
「Stable Diffusionでcheckpointをモデルとして利用したい」
「Safetensors形式のファイルをDiffusersで読み込めるモデルに変換したい」
このような場合には、この記事の内容が参考になります。
この記事では、safetensorsをDiffusersでモデルとして読み込む方法を解説しています。
本記事の内容
- Diffusers用モデルへのsafetensorsの変換
- safetensorsの変換に必要なシステム要件
- safetensorsの変換方法
- safetensorsから変換したモデルの読み込み
それでは、上記に沿って解説していきます。
Diffusers用モデルへのsafetensorsの変換
画像生成AIのStable Diffusionは、まだまだその勢いが止まりません。
そして、技術的にもどんどんと新しいモノが取り入れられています。
その一つにsafetensorsがあります。
ckptとともに、次のようなファイルを見たことがありませんか?
次のページから確認できます。
stabilityai/stable-diffusion-2-base at main
https://huggingface.co/stabilityai/stable-diffusion-2-base/tree/main
簡単に言うと、新しいファイル形式です。
Stable Diffusionの世界では、その形式でモデルを配布する方向になりつつあります。
safetensorsの詳細については、次の記事で解説しています。

このsafetensorsの登場で、面倒なことが生じています。
そもそも、Diffusers利用者にとってはckptファイル自体が面倒な存在です。
さらにそこへ、safetensorsファイルが登場してきています。
上記で載せたStable Diffusion v2-baseなどは、そんなことは関係なく利用できます。
次の文字列をモデルに指定すれば、いいだけです。
stabilityai/stable-diffusion-2-base
そうすれば、あとはDiffusersがHugging Faceから必要なファイルを勝手にダウンロードしてくれます。
しかし、Diffusers対応していないモデルなどは自分で変換する必要があります。
ckptファイルしか配布されていないようなモデルですね。
例えば、人体の描画に特化したF222などがその形になります。

ckptファイルを変換する方法については、次の記事で解説しています。

これだけでも、ちょっとした手間でした。
そこに、safetensorsファイルも割り込んできたということです。
それも、現状ではckptファイルの変換と同じ手法が通じません。
というか、Diffusers公式からはその方法が公開されていないようです。
少なくとも、公式のGitHub上では見つかりません。
将来的には公開されるとは思いますが、それがいつになるかはわかりません。
そんな状況において、有志で変換スクリプトを公開してくれている人がいます。
Stable Diffusion checkpointとDiffusersモデルの相互変換スクリプト(SD2.0対応)
https://note.com/kohya_ss/n/n374f316fe4ad
本当にこういう活動は、ありがたいですね。
以上、Diffusers用モデルへのsafetensorsの変換について説明しました。
次は、safetensorsの変換に必要なモノを説明します。
safetensorsの変換に必要なモノ
基本的には、次の記事に記載した通りです。
とりあえず、上記記事を参考にしてckptファイルの変換までができる状態にします。
インストールするモノは、その時点での最新版にしておきましょう。
では、今回のメインとなるスクリプトをダウンロードします。
先ほど紹介したページから、ダウンロードできます。

ダウンロードしたzipを解凍。
これらのファイルを変換用スクリプトの設置場所に保存します。
以上、safetensorsの変換に必要なモノを説明しました。
次は、safetensorsの変換方法を説明します。
safetensorsの変換方法
ダウンロードしたスクリプトは、以下の変換が可能です。
- checkpoint→Diffusersモデル
- Diffusersモデル→checkpoint
ここでは、「checkpoint→Diffusersモデル」のみ取り上げます。
また、Stable Diffusionのバージョンについては1系、2系の両方ともに対応しています。
詳細については、紹介したページをご覧ください。
もしくは、ヘルプを確認しましょう。
> python convert_diffusers20_original_sd.py -h
usage: convert_diffusers20_original_sd.py [-h] [--v1] [--v2] [--fp16] [--bf16] [--float] [--epoch EPOCH] [--global_step GLOBAL_STEP] [--reference_model REFERENCE_MODEL]
[--use_safetensors]
model_to_load model_to_save
--v1 load v1.x model (v1 or v2 is required to load checkpoint) / 1.xのモデルを読み込む
--v2 load v2.0 model (v1 or v2 is required to load checkpoint) / 2.0のモデルを読み込む
--fp16 load as fp16 (Diffusers only) and save as fp16 (checkpoint only) / fp16形式で読み込み(Diffusers形式のみ対応)、保存する(checkpointのみ対応)
--bf16 save as bf16 (checkpoint only) / bf16形式で保存する(checkpointのみ対応)
--float save as float (checkpoint only) / float(float32)形式で保存する(checkpointのみ対応)
--epoch EPOCH epoch to write to checkpoint / checkpointに記録するepoch数の値
--global_step GLOBAL_STEP
global_step to write to checkpoint / checkpointに記録するglobal_stepの値
--reference_model REFERENCE_MODEL
reference model for schduler/tokenizer, required in saving Diffusers, copy schduler/tokenizer from this /
scheduler/tokenizerのコピー元のDiffusersモデル、Diffusers形式で保存するときに必要
--use_safetensors use safetensors format to save Diffusers model (checkpoint depends on the file extension) / Duffusersモデルをsafetensors形式で保存する(checkpointは拡張子で自動 判定)
では、実際に変換してみましょう。
次の記事で取り上げたモデルが対象として利用できます。

もともとDiffusersモデルは、存在しています。
さらには、checkpoint(ckpt・safetensors両方)も公開されています。
prompthero/openjourney at main
https://huggingface.co/prompthero/openjourney/tree/main
「mdjrny-v4.safetensors」をダウンロードして、「ckpt」ディレクトリに保存。
Diffusersモデルを保存するために「model」ディレクトリも用意しておきます。
スクリプトのある場所で次のコマンドを実行します。
python convert_diffusers20_original_sd.py ..\..\ckpt\mdjrny-v4.safetensors ..\..\model\mdjrny-v48 --v1 --reference_model runwayml/stable-diffusion-v1-5
Midjourney v4 Diffusionは、SD 1系をベースにしています。
そのため、次の指定となります。
--v1 --reference_model runwayml/stable-diffusion-v1-5
なお、「v1」を指定する場合は、以下のどちらでもOKのようです。
- runwayml/stable-diffusion-v1-5
- CompVis/stable-diffusion-v1-4
すでにダウンロード済みの方を選んでおけばよいでしょう。
では、コマンドを実行してみましょう。
処理はすぐに完了します。
~ loading text encoder: <All keys matched successfully> converting and saving as Diffusers: ..\..\model\mdjrny-v48 copy scheduler/tokenizer config from: runwayml/stable-diffusion-v1-5 model saved.
指定した場所に、モデルが保存されていることを確認できます。
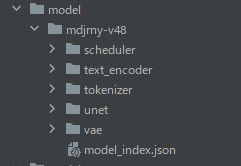
以上、safetensorsの変換方法を説明しました。
次は、safetensorsから変換したモデルの読み込みを説明します。
safetensorsから変換したモデルの読み込み
モデルは、パスを指定することで呼び出せます。
from diffusers import StableDiffusionPipeline
import torch
MODEL_ID = "model/mdjrny-v48"
DEVICE = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(MODEL_ID, torch_dtype=torch.float16)
pipe = pipe.to(DEVICE)
prompt = "mdjrny-v4 style,a photo of an astronaut riding a horse on mars"
image = pipe(prompt, width=512, height=512).images[0]
image.save("astronaut_rides_horse.png")
なお、1つ注意点があります。
サイズ未指定だと、256 x 256で画像が生成されます。
そのため、サイズをデフォルトとされている512 x 512で設定しています。
コードを実行した結果は、次のような画像が生成されます。

Midjourney的な画像が生成されています。
以上、safetensorsから変換したモデルの読み込みを説明しました。

