「parquetという拡張子のファイルは、どうやって開くの?」
「CSVの容量でディスクの使用率がヤバくなってきた・・・」
このような場合には、この記事の内容が参考になります。
この記事では、Parquet形式のファイルについて解説しています。
本記事の内容
- Parquetとは?
- CSVからParquetへの変換
- Parquetの読み込み
それでは、上記に沿って解説していきます。
Parquetとは?
「train.parquet」というファイル名を見たことがありませんか?
これは、Parquet形式のファイルになります。
Parquetとは、正式にはApache Parquet(アパッチ・パーケット)と言います。
このParquetの主な特徴は、以下となります。
- 列ベースのフォーマット
- 高効率なデータ圧縮・解凍
CSVは、行ベースのフォーマットです。
それに対して、Parquetは列ベースになります。
この比較で覚えれば、Parquet形式を覚えやすくなります。
また、データを効率良く圧縮することが可能です。
その結果、ディスク容量を削減することが可能になります。
それも件数が多ければ多いほど、よりディスク容量を削減できるようです。
10万件を超えたら、CSVの数パーセントの容量に削減可能という記事もあります。
果たして、これは本当なのでしょうか?
では、このことを以下で検証してみましょう。
CSVからParquetへの変換
CSVからParquetへの変換を行います。
郵便番号のCSVなら、簡単に手に入れることができます。

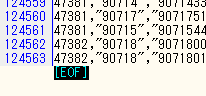
行数は、12万行以上あります。
変換するためには、以下のライブラリが必要となります。
- Pandas
- PyArrow
Pandasはすでにインストール済みかもしれません。
PyArrowについては、次の記事で解説しています。

必要ライブラリのインストールには、次のコマンドを利用します。
pip install pandas pip install pyarrow
準備ができたら、次のコードを実行します。
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
df = pd.read_csv('./data/KEN_ALL.CSV', encoding="shift-jis")
table = pa.Table.from_pandas(df)
pq.write_table(table, './data/KEN_ALL.parquet')
上記を実行した結果、ファイルが作成されます。

約25%にまで削減することができました。
まだ、削減できるのを見てみたいですね。
では、さらに大きいCSVを対象にしてみましょう。

このCSVは、次のページ(全国版)から取得できます。
法人番号がダウンロードできるようです。
https://www.houjin-bangou.nta.go.jp/download/zenken/
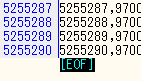
行数は、500万行オーバーです。
おそらく、この大容量CSVをエクセルでは開けないかもしれません。
それでは、この大容量CSVをParquetに変換してみましょう。
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
df = pd.read_csv('./data/00_zenkoku_all_20221228.csv', encoding="shift-jis")
table = pa.Table.from_pandas(df)
pq.write_table(table, './data/00_zenkoku_all_20221228.parquet')
実行した結果は、以下。
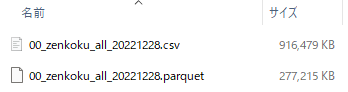
約30%にまでにしか削減できていません。
ダイエットが足りませんね・・・
二つのCSVについて、まとめておきます。
| 行数 | 列数 | 圧縮率 | |
| 郵便番号CSV | 124563 | 15 | 25% |
| 法人番号CSV | 5255290 | 30 | 30% |
容量が3分の1になっている時点で、効果はあると言えます。
しかし、行数が増えればより圧縮率は高まるとか言うのはデマ(勘違い)なんでしょうかね?
それとも、前提となる条件が他にあるのかもしれません。
とにかく、3分の1以下にディスク容量を削減できることは確認できました。
これだけでも、十分過ぎる効果と言えます。
以上、CSVからParquetへの変換を説明しました。
次は、Parquetの読み込みを説明します。
Parquetの読み込み
Parquetの読み込みを行います。
先ほど、変換して作成したParquetファイルを読み込みましょう。
import pyarrow.parquet as pq
table = pq.read_table("./data/KEN_ALL.parquet")
df = table.to_pandas()
df.info()
上記を実行すると、データの情報が確認できます。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 124562 entries, 0 to 124561 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 01101 124562 non-null int64 1 060 124562 non-null int64 2 0600000 124562 non-null int64 3 ホッカイドウ 124562 non-null object 4 サッポロシチュウオウク 124562 non-null object 5 イカニケイサイガナイバアイ 124562 non-null object 6 北海道 124562 non-null object 7 札幌市中央区 124562 non-null object 8 以下に掲載がない場合 124562 non-null object 9 0 124562 non-null int64 10 0.1 124562 non-null int64 11 0.2 124562 non-null int64 12 0.3 124562 non-null int64 13 0.4 124562 non-null int64 14 0.5 124562 non-null int64 dtypes: int64(9), object(6) memory usage: 14.3+ MB
大きい方のデータも読み込んでみましょう。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 5255289 entries, 0 to 5255288 Data columns (total 30 columns): # Column Dtype --- ------ ----- 0 1 int64 1 1000012160153 int64 2 01 int64 3 1.1 int64 4 2018-04-02 object 5 2015-10-05 object 6 釧路検察審査会 object 7 Unnamed: 7 float64 8 101 int64 9 北海道 object 10 釧路市 object 11 柏木町4−7 object 12 Unnamed: 12 float64 13 01.1 float64 14 206 float64 15 0850824 float64 16 Unnamed: 16 object 17 Unnamed: 17 float64 18 Unnamed: 18 object 19 Unnamed: 19 float64 20 Unnamed: 20 float64 21 Unnamed: 21 object 22 2015-10-05.1 object 23 1.2 int64 24 Kushiro Committee for the Inquest of Prosecution object 25 Hokkaido object 26 4-7, Kashiwagicho, Kushiro shi object 27 Unnamed: 27 object 28 クシロケンサツシンサカイ object 29 0 int64 dtypes: float64(8), int64(7), object(15) memory usage: 1.2+ GB
メモリが、1.2GB以上も利用されています。
コード的には、読み込んだデータをデータフレームに変換しています。
データフレームにさえ変換できれば、あとは何とでもできます。
以上、Parquetの読み込みを説明しました。