
非構造化データは、テキスト、画像、音声など、定義された形式がないデータのことを指します。
このようなデータは情報量が豊富である一方で、その扱いはしばしば複雑です。
Pythonのunstructuredライブラリは、非構造化データを簡単かつ効率的に扱うためのツールを提供します。
そのため、データ分析や機械学習プロジェクトにおいて重宝されます。
本記事の内容
- unstructuredとは?
- unstructuredのインストール
- unstructuredの動作確認
それでは、上記に沿って解説していきます。
unstructuredとは?
unstructuredは非構造化データを扱うためのPythonライブラリです。
テキスト、画像、音声など、あらゆる形式の非構造化データの操作を簡単にするために設計されています。
このライブラリは、機械学習やデータ分析プロジェクトにおいて非常に有用であり、
非構造化データから価値ある情報を効率的に抽出する手助けをします。
データの読み込み、前処理、分析を行うための豊富な機能が備わっています。
それにより、開発者が複雑なデータ処理タスクを容易に、そして迅速に実施できるようにします。
unstructuredのインストール
現時点におけるunstructuredの最新バージョンは、以下となります。
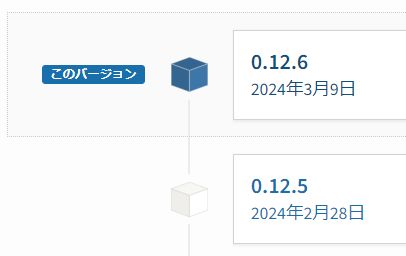
更新頻度は高く、よくメンテナンスされています。
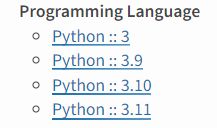
システム要件としては、Python 3.9以降とあるぐらいです。
OSは、問わずにWindowsでもmacOSでもインストール可能になります。
もちろん、Linuxにもインストール可能です。
インストールするには、次のコマンドを実行します。
pip install unstructured
ただし、上記でインストールした場合は以下のファイルのみが扱える対象になります。
- plain text files
- HTML
- XML
- JSON
- Emails
出来る限り多くのファイルを処理したい場合は、以下のコマンドを用います。
pip install "unstructured[all-docs]"
そうすると、以下のファイルを扱えるようになります。
"csv", "doc", "docx", "epub", "image", "md", "msg", "odt", "org", "pdf", "ppt", "pptx", "rtf", "rst", "tsv", "xlsx"
ただ、Pythonが動く環境でそれぞれのファイルを処理できることが前提です。
そのため、Windowsでフルに対応しようとなると、結構大変な作業になります。
フルで対応する方法は、以下のページで解説があります。

大変な作業であるためなのか、Dockerを利用したインストールが提供されています。

とりあえず、まずデフォルトのインストールをオススメします。
必要になれば、その都度対応すれば良いと思います。
unstructuredの動作確認
デフォルトで取得可能なHTMLを対象に動作確認を行います。
以下は、サイトからページの内容を取得するサンプルコードです。
from unstructured.partition.html import partition_html
url = "https://www.cnn.co.jp/fringe/35216284.html"
elements = partition_html(url=url)
print("\n\n".join([str(el) for el in elements]))
上記を実行すると、該当するページの記事内容が取得できています。
該当ページのようにarticleタグがあれば、その要素内のテキストを取得しています。

articleタグがない場合は、bodyタグの中身を全部取るようです。
例えば、Example Domain(https://example.com/)のソースは以下となっています。

このページを対象とした場合、次のような結果となります。

でも、全然十分ですね。
unstructuredを用いれば、スクレイピングを自分で行う必要がなくなります。
確かに、これは便利です。

