「Waifu Diffusionをdepth2imgに利用したい」
「img2imgでポーズが崩れるのをなんとかしたい」
このような場合には、この記事の内容が参考になります。
この記事では、Waifu Diffusion 1.4を使ったdepth2imgの実現方法を解説しています。
本記事の内容
- depth2imgが可能なモデルは少ない
- Waifu Diffusion 1.4をマージしたdepth2img用モデルの作成
- 作成したdepth2img用モデルの利用
- 作成したdepth2img用モデルの検証結果
それでは、上記に沿って解説していきます。
depth2imgが可能なモデルは少ない
depth2imgについて、よくわからない場合は次の記事をご覧ください。

2023年1月末時点では、depth2imgが可能なモデルは少ないです。
と言うか、基本的には一つしかありません。
その一つというのが、Stability AI社が公開しているモデル(stable-diffusion-2-depth)です。
https://huggingface.co/stabilityai/stable-diffusion-2-depth
別に、stable-diffusion-2-depthが使えないという訳ではありません。
ただ、アニメキャラで表現しようとすると違和感の多い画像が生成されます。
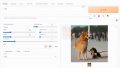
例えば、stable-diffusion-2-depthを利用すると次のような画像が生成されます。

左の画像が入力画像です。
そして、右の画像がdepth2imgによって生成された画像になります。
一応、謝罪のポーズは取っている感じには見えます。
でも、無表情で謝る気がゼロです。
それに、今風のアニメでもないように感じます。
depth2imgには大きな可能性があるのに、これでは勿体ない。
実際、depth2imgはそこまで流行ってませんよね。
もしdepth2imgで次のような謝罪画像を生成できたら、もっと利用する人は増えると思いませんか?

こっちの男性たちは、謝罪する気持ちがあるように見えます。
それに、イケメンも混ざっています。
え?男の謝罪なんて興味がありませんか・・・
では、女性たちの謝罪はどうでしょうか?

と、こんな感じで一気にdepth2imgは使える(遊べる)モノになります。
それを可能にした開発者の方がいます。
以下ページでその理論や方法が記載されています。
https://zenn.dev/discus0434/articles/ef418a8b0b3dc0
正直、内容は難しいです。
興味のある方には、面白い内容かもしれません。
開発された方は、たまたま見つけた方法が上手くいったと言っています。
でも、普段から問題意識を持っているからこそ、そのような発見に結び付くのでしょうね。
以上、depth2imgが可能なモデルは少ないことについて説明しました。
次は、Waifu Diffusion 1.4をマージしたdepth2img用モデルの作成を説明します。
Waifu Diffusion 1.4をマージしたdepth2img用モデルの作成
depth2img用モデルの作成方法は、紹介した記事に記載されています。
モデル生成用のコードも公開されています。
そのコードを若干変更しています。
Waifu Diffusionに特化した変数名・コメントを、汎用的にしています。
あとは、生成されるモデル名が自動的に決まるように変更したぐらいです。
そうやって出来上がったコードは、以下。
make_depth_model.py
import copy
import torch
import os
base_path = "512-base-ema.ckpt"
depth_path = "512-depth-ema.ckpt"
target_path = "wd-1-4-anime_e2.ckpt"
# save path
depth_target_path = "depth-" + os.path.basename(target_path)
base = torch.load(base_path)
depth = torch.load(depth_path)
target = torch.load(target_path)
# make task vector
task_target = copy.deepcopy(target)
for key in set(target["state_dict"].keys()):
if "model.diffusion_model" in key:
task_target["state_dict"][key] = target["state_dict"][key] - base["state_dict"][key]
for key in set(depth["state_dict"].keys()) & set(task_target["state_dict"].keys()):
# replace weight of VAE with target's weight
if "first_stage_model" in key:
depth["state_dict"][key] = task_target["state_dict"][key]
# don't replace weight of an input block whose dimension is different from each other
elif "model.diffusion_model.input_blocks.0.0" in key:
pass
# add task weight to unet layers
elif "model.diffusion_model" in key:
task_depth = depth["state_dict"][key] - base["state_dict"][key]
depth["state_dict"][key] = base["state_dict"][key] + (task_depth * 0.5 + task_target["state_dict"][key] * 0.5)
torch.save(depth, depth_target_path)
上記コードを動かすには、各モデルのcheckpointが必要になります。
それぞれのダウンロード先を載せておきます。
512-base-ema.ckpt
https://huggingface.co/stabilityai/stable-diffusion-2-base/tree/main
512-depth-ema.ckpt
https://huggingface.co/stabilityai/stable-diffusion-2-depth/tree/main
wd-1-4-anime_e2.ckpt
https://huggingface.co/hakurei/waifu-diffusion-v1-4/tree/main
ダウンロードして設置できたら、スクリプトを実行しましょう。
処理が完了するには、少し時間がかかります。
処理が完了したら、「depth-wd-1-4-anime_e2.ckpt」というファイルを確認できます。
これが、Waifu Diffusion 1.4をマージしたdepth2img用モデルになります。
スクリプトに関して、一つ注意点があります。
このコードは、Stable Diffusion 2.0のモデルがベースになっています。
Waifu Diffusion 1.4は、Stable Diffusion 2.0をファインチューニングしています。
よって、Stable Diffusion 2.1をファインチューニングしたモデルは対象外です。
何個か試しましたが、機能しませんでした。
もう少し、検証はしてみます。
そうは言っても、Stable Diffusion 2.0・2.1をベースにしたモデルはまだまだ数が少ないのですけどね。
以上、Waifu Diffusion 1.4をマージしたdepth2img用モデルの作成を説明しました。
次は、作成したdepth2img用モデルの利用を説明します。
作成したdepth2img用モデルの利用
現状では、AUTOMATIC1111版web UIでしか動かすことができません。
Diffusersで動かす方法を調査していますが、まだ見つかりません。
では、作成したdepth2img用モデルをAUTOMATIC1111版web UIで利用していきましょう。
「depth-wd-1-4-anime_e2.ckpt」は、Stable Diffusion 2.0ベースのモデルになります。
そのため、YAMLファイルが必要になります。
ただし、通常モデルのYAMLファイルとは異なることに注意しましょう。
つまり、depth用モデルのconfig(YAMLファイル)があるということです。
https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-midas-inference.yaml
「stable-diffusion-2-depth」を動かしたときにも、同じ作業をしているはずですけどね。
作業の結果、checkpointの保存場所に次の二つのファイルを設置すれば準備OKとなります。

準備ができたら、AUTOMATIC1111版web UIで普通に「img2img」を実行するだけです。
以上、作成したdepth2img用モデルの利用を説明しました。
最後に、作成したdepth2img用モデルの検証結果を説明します。
作成したdepth2img用モデルの検証結果
正直、意味不明の結果となりました。
言葉で説明するよりも、実際の結果を見た方がわかると思います。
【用語】
- デフォルトdepthモデル(512-depth-ema.ckpt)
- 自作depthモデル(depth-wd-1-4-anime_e2.ckpt)
まずは、次の画像を両方のdepthモデルでdepth2imgしました。
プロンプトは、以下で統一しています。
masterpiece, best quality, high quality,anime
ネガティブプロンプトは、Waifu Diffusionで提供されているモノを利用。

デフォルトdepthモデルの結果

自作depthモデル

基本的には、出力された画像は特に選んではいません。
よほど崩れた画像以外は、そのまま載せています。
この結果を見る限りでは、自作depthモデルの方が入力画像の深度情報を維持できています。
人物の形状・姿勢を適切に反映できているということです。
もちろん、キャラクターの見た目も自作depthモデルの方がイケてます。
次は、顔を中心とした寄りの画像を入力画像とします。

デフォルトdepthモデルの結果

自作depthモデル

確かに、先ほどよりは深度情報を維持に関しては差がなくなりました。
しかし、それでも自作depthモデルの方が上手く形状・姿勢を保持できています。
もちろん、見た目もいい感じです。
どうでしょうか?
意味不明の結果と言った理由が、わかったでしょうか?
検証する前、私は次のような仮説(偏見)を持っていました。
「自作depthモデルは深度情報の処理レベル(以下depthレベルと呼ぶ)が下がるはずだ」
私は、このような固定概念を持って検証を行っていました。
マージして、アニメ描画に強くなった分だけ、depthレベルは下がるはずですよね?
そうではなく、デフォルトdepthモデルよりもさらにdepthレベルがアップしているのです。
どうして、そんな結果になるのでしょうか・・・
何か大きな勘違いをしている可能性が大いにあります。
そのため、このdepthレベルの内容については話半分で受け取ってください。
最後に、プロンプトによる可能性を探ってみましょう。
プロンプトに以下を追加して、モデルの伸びしろを確認しようということです。
,kawaii princess, white glowing skin, kawaii face with blush, blue eyes
変更したプロンプトを用いて、生成された画像は以下。
上半分がデフォルトdepthモデル、下半分が自作depthモデルです。

比較しやすいように、それぞれSEED固定で生成しています。
ここで一気に、キャラの見た目でも差が付きました。
プロンプト次第で、その差はさらに拡大する可能性があります。
仮にdepthレベルの検証結果が正しければ、自作depthモデルの威力は半端ないですね。
以上、作成したdepth2img用モデルの検証結果を説明しました。