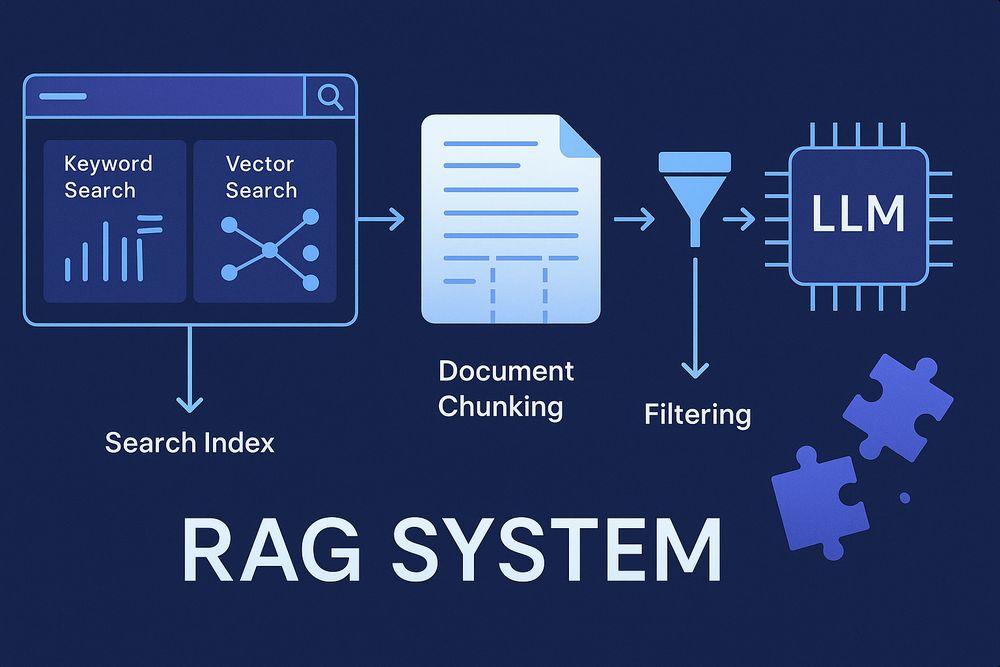
近年、検索拡張生成(Retrieval-Augmented Generation:RAG)システムは、大規模言語モデル(LLM)の能力を高める重要な技術として注目を集めています。
RAGを使えば、LLMが持つ知識を外部の情報源で補完できます。
そして、より正確で最新の回答を生成できるようになります。
今回は、Redditで共有された個人プロジェクトの経験から得た知見をベースに、RAGシステム構築のポイントを解説します。
大企業のような膨大なリソースがなくても、特定のデータセットに焦点を当てた高精度なRAGシステムを作れます。
キーワード検索とベクトル検索の両方が不可欠
RAGシステムを構築する際、よく見落とされるのがキーワード検索の重要性です。
ベクトル検索だけでは不十分な場合が多いのです。
特に科学的なクエリでは、遺伝子名や疾病名、薬剤名などの正確な名称を扱うことが多くあります。
このとき、ベクトル検索だけでは関連する結果を見逃すことがあります。
短いクエリの場合は特に注意が必要です。
ベクトル検索のみを使うと、完全に無関係な結果が返ってくることも珍しくありません。
両方の検索手法を組み合わせると、検索精度が大幅に向上します。
最新の埋め込みモデルを使用している場合でも、キーワード検索との併用が効果的なのです。
クエリの再構成が検索品質を向上させる
短いクエリを自動的に拡張すると、検索品質を簡単に向上できます。
例えば「X」という単純なクエリを「Xとは何か」に再構成するだけで、検索結果が劇的に改善することがあります。
この手法は、LLMを使わずとも実装可能です。
また、より高度なアプローチもあります。
LLMを活用して関連クエリやキーワードを生成し、それぞれでベクトル検索と全文検索を行います。
そして、それらの結果をマージすることも効果的です。
チャンクとデータベースにはコンテキストを含める
テキストを分割(チャンキング)する際は、コンテキストの保持が重要です。
全レベルの見出しを再帰的にチャンクに含めると、文脈の損失を防げます。
容量が許せば、前のチャンクの要約も含めるとより効果的です。
時間に関連するドキュメントでは、年代情報も重要なコンテキストになります。
また、利用可能ならタグ情報も含めるべきでしょう。
これらのコンテキスト情報が、検索精度と回答の質を大きく向上させるのです。
フィルタは次のステップとして不可欠
RAGシステムを拡張していくと、検索範囲を制限する必要性にすぐに気づくでしょう。
ベクトル検索だけで完璧に動作すると期待するのは現実的ではありません。
ユーザーは多くの場合、様々な条件でフィルタリングされた結果を求めます。
このような条件をチャンクに埋め込むと、ソフトフィルタリングが可能になります。
そして、SQLなどのデータベースでハードフィルタリングを実現できます。
フィルタの適用方法は二通りあります。
ユーザーが明示的に指定する場合と、LLMがクエリから導き出す場合です。
最適な結果を得るには、両方の方法を組み合わせることが多いでしょう。
複数レベルでのリランキングが価値ある
リランキングは効果的な戦略です。
データセット全体を再インデックス化することなく、ドキュメントを強化・拡張して再順序付けできます。
単にオリジナルのチャンクだけでなく、さらに工夫することも可能です。
ドキュメントのチャンクを集めて単一のドキュメントに結合します。
そして、これらの大きなドキュメントをリランキングすると品質が向上します。
基本的な検索品質が適切であれば、リランカーを使うことで高品質なシステムを構築できます。
Googleのような大規模な検索エンジニアチームがなくても実現可能です。
重要なケースを測定してテストする
ベクトル検索やLLMを扱うと、主観と客観のギャップに悩むことがあります。
主観的に「良くなった」と感じても、客観的にはそうでないことがよくあるのです。
特定のケースを修正したら、それをテストケースとして追加しておきましょう。
次に別の問題を解決しようとした際、これらのテストが役立ちます。
改善方向が正しいかどうかを確認できるからです。
継続的なテストと測定が、長期的な品質向上の鍵です。
多様性が重要
プロンプトに重複したドキュメントを含めるのはトークンの無駄です。
チャンクの多様性を確保しましょう。
既に埋め込みベクトルがあるなら、クラスタリング技術を活用できます。
DBSCANなどを使って類似コンテンツをグループ化します。
そして、各グループから代表的なチャンクを選べば多様性を確保できます。
これにより、LLMが生成する回答の幅と深さが向上するでしょう。
RAGの品質目標は従来の検索とは異なる
エージェント型のアプローチが近い将来主流になるでしょう。
LLMが検索の主要ユーザーになりつつあり、これに適応する必要があります。
LLMはクエリを再構成します。
また、スペルミスを修正したり、クエリを小さな部分に分解したりします。
こうした特性を踏まえた設計が重要です。
あなたの検索エンジンは「Xとは何か」や「Yはいつ起きたか」といった単純なクエリを効果的に処理する必要があります。
論理的な推論はAIが行います。
そして、検索エンジンは事実を提供します。
多様な出力の提供も重要です。
また、ドキュメントの信頼性に関するヒントも含めましょう。
様々なコンテキストサイズへの対応も求められます。
もはや単一の最も関連性の高い回答を上位に配置することだけを優先する必要はありません。
この変化はある意味で救いです。
エージェント向けの検索エンジンを構築する方が、おそらく容易な課題だからです。
RAGは細部の積み重ね、LLMはわずか5%
RAGシステム構築の時間の大半は、地道な作業に費やされます。
パイプラインの修正、ステップ順序の調整、基礎クエリのチューニング、JSONのフォーマットなど、細かな作業が中心です。
検討すべき細かな点は多岐にわたります。
- 様々な検索結果をどう統合するか
- 見つかったドキュメントから追加のチャンクをどう取得するか
- ソースごとに取得するチャンク数はいくつにすべきか
- 同じドキュメントからのチャンクのスコアをどう組み合わせるか
- 埋め込み前にドキュメントから句読点を削除すべきか
- 表をどう処理してチャンク化するか
- 重複除去のパラメータはどうすべきか
新しいプロンプトを作成することは、作業の中で最も楽しい部分です。
しかし、実は最も小さな部分にすぎません。
RAGシステムの構築は、無数の細部への緻密な注意が必要なのです。
まとめ
RAGシステムの構築は、細部への注意と実験的アプローチの繰り返しです。
キーワード検索とベクトル検索の組み合わせは基本です。
そして、クエリの再構成、コンテキストの保持、適切なフィルタリング、リランキング、継続的なテスト、多様性の確保などが重要になります。
LLMモデルの選択や設定はもちろん重要です。
しかし、それ以上に検索品質とパイプラインの最適化が全体の性能を左右します。
単に最新のモデルを使うだけでは不十分です。
システム全体の調和が重要なのです。
このReddit投稿から学んだように、自分だけのRAGシステムを構築することで、LLMの能力を最大限に引き出せます。
そして、特定の分野での専門性を高められるでしょう。
大企業の膨大なリソースがなくても、適切な設計と細部への注意により、高品質なRAGシステムを構築できるのです。