
「日本語を音声認識した結果を評価したい」
「WERやCERをPythonで求めたい」
このような場合には、JiWERがオススメです。
この記事では、JiWERで音声認識率を測定する方法を解説しています。
本記事の内容
- JiWERとは?
- JiWERのシステム要件
- JiWERのインストール
- JiWERの動作確認
- JiWERで日本語を対象にする場合
それでは、上記に沿って解説していきます。
JiWERとは?
JiWERとは、音声認識の精度測定するPythonライブラリです。
音声認識の精度を測定するとは、テキストの比較に過ぎません。
テキスト同士の比較は、OCRの認識率を測定する際にも行います。
テキストに落とし込めれば、音声認識もOCR(光学文字認識)も同じということです。
テキストを比較して評価する際には、以下の指標が用いられます。
- WER(Word Error Rate)
- CER(Character Error Rate)
それぞれを以下で説明します。
WER
WERとは、単語誤り率を示します。
WERを求める計算式は、以下。
(挿入単語数 + 置換単語数 + 削除単語数) / 正解単語数
CER
CERとは、文字誤り率を示します。
CERを求める計算式は、以下。
(挿入語数 + 置換語数 + 削除語数) / 正解語数
まとめ
WERとCERの違いは、単語か文字かの違いです。
より正確性を求めるなら、CERでの評価となるのでしょう。
JiWERを使うと、WERとCERを求めることが可能になります。
以上、JiWERについて説明しました。
次は、JiWERのシステム要件を説明します。
JiWERのシステム要件
現時点(2022年10月)でのJiWERの最新バージョンは、2.5.1となります。
この最新バージョンは、2022年9月7日にリリースされています。
サポートOSに関しては、以下を含むクロスプラットフォーム対応です。
- Windows
- macOS
- Linux
JiWERは、Pure PythonであるためにOSは問いません。
サポート対象となるPythonのバージョンは、以下。
- Python 3.7
- Python 3.8
- Python 3.9
- Python 3.10
このサポート状況は、完璧です。
以下のPython公式開発サイクルに従っています。
| バージョン | リリース日 | サポート期限 |
| 3.6 | 2016年12月23日 | 2021年12月23日 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
Python 3.6は、2021年末でサポート期限が切れています。
ここまでを見ると、JiWERのシステム要件はあってないようなモノです。
以上、JiWERのシステム要件を説明しました。
次は、JiWERのインストールを説明します。
JiWERのインストール
検証は、次のバージョンのPythonで行います。
> python -V Python 3.10.4
まずは、現状のインストール済みパッケージを確認しておきます。
> pip list Package Version ---------- ------- pip 22.2.2 setuptools 65.4.1 wheel 0.37.1
次にするべきことは、pipとsetuptoolsの更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip setuptools
では、JiWERのインストールです。
JiWERのインストールは、以下のコマンドとなります。
pip install jiwer
JiWERのインストールは、すぐに終わります。
終了したら、どんなパッケージがインストールされたのかを確認します。
> pip list Package Version ----------- ------- jarowinkler 1.2.3 jiwer 2.5.1 Levenshtein 0.20.2 pip 22.2.2 rapidfuzz 2.10.3 setuptools 65.4.1 wheel 0.37.1
JiWERは、複数のパッケージに依存しています。
Levenshtein「レーベンシュタイン距離」という名前を確認できますね。
以上、JiWERのインストールを説明しました。
次は、JiWERの動作確認を説明します。
JiWERの動作確認
JiWERの動作確認を行います。
WERを求めるには、次の関数を利用します。
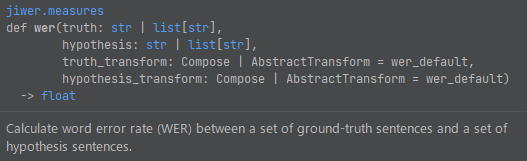
引数には、文字列かリストのどちらを設定可能です。
from jiwer import wer # 文字列 ground_truth = "hello world" hypothesis = "hello duck" # リスト型 # ground_truth = ["hello", "world"] # hypothesis = ["hello", "duck"] error = wer(ground_truth, hypothesis) print(error)
上記を実行した結果は、以下。
0.5
CERを求めるには、次の関数を利用します。

引数には、文字列かリストのどちらを設定可能です。
しかし、文字列を設定するようにしましょう。
from jiwer import cer # 文字列 ground_truth = "1234567890" hypothesis = "ab3456789" error = cer(ground_truth, hypothesis) print(error)
上記を実行した結果は、以下。
0.3
3文字(2個は異なり、1個は不足)の差異があり、0.3ということでしょう。
以上、JiWERの動作確認を説明しました。
最後に、JiWERで日本語を対象にする場合を説明します。
JiWERで日本語を対象にする場合
CERに関しては、上記のコードのままで対応できます。
しかし、WERはそのままではまともに動きません、
例えば、次の2ファイルを比較するとします。
可能なら句読点は除外しましょう。
今回は、区切りがわかるように「。」だけ残しています。
1.txt
私は日本人です。 そして日本語を話します。
2.txt
私は日本です。 そして英語を話します。
これらを読み込んで、比較するコードは以下。
from jiwer import wer
ground_truth_file = '1.txt'
hypothesis_file = '2.txt'
with open(ground_truth_file, mode='r', encoding='utf-8') as f:
ground_truth = f.read()
with open(hypothesis_file, mode='r', encoding='utf-8') as f:
hypothesis = f.read()
error = wer(ground_truth, hypothesis)
print(error)
実行した結果は、以下。
1.0
これは、100%の単語誤り率ということです。
ファイルの文章全体を一つの単語として、比較しています。
それであれば、100%で誤りとなります。
そうです、例のアレです。
「分かち書き」していないから、このような状況になっています。
ということで、Mecabを使って分かち書きをしましょう。
次の記事では、PythonからMecabが利用できる方法を解説しています。
Mecabのインストールについても説明しています。

PythonからMecabを使えるようになったら、次のコードを実行してみましょう。
import MeCab
from jiwer import wer
ground_truth_file = '1.txt'
hypothesis_file = '2.txt'
mecab = MeCab.Tagger('-Owakati')
with open(ground_truth_file, mode='r', encoding='utf-8') as f:
ground_truth = mecab.parse(f.read())
with open(hypothesis_file, mode='r', encoding='utf-8') as f:
hypothesis = mecab.parse(f.read())
error = wer(ground_truth, hypothesis)
print(ground_truth)
print(hypothesis)
print(error)
上記を実行すると、次のように表示されます。
私 は 日本人 です 。 そして 日本語 を 話し ます 。 私 は 日本 です 。 そして 英語 を 話し ます 。 0.18181818181818182
それぞれのファイルの内容を分かち書きで単語に分解しています。
それらを比較した結果は、約18%の単語誤り率になります。
11個の単語中、2つの単語で差異があります。
2を11で割れば、0.18ということですね。
以上、JiWERで日本語を対象にする場合について説明しました。

