
「Whisperをブラウザから気軽に使いたい」
「Whisperを用いたアプリを作ってみたい」
このような場合には、Whisper Webuiがオススメです。
この記事では、Whisper Webuiの導入方法について解説しています。
本記事の内容
- Whisper Webuiとは?
- Whisper Webuiのシステム要件
- Whisper Webuiのインストール
- Whisper Webuiの動作確認
それでは、上記に沿って解説していきます。
Whisper Webuiとは?
Whisper Webuiとは、Whisperを利用したWebアプリのことです。
Hugging FaceでWebアプリとして公開されています。
Whisper Webui – a Hugging Face Space by aadnk
https://huggingface.co/spaces/aadnk/whisper-webui
動作については、上記ページから確認できます。
機能的には、Whisperでできることを一通りできそうです。
Hugging Face上のデモアプリでは、10分の音声までという制限があります。
これでも、デモアプリとしては十分長いのですけどね。

この制限は、自由に変更することができます。

Hugging Face上のアプリは、あくまでサンプルに過ぎません。
そのため、このデモアプリを常時利用することは想定すべきではありません。
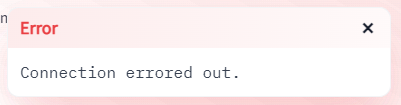
そもそも、時間帯によってはサンプルがまともに動きません。
散々待たされた挙句に、コネクションエラーとなることがあります。
それに、セキュリティ的にも機密情報をアップロードするのはマズイです。
このことは、念頭に置いておきましょう。
だからこそ、ローカル環境へインストールすることに意味があるのです。
便利ツールとしてのWhisper Webuiについて、触れておきましょう。
個人的には、次のGUIの機能が最も便利だと感じます。

この機能により、マイクで話した内容を自動的にアップロードすることが可能になります。
正直、この機能のためだけにWhisper Webuiを導入しても良いぐらいです。
あとは、SRTファイルやVTTファイルを生成する機能も便利です。
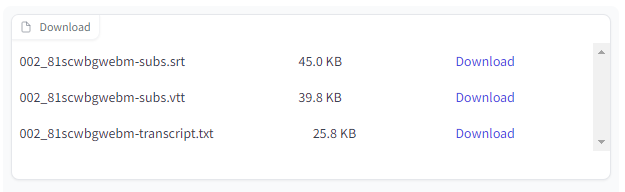
SRTファイルがあれば、動画への字幕入れも簡単にできます。

ASSファイルが必要であれば、SRTファイルから自動で作成することも可能です。
そのような機能変更は、ソースが手元にあれば容易に実現できます。
以上、Whisper Webuiについて説明しました。
次は、Whisper Webuiのシステム要件を説明します。
Whisper Webuiのシステム要件
基本的には、Whisperのシステム要件と同じです。
Whisperのインストールについては、次の記事で説明しています。

事前にWhisperは、インストールしておきましょう。
一応、Whisper Webuiで用意しているrequirements.txtにも記載されています。
requirements.txt
git+https://github.com/openai/whisper.git transformers ffmpeg-python==0.2.0 gradio yt-dlp torchaudio
ただ、これを迂闊にインストールするとCPU版のPyTorchがインストールされてします。
そのため、PyTorch関係のモノは事前にインストールしておきます。
そうすると、Whisper Webui独自で必要なモノは以下だけとなります。
gradio yt-dlp
Gradio(gradio)は、Webアプリ開発のフレームワークです。

yt-dlpにより、YouTubeからの動画ダウンロードが可能となっています。

この二つだけであれば、事前にシステム要件としてインストールしておきましょう。
インストールには、次のコマンドを実行します。
pip install gradio pip install yt-dlp
以上、Whisper Webuiのシステム要件を説明しました。
次は、Whisper Webuiのインストールを説明します。
Whisper Webuiのインストール
システム要件として、必要なパッケージ類はインストール済です。
ここでは、Whisper Webuiのプログラム一式のダウンロードをメインに説明します。
Whisper Webuiのプログラム一式
https://huggingface.co/spaces/aadnk/whisper-webui/tree/main
プログラム一式は、上記ページで確認できます。
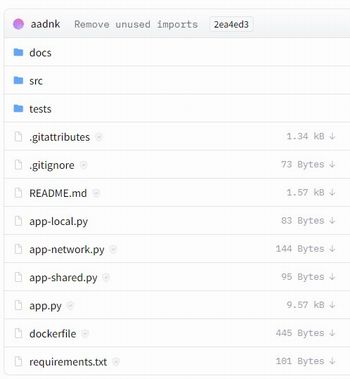
これらを一つづつダウンロードしても構いません。
しかし、それはちょっと面倒過ぎます。
そこで、huggingface_hubを利用します。
huggingface_hubを利用すれば、一括でプログラム一式を取得できます。

huggingface_hubをダウンロードできたら、次のコードを実行します。
from huggingface_hub import snapshot_download
YOUR_TOKEN = "コピーしたアクセストークン"
snapshot_download(
repo_id="aadnk/whisper-webui",
repo_type="space",
revision="main",
use_auth_token=YOUR_TOKEN,
cache_dir="./")
実行すると、次のような表示がコンソールに現れます。
Fetching 15 files: 7%|▋ | 1/15 [00:01<00:21, 1.55s/it] Downloading: 100%|██████████| 73.0/73.0 [00:00<00:00, 36.8kB/s] ~~省略~~ Downloading: 100%|██████████| 1.95k/1.95k [00:00<00:00, 326kB/s] Fetching 15 files: 100%|██████████| 15/15 [00:22<00:00, 1.53s/it]
処理が完了すると、ディレクトリ上には「spaces–aadnk–whisper-webui」を確認できます。
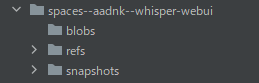
「snapshots」以下にあるファイル・ディレクトリをコピーします。
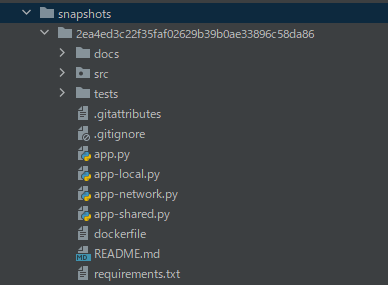
「2ea4ed3c22f35faf02629b39b0ae33896c58da86」は、リポジトリのバージョンです。

正確には、この長たらしいディレクトリ以下をコピーします。
それらを適当な箇所にコピーしたら、Whisper Webuiのインストールは完了です。
以上、Whisper Webuiのインストールを説明しました。
次は、Whisper Webuiの動作確認を説明します。
Whisper Webuiの動作確認
Whisper Webuiの起動は、app.pyを実行します。
正常に起動できると、コンソールには以下のように表示されます。
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
そして、ブラウザで「http://127.0.0.1:7860」にアクセスします。
Hugging Face上のデモと同じ画面を確認できます。
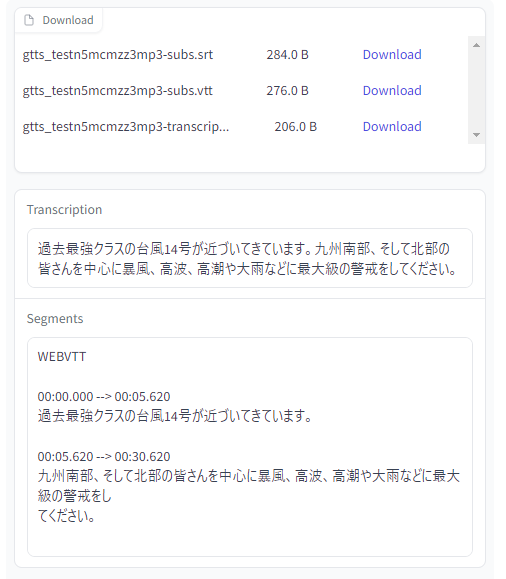
今回は、次の音声ファイルをアップロードします。
実は、この音声はプログラムで自動生成しています。
テキストから音声の作成です。
Whisperの逆となります。

音声ファイルをWhisper Webuiで処理した結果は、以下が表示されました。
モデルなどの設定は何も変更していません。
モデル・言語のデフォルトを変更することも可能です。
ソースは、すべて手元にありますから。
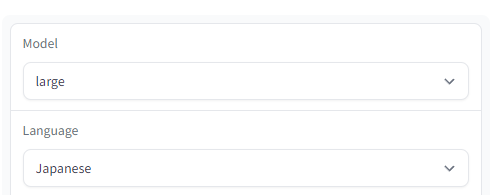
この場合は、app.pyを修正します。

このように、カスタマイズして使いやすいようにしていくことが可能です。
以上、Whisper Webuiの動作確認を説明しました。

