
私たちの日常生活において、YouTubeは情報源として欠かせない存在になっています。
しかし、動画の情報を文字データとして保存したい場面もしばしばあります。
そこで注目されているのが、OpenAIが開発した最先端の音声認識技術「Whisper」です。
この技術は、動画コンテンツからの音声を正確にテキスト化することで、
コンテンツのアクセシビリティを飛躍的に向上させます。
本記事では、そのための手順を具体的に紹介しています。
本記事の内容
- YouTubeからの音声ダウンロード
- 音声データのテキスト変換
- 動画スクリプトの評価
それでは、上記に沿って解説していきます 。
YouTubeからの音声ダウンロード
YouTubeから音声をダウンロードします。
音声のダウンロードには、yt-dlpを用います。


yt-dlpは、音声だけをダウンロードすることができます。
そのためには、まず以下のコマンドでダウンロード可能なファイル形式を調べます。
yt-dlp --list-formats https://www.youtube.com/watch?v=EmCPHumbMvo
対象の動画は、以下の形をサポートしていることがわかります。
ID EXT RESOLUTION FPS CH │ FILESIZE TBR PROTO │ VCODEC VBR ACODEC ABR ASR MORE INFO ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── sb3 mhtml 48x27 0 │ mhtml │ images storyboard sb2 mhtml 80x45 0 │ mhtml │ images storyboard sb1 mhtml 160x90 0 │ mhtml │ images storyboard sb0 mhtml 320x180 0 │ mhtml │ images storyboard 233 mp4 audio only │ m3u8 │ audio only unknown [ja] Default 234 mp4 audio only │ m3u8 │ audio only unknown [ja] Default 599 m4a audio only 2 │ 2.97MiB 31k https │ audio only mp4a.40.5 31k 22k [ja] ultralow, m4a_dash 600 webm audio only 2 │ 3.11MiB 32k https │ audio only opus 32k 48k [ja] ultralow, webm_dash 139 m4a audio only 2 │ 4.71MiB 49k https │ audio only mp4a.40.5 49k 22k [ja] low, m4a_dash 249 webm audio only 2 │ 4.57MiB 47k https │ audio only opus 47k 48k [ja] low, webm_dash 250 webm audio only 2 │ 5.90MiB 61k https │ audio only opus 61k 48k [ja] low, webm_dash 140 m4a audio only 2 │ 12.50MiB 129k https │ audio only mp4a.40.2 129k 44k [ja] medium, m4a_dash 251 webm audio only 2 │ 12.31MiB 128k https │ audio only opus 128k 48k [ja] medium, webm_dash 597 mp4 256x144 15 │ 3.11MiB 32k https │ avc1.4d400b 32k video only 144p, mp4_dash 602 mp4 256x144 15 │ ~ 9.17MiB 93k m3u8 │ vp09.00.10.08 93k video only 598 webm 256x144 15 │ 2.38MiB 25k https │ vp9 25k video only 144p, webm_dash 394 mp4 256x144 30 │ 6.13MiB 64k https │ av01.0.00M.08 64k video only 144p, mp4_dash 269 mp4 256x144 30 │ ~ 16.83MiB 170k m3u8 │ avc1.4D400C 170k video only 160 mp4 256x144 30 │ 4.70MiB 49k https │ avc1.4D400C 49k video only 144p, mp4_dash 603 mp4 256x144 30 │ ~ 15.77MiB 159k m3u8 │ vp09.00.11.08 159k video only 278 webm 256x144 30 │ 7.79MiB 81k https │ vp09.00.11.08 81k video only 144p, webm_dash 395 mp4 426x240 30 │ 10.66MiB 110k https │ av01.0.00M.08 110k video only 240p, mp4_dash 229 mp4 426x240 30 │ ~ 30.69MiB 310k m3u8 │ avc1.4D4015 310k video only 133 mp4 426x240 30 │ 8.65MiB 90k https │ avc1.4D4015 90k video only 240p, mp4_dash 604 mp4 426x240 30 │ ~ 29.27MiB 296k m3u8 │ vp09.00.20.08 296k video only 242 webm 426x240 30 │ 10.58MiB 110k https │ vp09.00.20.08 110k video only 240p, webm_dash 396 mp4 640x360 30 │ 20.40MiB 211k https │ av01.0.01M.08 211k video only 360p, mp4_dash 230 mp4 640x360 30 │ ~ 79.36MiB 803k m3u8 │ avc1.4D401E 803k video only 134 mp4 640x360 30 │ 21.30MiB 221k https │ avc1.4D401E 221k video only 360p, mp4_dash 18 mp4 640x360 30 2 │ ≈ 34.59MiB 350k https │ avc1.42001E mp4a.40.2 44k [ja] 360p 398 mp4 1280x720 30 │ 68.10MiB 706k https │ av01.0.05M.08 706k video only 720p, mp4_dash 232 mp4 1280x720 30 │ ~254.35MiB 2572k m3u8 │ avc1.4D401F 2572k video only 136 mp4 1280x720 30 │ 76.38MiB 791k https │ avc1.4D401F 791k video only 720p, mp4_dash 609 mp4 1280x720 30 │ ~162.74MiB 1646k m3u8 │ vp09.00.31.08 1646k video only 247 webm 1280x720 30 │ 45.31MiB 469k https │ vp09.00.31.08 469k video only 720p, webm_dash 399 mp4 1920x1080 30 │ 119.99MiB 1243k https │ av01.0.08M.08 1243k video only 1080p, mp4_dash 270 mp4 1920x1080 30 │ ~463.52MiB 4688k m3u8 │ avc1.640028 4688k video only 137 mp4 1920x1080 30 │ 136.53MiB 1415k https │ avc1.640028 1415k video only 1080p, mp4_dash 614 mp4 1920x1080 30 │ ~276.64MiB 2798k m3u8 │ vp09.00.40.08 2798k video only 248 webm 1920x1080 30 │ 118.05MiB 1223k https │ vp09.00.40.08 1223k video only 1080p, webm_dash 616 mp4 1920x1080 30 │ ~569.57MiB 5760k m3u8 │ vp09.00.40.08 5760k video only Premium
高品質なm4a形式のID「140」をダウンロードします。
そのためのコマンドは、以下。
yt-dlp -o EmCPHumbMvo.m4a -f 140 https://www.youtube.com/watch?v=EmCPHumbMvo
上記コマンドを実行すると、数秒でダウンロードできます。
ファイル名は、指定した「EmCPHumbMvo.m4a」で保存できています。
再生時間は、約13分30秒となります。
音声データのテキスト変換
音声をテキストに変換しましょう。
その際に、Faster Whisperを利用します。

Faster Whisperであれば、最も精度の高いlarge-v3でも動く可能性があります。
GPUが8GBあれば、なんとか動くと言われています。
そのFaster Whisperを用いたコードは、以下となります。
from faster_whisper import WhisperModel
model_size = "large-v3"
# Run on GPU with FP16
model = WhisperModel(model_size, device="cuda", compute_type="float16")
# or run on GPU with INT8
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16")
# or run on CPU with INT8
# model = WhisperModel(model_size, device="cpu", compute_type="int8")
# ダウンロードした音声ファイルを指定
segments, info = model.transcribe("EmCPHumbMvo.m4a", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
# ファイルに追記するために開きます
with open("transcription.txt", "a") as file:
for segment in segments:
# segment.start, segment.end, segment.text の各部分を改行しながらファイルに追記します
# file.write("[%.2fs -> %.2fs] %s\n" % (segment.start, segment.end, segment.text))
file.write(segment.text + "\n") # 各セグメントのテキストの後に改行を追加
各自のマシンスペックに応じて、動作タイプを選択してください。
- GPU with FP16
- GPU with INT8
- CPU with INT8
コードを実行すると、少し待たされます。
RTX 3090(24GB)だと、130秒ほどかかっています。
CPUも影響してくるので、一概にGPUだけは語れませんけどね。
とりあえず、約13分30秒の音声は2分ちょっとぐらいという結果です。
動画のスクリプトは、「transcription.txt」に保存されています。
動画スクリプトの評価
まずは、「transcription.txt」の内容を確認してみてください。
完璧とは言い切れませんが、十分なレベルだと思います。
人間の主観ではなく、ここは冷静沈着なAIに判断してもらいましょう。
そのためには、ChatGPTに次のように入力するだけです。
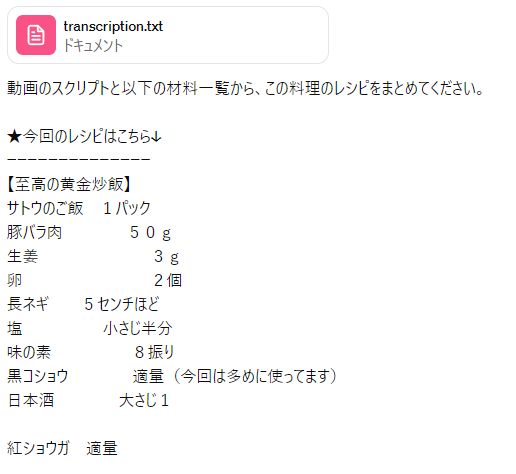
その返答は、以下。

これらに加えて、ポイントも教えてくれています。

ここまでレシピを構成できるということは、スクリプトは問題ないと言えそうです。
最後は、実際に動画と見比べて判断してみてください。

