コレスポンデンス分析をPythonで行う方法を解説しています。
論より証拠の考えで、コレスポンデンス分析を数多く実践していきましょう。
そのためにも、気軽にコレスポンデンス分析を行う環境が必要です。
その環境は、Pythonさえ理解できれば簡単に作れます。
本記事の内容
- コレスポンデンス分析とは?
- コレスポンデンス分析の用途
- コレスポンデンス分析をPythonで行うための環境を準備する
- コレスポンデンス分析をPythonで行う
それでは、上記に沿って解説していきます。
コレスポンデンス分析とは?
コレスポンデンス分析(コレポン)とは、多変量解析という分析手法の一つです。
具体的には、クロス集計表を散布図で表現します。
この説明でわかる人はどれくらいいるのでしょうか?
そもそも、「多変量解析」自体が意味不明という人もいるでしょう。
また、クロス集計表や散布図もそうかもしれません。
そのため、以下でこれらについて説明していきます。
これらの理解が、コレスポンデンス分析の理解につながります。
まずは多変量解析の説明です。
多変量解析
多変量解析と理解する上では、以下のキーワードの理解が必須です。
- 説明変数(独立変数)
- 目的変数(従属変数・外的基準)
説明変数は、目的変数を説明する変数のことを言います。
つまり、説明変数が原因であり、目的変数が結果です。
実は、我々は説明変数と目的変数の関係については詳しいのです。
中学生の頃から馴染みがあります。
そう、方程式です。

XとYの関係は、説明変数と目的変数の関係と同じと言えます。
これで説明変数と目的変数については、理解できたと思います。
では、多変量解析とはどういうことでしょうか?
式から見た方が理解しやすいはずです。
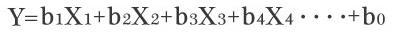
この式を見れば、多変量解析についてはイメージできるでしょう。
説明変数が複数あるのです。
説明変数が複数あれば、もうそれは多変量解析と言えます。
クロス集計表
簡単に言うと、アンケート結果です。
以下は、実際に北九州市が市民に対して実施したアンケートの結果となります。
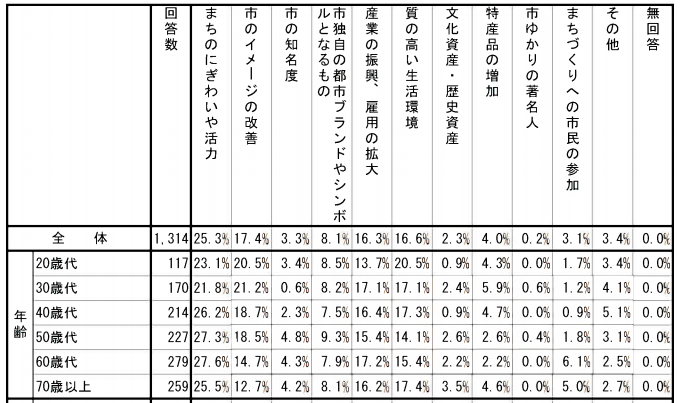
表側項目は、年齢(年代)です。
表頭項目は、市民が北九州市に誇りを持つために必要と考えるモノらしいです。
このような表をクロス集計表と言います。
散布図
散布図は、データの分布を示したグラフのことです。
グラフに各要素をプロットすることにより、データの関係性を確認します。
Pythonで散布図を作成する方法は、次の記事でまとめています。

まとめ
上記で用語の説明をしてきました。
少しは、コレスポンデンス分析のイメージができるようになったはずです。
個人的には、クロス集計表を散布図で表現する分析方法という表現がしっくり来ます。
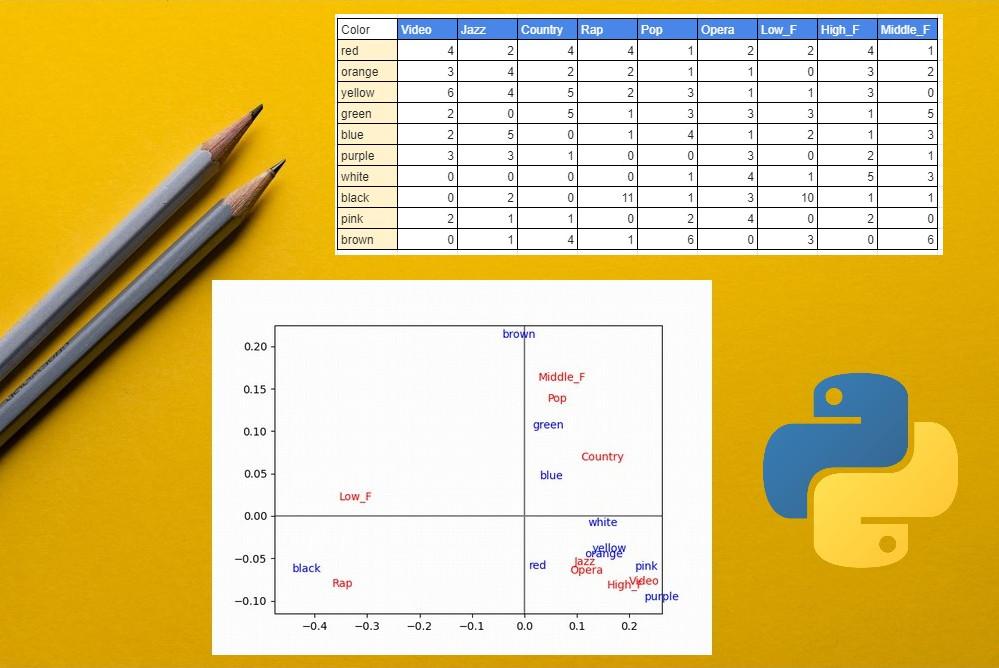
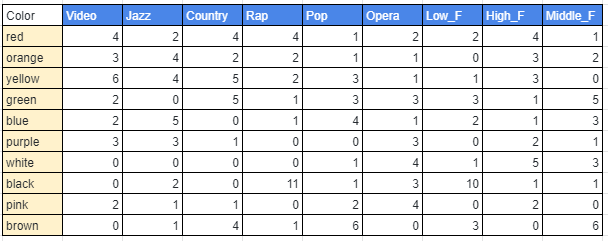
要は、クロス集計表から次のような散布図のグラフを作成するのです。
音楽と色の関係性を示したクロス集計表
音楽と色の関係性を示した散布図
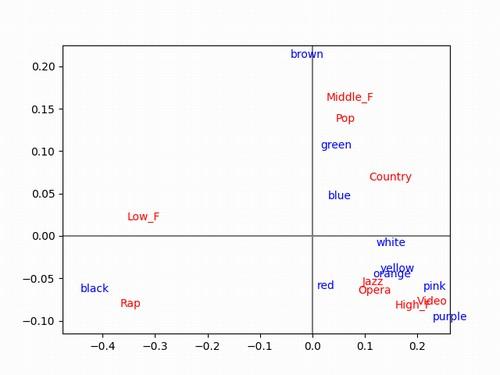
また、クロス集計表には項目がたくさんあります。
当然、複数の説明変数があるということになります。
そこから、多変量解析であることも認識できるでしょう。
とにかく、重要なのはややこしい集計結果を散布図で見やすくしてくれるということです。
コレスポンデンス分析に関しては、これだけ覚えていればいいと思います。
コレスポンデンス分析の用途
主にアンケート結果を視覚化することで利用されています。
やはり、グラフにすると頭の中に入ってきやすいです。
そして、専門用語で言うと、次の用途で利用されています。
- セグメンテーション
- ターゲティング
- ポジショニング
具体的には、自社ブランドと競合ブランド間のポジショニング関係の把握ですね。
つまり、主にマーケティングで利用されるということになります。
ただ、クロス集計表があれば、コレスポンデンス分析が可能です。
また、集計表であるため、大量のデータが必要という訳でもありません、
その点では、比較的容易に実行しやすい分析と言えます。
クロス集計表さえ取得できれば、誰でも簡単に実行可能ということです。
ネットで転がっているクロス集計表でもOKになりますね。
コレスポンデンス分析をPythonで行うための環境を準備する
コレスポンデンス分析をPythonで行うためには、mcaライブラリが必要です。
そこでmcaをインストールしていきます。
※mcaは、Multiple Correspondence Analysisの略。
最初に、現状のインストール済みパッケージを確認しておきます。
>pip list Package Version ---------- ------- pip 21.0.1 setuptools 53.0.0
次にするべきことは、pip自体の更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip
では、mcaのインストールです。
mcaのインストールは、以下のコマンドとなります。
pip install mca
インストールは、若干時間がかかります。
では、どんなパッケージがインストールされたのかを確認しましょう。
>pip list Package Version --------------- ------- mca 1.0.3 numpy 1.20.1 pandas 1.2.1 pip 21.0.1 python-dateutil 2.8.1 pytz 2021.1 scipy 1.6.0 setuptools 53.0.0 six 1.15.0
Pythonを代表する名だたる以下のパッケージが、同時にインストールされました。
- Numpy
- Pandas
- Scipy
mcaは、上記に依存していることがわかります。
以上より、コレスポンデンス分析をPythonで行うための環境が準備できました。
しかし、これだけではちゃんとしたコレスポンデンス分析ができるわけではありません。
この段階でも、分析自体はちゃんとできます。
しかし、コレスポンデンス分析は散布図まで表示してナンボです。
そのため、グラフを表示するための環境が必要なのです。
具体的に言うと、Matplotlibのインストールが必要になります。
Matplotlibのインストールに関しては、次の記事をご覧ください。
「箱ひげ図をPythonで作るための環境を準備する」において、Matplotlibのインストールを解説しています。

では、次にコレスポンデンス分析をPythonで行います。
コレスポンデンス分析をPythonで行う
コレスポンデンス分析をPythonで行っていきましょう。
もちろん、散布図まで作成します。
以下は、上記で出てきた「音楽と色の関係性を示した散布図」を作成するサンプルコードです。
import mca
import matplotlib.pyplot as plt
import pandas as pd
# クロス集計データ取得
data = pd.read_table('./data/music_color.csv', sep=',', skiprows=0, index_col=0, header=0)
# 計算
mca_counts = mca.MCA(data)
# 結果データ抜き出し
# 2次元表示のためN=2まで
rows = mca_counts.fs_r(N=2) # 表側データ
cols = mca_counts.fs_c(N=2) # 表頭データ
# 表側
plt.scatter(rows[:, 0], rows[:, 1], c='b', marker="None")
labels = data.index
for label, x, y in zip(labels, rows[:, 0], rows[:, 1]):
plt.annotate(label, xy=(x, y), c="b")
# 表頭
plt.scatter(cols[:, 0], cols[:, 1], c='r', marker="None")
labels = data.columns
for label, x, y in zip(labels, cols[:, 0], cols[:, 1]):
plt.annotate(label, xy=(x, y), c="r")
# xy軸
plt.axhline(0, color='gray')
plt.axvline(0, color='gray')
# グラフ保存
plt.savefig("test.png")
「music_color.csv」は、公開されているデータです。
https://github.com/esafak/mca/blob/master/data/music_color.csv
特に説明は不要でしょう。
定型化されたコードであり、これを大きく変更する必要もないはずです。
これをもとにして、コレスポンデンス分析をガンガンとやっていきましょう。
そうすれば、グラフの見方もだんだんとわかってくるはずです。

