
「動画上の人物に用意した音声をしゃべらせたい」
「スピーチを入れ替えた動画を作成したい」
このような場合には、Wav2Lipがオススメです。
この記事では、Wav2Lipについて解説しています。
本記事の内容
- Wav2Lipとは?
- Wav2Lipのシステム要件
- Wav2Lipのインストール
- Wav2Lipの動作確認
それでは、上記に沿って解説していきます。
Wav2Lipとは?
Wav2Lipとは、ACM Multimedia 2020で発表されたモデルのことです。
モデルを動かすために用意されたプロジェクトが、GitHub上にWav2Lipとして公開されています。
このWav2Lipを利用すると、動画を編集できます。
具体的には、動画上の人物に無理やり話させることができるようになります。
言葉より、実際に動画を見た方が圧倒的にわかりやすです。
次の動画をご覧ください。
左半分の動画では、女性は黙読して何も話していません。
対して、右半分の動画上の女性は日本語で天気のことをつぶやいています。
このようにして、動画上の人物に用意した音声を話させることが可能になります。
話す際に、口の動きをそれっぽくなるようにAIで動画編集が行われています。
以上、Wav2Lipについて説明しました。
次は、Wav2Lipのシステム要件を説明します。
Wav2Lipのシステム要件
Wav2Lipは、特にバージョン管理はされていません。
GitHub上のソースは、2020年8月を最後に更新されていないようです。
そんなWav2Lipのシステム要件は、以下がポイントになります。
- OS
- Pythonバージョン
- PyTorch
- FFmpeg
それぞれを以下で説明します。
OS
サポートOSに関しては、以下を含むクロスプラットフォーム対応のはずです。
- Windows
- macOS
- Linux
特にOSについては、明記されていはいません。
ただ、システム要件のところに次のような表記があります。

明らかに、Linuxを対象にして記載されているように見えます。
でも、安心してください。
Windowsでもちゃんと動くことを確認できています。
それであれば、macOSも問題なく動くはずです。
Pythonバージョン
サポート対象となるPythonのバージョンは、Python 3.6が記載されています。
しかし、Python 3.6は2021年末でサポート期限が終了しています。
以下のPython公式開発サイクルにも、はっきりと記載されています。
| バージョン | リリース日 | サポート期限 |
| 3.6 | 2016年12月23日 | 2021年12月23日 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
よって、みなさんはPython 3.7以降を利用しましょう。
Python 3.10でも動くことを確認できています。
PyTorch
PyTorchに関しても、バージョンが指定されています。
requirements.txtには、次のような記載があります。
torch==1.1.0 torchvision==0.3.0
現時点(2022年9月)では、PyTorch 1.12.1が最新の安定版となります。
性能が全く異なるため、最新バージョンのPyTorchをインストールしましょう。
あと、GPUが利用できるならGPU版PyTorchを利用することを推奨します。
CPUだけでも動くようですが、動画編集でGPUがないのは厳しいです。
GPU版PyTorchのインストールは、次の記事で解説しています。

FFmpeg
動画編集の実作業をFFmpegが担当するのでしょう。
そのため、FFmpegのインストールが必須となっています。
FFmpegのインストールは、以下の記事を参考にしてください。




バージョンに関しては、最新版をインストールするようにしましょう。
以上、Wav2Lipのシステム要件を説明しました。
次は、Wav2Lipのインストールを説明します。
Wav2Lipのインストール
Wav2Lipのインストールを行っていきます。
言うまでもありませんが、Wav2LipはPython仮想環境にインストールしましょう。

PyTorchとFFmpegは、すでにインストール済みとします。
この状態で、まずはGitHubからプロジェクトをダウンロードしましょう。
git clone https://github.com/Rudrabha/Wav2Lip.git
gitコマンドでGitHubからWav2Lipのソース一式を取得します。
Windowsの場合であれば、gitコマンドが利用できないかもしれません。
その場合は、次の記事を参考にしてください。

プロジェクトのダウンロードが完了したら、リポジトリルートに移動します。
cd Wav2Lip
基本的には、この場所でコマンドを実行することになります。
次は、パッケージのインストールです。
requirements.txtを同一ディレクトリ上で確認できます。
requirements.txt
librosa==0.7.0 numpy==1.17.1 opencv-contrib-python>=4.2.0.34 opencv-python==4.1.0.25 torch==1.1.0 torchvision==0.3.0 tqdm==4.45.0 numba==0.48
これを次のように変更します。
librosa numpy opencv-contrib-python opencv-python tqdm numba
それぞれ最新版をインストールするように変更しています。
あとは、PyTorchに関する部分を除去しましょう。
ファイルを変更できたら、次のコマンドを実行します。
pip install -r requirements.txt
インストールが完了したら、インストール済みパッケージの確認です。
> pip list Package Version --------------------- ------------ appdirs 1.4.4 audioread 3.0.0 certifi 2022.9.14 cffi 1.15.1 charset-normalizer 2.1.1 colorama 0.4.5 decorator 5.1.1 idna 3.4 joblib 1.2.0 librosa 0.9.2 llvmlite 0.39.1 numba 0.56.2 numpy 1.23.3 opencv-contrib-python 4.6.0.66 opencv-python 4.6.0.66 packaging 21.3 Pillow 9.2.0 pip 22.2.2 pooch 1.6.0 pycparser 2.21 pyparsing 3.0.9 requests 2.28.1 resampy 0.4.2 scikit-learn 1.1.2 scipy 1.9.1 setuptools 59.8.0 SoundFile 0.10.3.post1 threadpoolctl 3.1.0 torch 1.12.1+cu113 torchaudio 0.12.1+cu113 torchvision 0.13.1+cu113 tqdm 4.64.1 typing_extensions 4.3.0 urllib3 1.26.12 wheel 0.36.2
以上、Wav2Lipのインストールを説明しました。
次は、Wav2Lipの動作確認を説明します。
Wav2Lipの動作確認
Wav2Lipの動作確認を行います。
次の流れで動作確認を説明していきます。
- 顔認識のための学習済みモデル設置
- Wav2Lipのための学習済みモデル設置
- 動作確認
顔認識のための学習済みモデル設置
顔認識の学習済みモデルをダウンロードする必要があります。
モデルURL
https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth
上記URLからファイルを取得します。
アクセスした時点でダウンロードが始まります。
保存したファイルは、次のように名称変更します。
s3fd-619a316812.pth → s3fd.pth
ファイル名を変更したら、「face_detection/detection/sfd」にファイルを設置します。
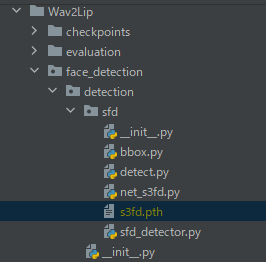
Wav2Lipのための学習済みモデル設置
これが、Wav2Lipのコアと言えます。
全部で4つのファイルが公開されています。
GitHub上のWav2Lip公式
https://github.com/Rudrabha/Wav2Lip#getting-the-weights
上記ページから、それらのファイルを取得することが可能です。
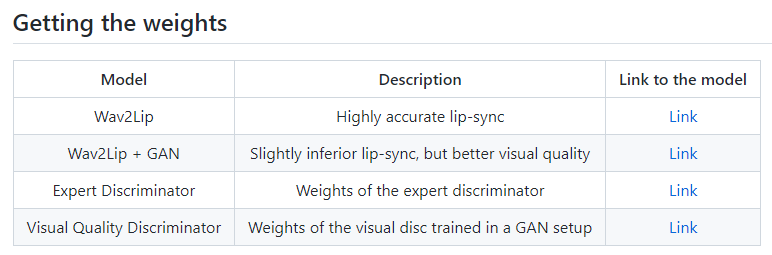
「Link」リンクをクリックすると、次のような画面が表示されます。
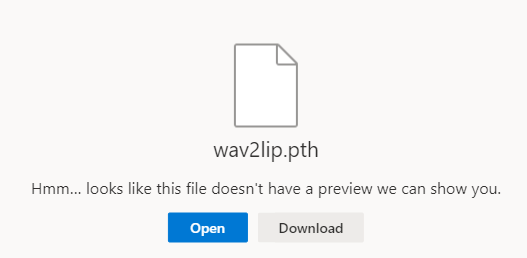
「Download」ボタンをクリックして、対象のモデルをダウンロードします。
ダウンロードしたファイルは、「checkpoints」へ移動させておきます。
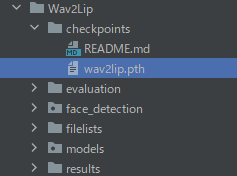
全部のモデルを設置して、使い分けても良いでしょう。
それぞれ、そんなに容量があるファイルでもありませんので。
動作確認
学習済みモデルの設置が完了したら、いよいよ動作を確認できます。
その前に、動画(mp4)と音声(mp3)を用意しましょう。
動画については、次のサイトが役に立ちます。
人物用の動画を無料でダウンロードできます。
https://www.pexels.com/ja-jp/
今回は、次のページの動画(test.mp4)をダウンロードしています。
https://www.pexels.com/ja-jp/video/5199836/
音声については、適当なサイトは見つかりませんでした。
テキストから音声を自分で作成した方が、探すより早いかもしれません。
テキストから音声ファイルを作成する方法は、次の記事で説明しています。

今回は、上記記事で作成した音声ファイル(test.mp3)を利用します。
ファイルは、適当に作成したディレクトリに保存しています。
ここまでの準備が整っていれば、次のコマンドが動くはずです。
python inference.py --checkpoint_path checkpoints/wav2lip.pth --face assets/test.mp4 --audio assets/test.mp3
コマンドの詳細は、ヘルプで確認できます。
> python inference.py -h
usage: inference.py [-h] --checkpoint_path CHECKPOINT_PATH --face FACE --audio AUDIO [--outfile OUTFILE] [--static STATIC] [--fps FPS] [--pads PADS [PADS ...]]
[--face_det_batch_size FACE_DET_BATCH_SIZE] [--wav2lip_batch_size WAV2LIP_BATCH_SIZE] [--resize_factor RESIZE_FACTOR] [--crop CROP [CROP ...]]
[--box BOX [BOX ...]] [--rotate] [--nosmooth]
Inference code to lip-sync videos in the wild using Wav2Lip models
options:
-h, --help show this help message and exit
--checkpoint_path CHECKPOINT_PATH
Name of saved checkpoint to load weights from
--face FACE Filepath of video/image that contains faces to use
--audio AUDIO Filepath of video/audio file to use as raw audio source
--outfile OUTFILE Video path to save result. See default for an e.g.
--static STATIC If True, then use only first video frame for inference
--fps FPS Can be specified only if input is a static image (default: 25)
--pads PADS [PADS ...]
Padding (top, bottom, left, right). Please adjust to include chin at least
--face_det_batch_size FACE_DET_BATCH_SIZE
Batch size for face detection
--wav2lip_batch_size WAV2LIP_BATCH_SIZE
Batch size for Wav2Lip model(s)
--resize_factor RESIZE_FACTOR
Reduce the resolution by this factor. Sometimes, best results are obtained at 480p or 720p
--crop CROP [CROP ...]
Crop video to a smaller region (top, bottom, left, right). Applied after resize_factor and rotate arg. Useful if multiple face present. -1 implies
the value will be auto-inferred based on height, width
--box BOX [BOX ...] Specify a constant bounding box for the face. Use only as a last resort if the face is not detected.Also, might work only if the face is not moving
around much. Syntax: (top, bottom, left, right).
--rotate Sometimes videos taken from a phone can be flipped 90deg. If true, will flip video right by 90deg.Use if you get a flipped result, despite feeding
a normal looking video
--nosmooth Prevent smoothing face detections over a short temporal window
コマンドを実行すると、しばらく処理が行われます。
処理が完了すると、「results」ディレクトリにファイルが作成されています。
この動画ファイルは、「Wav2Lipとは?」で紹介した動画です。
正確には、右半分の動画になります。
以上、Wav2Lipの動作確認を説明しました。

