
食べログをWebスクレイピングしていきます。
取得するデータは、ランキングです。
本記事の内容
- スクレイピングをやる前に
- 食べログの利用規約を確認する
- 食べログのランキング一覧のスクレイピング仕様
- 食べログのランキング一覧からデータを抽出する
それでは、上記に沿って解説していきます。
スクレイピングをやる前に
スクレイピングは、危険な技術です。
そのため、プログラムの初心者が何もわからずに実行してはいけません。
何もわからずに適当にスクレイピングをするとどうなってしまうのでしょうか?
最悪、刑事告訴されてしまいます。
そうです、犯罪者になってしまう可能性があるのです。
民事だけで済まないと言えます。
上記より、スクレイピングにリスクがあることを理解できたでしょうか?

理解が甘いと自覚する方は、是非とも上の記事をご覧ください。
その中の「【必須】Webスクレイピングに関する考え方」だけでも読んでください。
あと、スクレイピングを行う環境が必要です。
環境の準備には、上の記事内の「メルカリをスクレイピングするための準備」を参考にしてください。
食べログの利用規約を確認する
食べログ利用規約
http://user-help.tabelog.com/rules/
一通り確認しても、スクレイピングを禁止する記載がありません。
食べログ側は、スクレイピング上等というスタンスなのかもしれません。
実際、利用規約でスクレイピングを禁止したところで意味はありません。
利用規約は、あくまでサイト側が勝手に書いていることです。
そもそも、利用規約に同意しなければ利用規約なんて無効なのです。
ただ、ログインした状態でスクレイピングするとその理屈は通りません。
そもそも、アカウント登録時点で利用規約に同意していますからね。
そして、利用規約に違反した場合は、アカウント停止・削除を受け入れるしかありません。
利用規約に同意しなければ何をしてもよいのでしょうか?
もちろん、それも違います。
そもそも、利用規約以前に私たちは法律を守らないといけません。
法律は、利用規約と違って同意もなしに適用されます。
そのため、法律違反は絶対にやってはいけません。
著作権、個人情報、業務妨害(短時間の大量アクセス)などに関しては、常に意識しておきましょう。
このことは、スクレイピングだけにおけることではありません。
ブログを書いたり、SNSで投稿する場合でも、常に意識しておくべきことなのです。
以上、食べログの利用規約の確認でした。
次では、食べログのランキングページをスクレイピングする上での仕様(考え方)を説明します。
食べログのランキング一覧のスクレイピング仕様
食べログにおけるランキングページは、スクレイピングがやりやすいです。
スクレイピングする側からすれば、ありがたい作りとなっています。
と言うより、普通にシステムを設計すればそのようになります。
統一したレイアウト(内部プログラム)でないと、保守コストが上がってしまいます。
3つランキングページをピックアップ。
全国の全ジャンルのランキングページ
https://tabelog.com/rstLst/?Srt=D&SrtT=rt&sort_mode=1
京都駅周辺の全ジャンルのランキングページ
https://tabelog.com/kyoto/A2601/A260101/R3313/rstLst/?SrtT=rt&Srt=D&sort_mode=1
東京駅のタイ料理のランキングページ
https://tabelog.com/tokyo/A1302/A130201/R6586/rstLst/thai/?SrtT=rt&Srt=D&sort_mode=1
すべて同じレイアウトですよね。
つまり、すべて同じタグ構造と言うことになります。
あとは、改ページに関して説明しておきます。
改ページは、「次の20件」リンクをクリックすることで対応します。

正確には、以下の「c-pagination__arrow–next」を持つaタグをクリックします。

なお、最大で60ページまでしか表示できない仕様のようです。
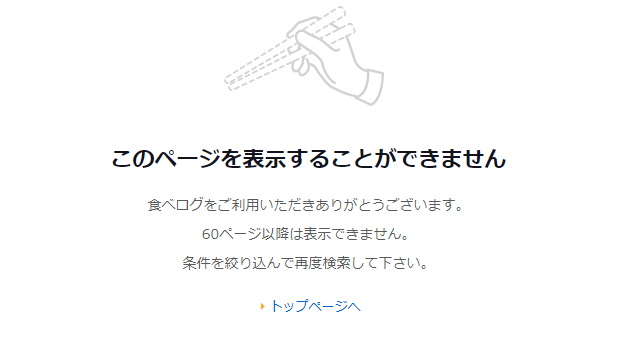
実際に必要なランキングは、場所やジャンルで条件を絞り込むはずです。
そのため、60ページもあれば十分なのでしょう。
1ページに20店も表示するため、最大で1200個表示できます。
普通は、これだけあれば十分でしょう。
最大で60ページの改ページ処理であれば、同一プログラム内のfor文でぶん回しましょう。
以上で方向性は決まりました。
では、実際にランキングページをスクレイピングしていきましょう。
食べログのランキング一覧からデータを抽出する
「梅田の居酒屋」のランキングを取得します。
https://tabelog.com/osaka/A2701/A270101/rstLst/izakaya/?Srt=D&SrtT=rt&sort_mode=1
2021年2月7日時点では、合計で1404件あります。
ということは、最大で60ページまでしか取得できないはずです。
そのような動きをするプログラムが以下のコードとなります。
サンプルコード
import bs4
import traceback
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
# ドライバーのフルパス
CHROMEDRIVER = "chromedriver.exeのパス"
# 改ページ(最大)
PAGE_MAX = 3
# 遷移間隔(秒)
INTERVAL_TIME = 3
# ドライバー準備
def get_driver():
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
# 対象ページのソース取得
def get_source_from_page(driver, page):
try:
# ターゲット
driver.get(page)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
page_source = driver.page_source
return page_source
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# ソースからスクレイピングする
def get_data_from_source(src):
# スクレイピングする
soup = bs4.BeautifulSoup(src, features='lxml')
try:
info = []
elems = soup.find_all(class_="list-rst")
for elem in elems:
shop = {}
shop["rank"] = None
shop["name"] = None
shop["area"] = None
shop["genre"] = None
shop["star"] = None
shop["rvw_count"] = None
shop["dinner_budget"] = None
shop["lunch_budget"] = None
shop["holiday_data"] = None
shop["search_word"] = None
# 順位
rank = elem.find(class_="list-rst__rank-badge-no").text
if rank:
shop["rank"] = rank
# 店舗名
name = elem.find(class_="list-rst__rst-name-target").text
if name:
shop["name"] = name
# 地域とジャンル
area_genre = elem.find(class_="list-rst__area-genre").text
if area_genre:
area_genre_list = area_genre.split("/")
if len(area_genre_list) == 2:
shop["area"] = my_trim(area_genre_list[0])
tmp_genre = area_genre_list[1]
tmp_genre_list = tmp_genre.split("、")
genre_list = []
for genre in tmp_genre_list:
genre_list.append(my_trim(genre))
shop["genre"] = genre_list
# 評価
star = elem.find(class_="list-rst__rating-val").text
if star:
shop["star"] = star
# 評価
rvw_count = elem.find(class_="list-rst__rvw-count-num").text
if rvw_count:
shop["rvw_count"] = rvw_count
# 予算
budget_elems = elem.find_all(class_="list-rst__budget-val")
if len(budget_elems) == 2:
shop["dinner_budget"] = budget_elems[0].text
shop["lunch_budget"] = budget_elems[1].text
# 休日
if elem.find(class_="list-rst__holiday"):
holiday_data = elem.find(class_="list-rst__holiday-datatxt").text
if holiday_data:
shop["holiday_data"] = holiday_data
# 検索キーワード
search_word_elems = elem.find_all(class_="list-rst__search-word-item")
if len(search_word_elems) > 0:
search_word_list = []
for search_word_elem in search_word_elems:
search_word = search_word_elem.text
if my_trim(search_word):
search_word_list.append(my_trim(search_word))
shop["search_word"] = search_word_list
# 画像
if elem.find(class_="list-rst__rst-photo"):
photo_set_str = elem.find(class_="list-rst__rst-photo").attrs['data-photo-set']
if photo_set_str:
tmp_photo_set = photo_set_str.split("、")
img_list = []
for img in tmp_photo_set:
img_list.append(img)
shop["img"] = img_list
info.append(shop)
return info
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# 次のページへ遷移
def next_btn_click(driver):
try:
# 次へボタン
elem_btn = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.CLASS_NAME, "c-pagination__arrow--next"))
)
actions = ActionChains(driver)
actions.move_to_element(elem_btn)
actions.click(elem_btn)
actions.perform()
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
return True
except Exception as e:
print("Exception\n" + traceback.format_exc())
return False
def my_trim(text):
text = text.replace("\n", "")
return text.strip()
if __name__ == "__main__":
# 対象ページURL
page = "https://tabelog.com/osaka/A2701/A270101/rstLst/izakaya/?Srt=D&SrtT=rt&sort_mode=1"
# ブラウザのdriver取得
driver = get_driver()
# ページのソース取得
source = get_source_from_page(driver, page)
result_flg = True
# ページカウンター制御
page_counter = 0
while result_flg:
page_counter = page_counter + 1
# ソースからデータ抽出
data = get_data_from_source(source)
# データ保存
print(data)
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
# 改ページ処理
result_flg = next_btn_click(driver)
source = driver.page_source
# 閉じる
driver.quit()
プログラムの詳細は、ここでは説明しません。
「食べログのランキング一覧のスクレイピング仕様」とコメントを参考にしてください。
それらを参考にすれば、わかるレベルのプログラムだと思います。
そうじゃないと、サンプルコードは動かさないでください。
理解して動かさないと、スクレイピングはリスキーだとお伝えした通りです。
また、Seleniumの関数などは、Selenium公式を参考にしてください。
ただ、Selenium特有の部分は関数に閉じ込めています。
そのため、実はSeleniumのことを意識する必要はないのです。
以下の部分だけは、説明しておきます。
# ドライバーのフルパス CHROMEDRIVER = "chromedriver.exeのパス" # 改ページ(最大) PAGE_MAX = 3 # 遷移間隔(秒) INTERVAL_TIME = 3
CHROMEDRIVERは、ドライバーのパスを設定します。
「ドライバー?」という方は、次の記事をご覧ください。

PAGE_MAXとINTERVAL_TIMEに関しては、次の記事を参考にしてください。
全く同じ使い方をしています。
実行結果
上記のサンプルコードを実行した結果は、以下。
多すぎてすべては表示できませんので、TOP3だけ表示。
このような形のデータを3ページ分(60件)抽出できます。
60ページではなく3ページなのは、PAGE_MAXの設定が「3」だからです。
私は、この値を適当に「100」にしてプログラムを動かしました。
その結果、予想通りに60ページでプログラムは終わりました。
61ページ目にアクセスすると、get_source_from_page関数で例外エラーが出ました。
具体的には、次の部分ですね。
print("Exception\n" + traceback.format_exc())
プログラムがエラーで落ちることはないので、無視してもいいです。
無視するのが気持ち悪い人は、適当なコードを書いてください。
まとめ
スクレイピングしたデータを保存したい場合、次の部分を触ってください。
# データ保存 print(data)
これも先ほど紹介した「メルカリをPythonでWebスクレイピングする【商品IDの抽出】」の記事内で説明しています。
詳細はそちらをご覧ください。
さて、この記事内で次のように述べたのを覚えていますか?
「食べログにおけるランキングページは、スクレイピングがやりやすいです。」
本当かどうかは、各自でランキングの条件を変えて試してみてください。

