6
- Python 3.7
- Python 3.8
Python 3.9は、単純にsetup.pyへの記載漏れの可能性があります。
それか、Python 3.9でのテストが未検証なだけかもしれません。
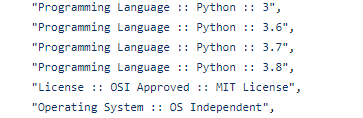
実際、私は次のバージョンで検証しています。
>python -V Python 3.9.7
PyTorch
Open-Unmixは、PyTorchを機械学習のフレームワークとして利用しています。
そのため、PyTorchのインストールが必要です。
必要と言っても、Open-Unmixのインストール時にPyTorchは自動的にインストールされます。
ただし、PyTorchのGPU版を使いたい人もいるでしょう。
そのような場合は、事前に手動でインストールしておきます。
しかし、今回はそれをやめておいた方がよいでしょう。
RuntimeError: CUDA out of memory. Tried to allocate
上記のようなGPUのメモリ不足エラーになる可能性が高いです。
でも、GPUのメモリが16GB以上あるなら、試してみてもいいかもしれません。
そういう訳で、今回はPyTorchに関しては何もしません。
PySoundFile
PyTorch(torchaudio)で音声ファイルを扱う場合に必要です。
事前に次のコマンドでインストールしておきましょう。
pip install PySoundFile
なお、Linuxの場合はsoxライブラリをインストールします。
ただし、SoX自体のインストールも必要になります。
詳細は、次のページをご覧ください。
https://pypi.org/project/sox/
以上、Open-Unmixのシステム要件を説明しました。
次は、Open-Unmixをインストールします。
Open-Unmixのインストール
まずは、現状のインストール済みパッケージを確認しておきます。
現状は、PySoundFileをインストールしただけの状態です。
>pip list Package Version ----------- ----------- cffi 1.14.6 pip 21.2.4 pycparser 2.20 PySoundFile 0.9.0.post1 setuptools 58.2.0
次にするべきことは、pipとsetuptoolsの更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip setuptools
では、Open-Unmixのインストールです。
Open-Unmixのインストールは、以下のコマンドとなります。
pip install openunmix
インストールは、それなりに時間がかかります。
PyTorchもまとめてインストールしていますからね。
では、どんなパッケージがインストールされたのかを確認しましょう。
>pip list Package Version ----------------- ----------- cffi 1.14.6 colorama 0.4.4 numpy 1.21.2 openunmix 1.2.1 pip 21.2.4 pycparser 2.20 PySoundFile 0.9.0.post1 setuptools 58.2.0 torch 1.9.1 torchaudio 0.9.1 tqdm 4.62.3 typing-extensions 3.10.0.2
CPU版の最新版PyTorchが、インストールされています。
Open-Unmixは思ったほど多くのパッケージには、依存していないようです。
以上、Open-Unmixのインストールを説明しました。
次は、Open-Unmixの学習済みモデルついて確認します。
Open-Unmixの学習済みモデル
全部で4つのモデルが利用可能です。
- umxl
- umxhq
- umx
- umxse
これらは、わざわざダウンロードする必要はありません。
利用時に存在しなければ、自動的にダウンロードされます。
デフォルト(指定なし)は、umxlが利用されることになります。
元データは、Open-Unmixチームの個人的なデータになると記載されています。
そして、umxlは商用利用ができません。
umxhqとumxは、MUSDB18を元に学習したモデルになります。
これらの違いは、品質になります。
high qualityかnormalかどうかということです。
MUSDB18は、利用は自由と記載されています。
しかし、商用利用可能かどうかは不明です。
あと、umxseはSony Corporationが作成したモデルになります。
このモデルの特徴は、スピーチに特化していることのようです。
実際に利用する際は、利用規約をじっくり確認してみてください。
以上、Open-Unmixの学習済みモデルを説明しました。
最後は、Open-Unmixの動作確認を行います。
Open-Unmixの動作確認
今回は、コマンドラインツールで確認します。
確認の前に、音楽ファイルを用意しましょう。
処理可能なファイル形式は、次の3つです。
- wav
- flac
- ogg
mp3は、対象外になります。
そして、今回用意したのは以下です。
【魔王魂公式】UNiVERSE
https://www.youtube.com/watch?v=UgccwRi3e-A
上記の曲は、「販売したりストリーミング配信」する以外は、自由に使ってよいということです。
音楽は、input.wavというファイル名で保存します。
このファイルを対象にする場合は、次のコマンドを実行。
umx --model umx input.wav
umxコマンドの利用方法は、以下。
usage: umx [-h] [--model MODEL] [--targets TARGETS [TARGETS ...]] [--outdir OUTDIR] [--ext EXT] [--start START]
[--duration DURATION] [--no-cuda] [--audio-backend AUDIO_BACKEND] [--niter NITER]
[--wiener-win-len WIENER_WIN_LEN] [--residual RESIDUAL] [--aggregate AGGREGATE]
[--filterbank FILTERBANK] [--verbose]
input [input ...]
初回実行時(モデルが存在しない場合)は、必要なファイルをダウンロードすることになります。
ダウンロードを除いた処理自体は、数分で終わるレベルです。
もちろん、選択したモデル・マシンスペック・ファイルサイズ次第で時間は変わってくるでしょう。
ただ、GPUを使わなくてもそれほど問題はないと言えます。
処理が完了したら、同じ階層上に次のフォルダとファイルが作成されています。
(※出力先は「–outdir」で変更可能)
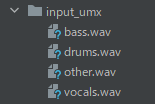
他のモデルを指定して実行した結果は、次のようになります。
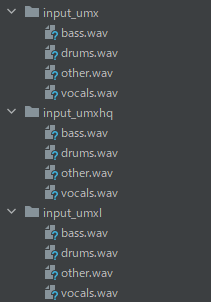
「Open-Unmixとは?」で示したボーカル抽出した音声は、「input_umxhq」の「vocals.wav」です。
「umx」・「umxhq」・「umxl」の中では、最も質が高い結果となっています。
ちなみに、umxseモデルのみ次のような構成になります。
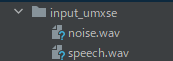
そして、umxseモデルのボーカル抽出はかなり質が低いです。
そもそも、音楽は対象ではないということでしょうね。
以上、Open-Unmixの動作確認を説明しました。

