
「リアルな人物の画像を生成したい」
「多人数の実写系画像を生成したい」
このような場合には、Realistic Vision V2.0がオススメです。
この記事では、Realistic Vision V2.0について解説しています。
本記事の内容
- Realistic Vision V2.0とは?
- Realistic Vision V2.0の利用方法
それでは、上記に沿って解説していきます。
Realistic Vision V2.0とは?
Realistic Vision V2.0とは、名前の通りリアルな画像を生成するモデルです。
リアルに描くモデルは、他にも存在しています。
例えば、Stable Diffusion 2.1ベースのRealism Engineがあります。

それに対して、Realistic Vision V2.0はStable Diffusion 1.5ベースになります。
そのため、リアルという点ではRealism Engineに軍配が上がるかもしれません。
ただし、人を描くと言う点ではRealistic Vision V2.0の方が使えそうです。
特に、多人数を描くことにおいては最も優秀なモデルかもしれません。

これらは、デモ画像を参考に一発目で生成した画像です。
サクサクと大人数を表現した画像を生成できます。
もちろん、単体で描くのもこのレベルで可能です。

基本的には、Realistic Vision V2.0は人物を描くことが得意なモデルと言えるでしょう。
実際、人物を描くことを得意とする以下のモデルを結合していますからね。
- HassanBlend 1.5.1.2
- Uber Realistic Porn Merge (URPM)
- Protogen x3.4 (Photorealism) + Protogen x5.3 (Photorealism)
- Art & Eros (aEros) + RealEldenApocalypse
- Dreamlike Photoreal 2.0
- HASDX
- Analog Diffusion
- WoopWoop-Photo
ただし、残念なことにRealistic Vision V2.0は日本人の描画が下手です。
結合しているモデルを見ても、その傾向があります。
日本人、特に女性を描きたい場合は、ChilloutMixをオススメします。

でも、ChilloutMixではこんなに多人数を表現するのは難しいですけどね。。。
以上、Realistic Vision V2.0について説明しました。
次は、Realistic Vision V2.0の利用方法を説明します。
Realistic Vision V2.0の利用方法
まずは、公式ページからモデルをダウンロードします。
Realistic Vision V2.0 | Stable Diffusion Checkpoint | Civitai
https://civitai.com/models/4201/realistic-vision-v20
ダウンロードするファイルは、以下から選択できます。
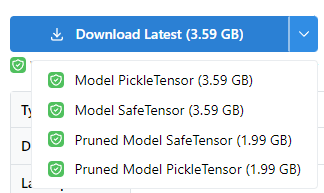
最も無難なモノは、「Model SafeTensor」でしょう。
SafeTensor形式のファイルの方が、安全かつ高速に読み込みが可能です。

今回ダウンロードできたファイルは、「realisticVisionV20_v20.safetensors」です。
利用方法については、それぞれの環境で異なります。
- Stable Diffusion web UI(AUTOMATIC1111版)
- Diffusers
それぞれの場合を以下で説明します。
Stable Diffusion web UI(AUTOMATIC1111版)
web UIのインストールは、次の記事で説明しています。
web UIの場合は、特に難しいことは何もありません。
ダウンロードしたファイルを指定のディレクトリ(models/Stable-diffusion)に設置するだけです。
web UIの起動後、以下のようにcheckpointを選択できるようになっています。

あとは、プロンプトを入力して画像生成を行うだけです。
この際、Civitai上のサンプル画像やユーザー投稿などを参考にできます。

このアイコンをクリックすると、次のような画面が表示されます。
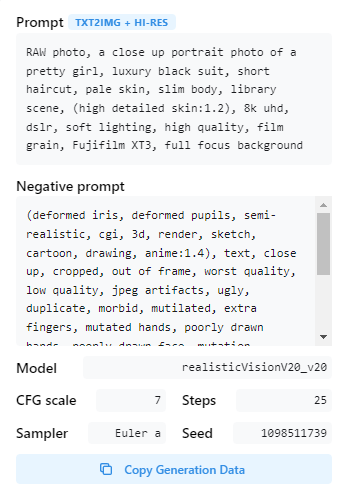
もしくは、画像をダウンロードしてPNG Infoにアップロードします。
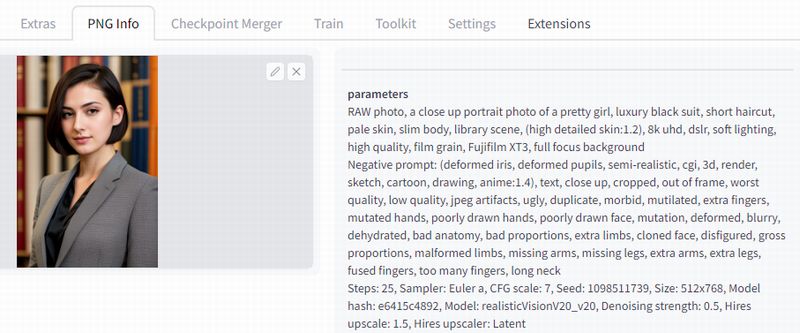
PNG Infoについては、次の記事で説明しています。

Diffusers
Diffusersの場合は、少し工夫が必要となります。
まずは、Stable Diffusionを動かす環境を用意します。

上記記事に従えば、自ずとDiffusersをインストールすることになります。

Diffusersの場合、そのままではダウンロードしたモデルを読み込めません。
そのため、Diffusersで利用できるように変換処理を行う必要があります。
Safetensors形式ファイルの変換処理は、次の記事で解説しています。

変換に用いたのは、以下のコマンドです。
python convert_diffusers20_original_sd.py ..\..\ckpt\realisticVisionV20_v20.safetensors ..\..\model\realisticVisionV20_v20 --v1 --reference_model runwayml/stable-diffusion-v1-5
変換に成功すると、次のようなディレクトリ・ファイルが作成されます。
ここまで準備できたら、あとは次のコードで画像生成が可能です。
from diffusers import StableDiffusionPipeline, EulerAncestralDiscreteScheduler
model_id = "./model/realisticVisionV20_v20"
pipe = StableDiffusionPipeline.from_pretrained(model_id, custom_pipeline="lpw_stable_diffusion")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
# pipe.enable_attention_slicing()
prompt = "RAW photo, a close up portrait photo of a pretty girl, luxury black suit, short haircut, pale skin, slim body, library scene, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3, full focus background"
negative_prompt = " (deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
image = pipe(
prompt,
num_inference_steps=25,
guidance_scale=7,
width=512,
height=768,
max_embeddings_multiples=2,
negative_prompt=negative_prompt
).images[0]
image.save("test.png")
このコードを実行すると、次のような画像が生成されます。

なお、コード上では長いプロンプトに対応する処理が含まれています。
それらの方法については、次の記事で説明しています。

以上、Realistic Vision V2.0の利用方法を説明しました。

