
Webプログラミングのスキルを鍛えるには、スクレイピングはもってこいの題材です。
本ブログでは、すでに多くのサイトのスクレイピング攻略を解説してきました。
以下は、その一部です。



そして、今回はInstagramということになります。
正直、Instagramにはあまり興味はありません。
でも、Instagramの技術的な部分には興味を持ちました。
詳細を書くと長くなるので、一言で言います。
「スクレイピングがやりにくい」
そのため、攻略する方法を検証しました。
その結果、とりあえずはスクレイピングできることを確認できました。
本記事では、この攻略方法を解説していきます。
本記事の内容
- Instagramの規約を確認する
- Instagramのスクレイピング仕様(考え方)
- Instagramをスクレイピングするサンプルコード
それでは、上記に沿って解説を行っていきます。
Instagramの規約を確認する
まずは、Instagramの規約を確認しましょう。
主にスクレイピングに関するところですね。
Instagramの利用規約上では、「スクレイピング」というキーワードは見つかりませんでした。
検索しても何も表示されないということです。
スクレイピングに近い意味の内容は、以下が見つかりました。

「自動化された手段」を用いて「情報を取得したりする行為」という箇所です。
それ以外は、見つけることができませんでした。
とりあえず、Instagramはスクレイピングを利用規約で禁止していると言えます。
では、その利用規約に違反していいのでしょうか?
はい、問題ありません。
当ブログでは、「スクレイピング自体は問題ではない」と常に主張しています。
問題は、スクレイピングを行う際に短時間で過度なアクセスをすることです。
これが過度になり過ぎると、サーバーへの攻撃へとなりかねないのです。
Dos攻撃とかF5アタックと同じですね。
そのため、過度なアクセスでサーバーへ負荷を与えなければ、何も問題はありません。
例えば、ページへアクセスする間隔を1秒以上空けるなどすれば十分です。
あと、スクレイピング云々以前に法律は守りましょう。
これは、ここで言うまでもないことです。
法的に問題なくても、「利用規約で禁止しているぞ!!」と思う方もいるでしょう。
利用規約違反は問題ありません。
利用規約は民間の一企業が定めたルールに過ぎません。
そのため、法的にアウトではない規約違反なんて何も怖くありません。
せいぜいアカウントが停止される程度ですね。
普通は、スクレイピングする際にログインはしません。
そのため、アカウントとスクレイピング元を関連付けるのは困難です。
よって、アカウントの停止は現実的ではないでしょう。
IPで関連付けることも不可能ではありませんが、無理がありますね。
プロキシを使えばIPなんて、あまり意味のないモノになりますので。
以上より、法律さえ守ればスクレイピングは何も問題ないのです。
Instagramのスクレイピング仕様(考え方)
ここでは、技術的な内容に入っていきます。
そこまで、複雑なことは説明しませんので安心してください。
Instagramは、スクレイピングするのは容易ではありません。
昨年までは、比較的に簡単にできていたようですが。
できていたと言っても、本当はその時点でも難しかったのです。
この時点で意味不明となるかもしれません。
そこで、先に簡単にInstagramのデータ表示の仕組みを説明します。
Instagramのデータ表示の仕組み
例えば、「コロナ」というハッシュタグで調べた件数が100件だったとします。
その場合、最初の10件はhtmlソース上にjsonとして表示されています。
このhtmlソース上のjsonには、総件数も入っています。
そのjsonをもとにJavaScriptが10件の投稿を表示します。
この状態でユーザーが画面をスクロールすると、次の10件(件数は適当)が表示されます。
もちろん、このとき次の10件分のデータはhtmlソース上にはありません。
これを非同期(で取得・表示する)コンテンツと言います。
以上が、Instagramにおけるデータ表示の仕組みです。
そして、簡単・困難と言っているのは、最初の10件の取得部分に関してとなります。
次の10件を取得するのは、以前から困難でした。
以前は簡単だった
以前は、次のPythonコードでスクレイピングできていました。
res = requests.get(url) html = BeautifulSoup(res.content, 'html.parser')
「Instagram スクレイピング」でGoogleで検索すると、よく目にするコードです。
現在は、このコードではスクレイピングできません。
なお、このコードでスクレイピングできていたなら、PHPでもスクレイピングはできていたはずです。
現在は簡単ではない
現在(2020年9月19日時点)は、Seleniumを使う必要があります。
Seleniumに関しては、次の記事をご覧ください。

簡潔に言うと、「ブラウザを経由(操作)しないとスクレイピングできなくなった」ということです。
おそらく、アクセスしてきたモノがブラウザかどうかをチェックしているのでしょう。
このことは、Instagramに限ったことではありません。
Amazon、Twitterなども常にスクレイピングへの対策を実施しています。
つい最近もAmazonがクッキーの有無をチェックに加えてきました。
そのことへの対応策は、次の記事でまとめています。

つまり、いたちごっこと言うことですね。
Instagramをスクレイピングするサンプルコード
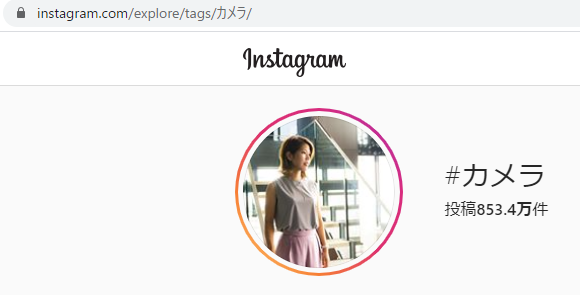
Instagramにおいて「#カメラ」で検索した結果を取得するコードです。
2020年09月19日時点では、htmlソース上のjsonをスクレイピングできています。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.parse
import re
import json
KEYWORD = "カメラ"
CHROMEDRIVER = "chromedriver.exeのパス"
def get_search_value(ptn, str):
result = re.search(ptn, str)
if result:
return result.group(1)
else:
return None
if __name__ == '__main__':
# url
url = "https://www.instagram.com/explore/tags/" + urllib.parse.quote(KEYWORD) + "/"
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
driver.get(url)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
html = driver.page_source
json_str = get_search_value("window._sharedData = (.*);<\/script>", html)
dict = json.loads(json_str)
取得したjsonを辞書型のデータに変換しています。
以下は、変換後のデータの一部です。
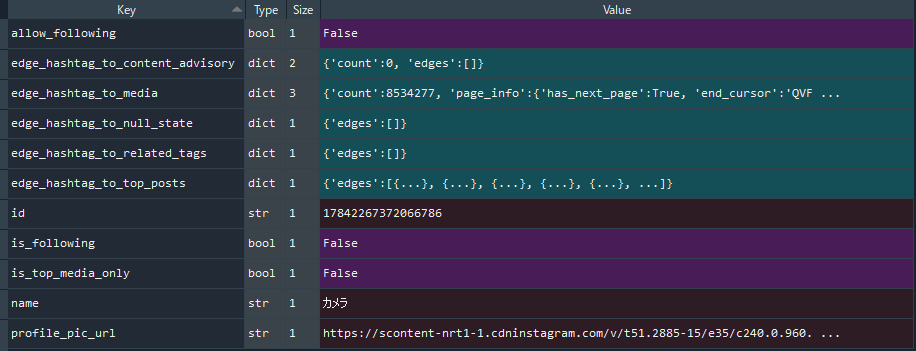
「8534277」が、総件数なのでしょう。
このサンプルコードにより、ハッシュタグ毎の総件数は取得できるということです。
今回は、ここまでとします。
今後、投稿の内容を取得したい場合も出てきます。
もちろん、最初の10件だけではなく、それ以降の投稿も対象となるでしょう。
スクロールによって、コンテンツが表示されていく形式のやつです。
その場合のスクレイピングは、TwitterやYahooファイナンスで実証済みです。
その際のコードで対応できるのかどうか?
ある意味、楽しみです。
追記 2020年09月25日
本記事を書いた翌日に試しました。
その結果は、次の記事でまとめています。


