
Amazonがスクレイピング対策をしてきました。
しかし、もう攻略しました。
攻略と言っても、そんなに大袈裟なモノではありません。
本記事の内容
- Amazonがスクレイピング対策をしてきた事実
- Amazonのスクレイピング対策への攻略法
- 攻略法の実例【ASINを取得する】
- 攻略法の実例【レビューを取得する】
- Amazonのスクレイピング対策を攻略するのまとめ
まずは、Amazonがスクレイピング対策をしてきた事実から説明します。
Amazonがスクレイピング対策をしてきた事実
次の画面をご覧ください。
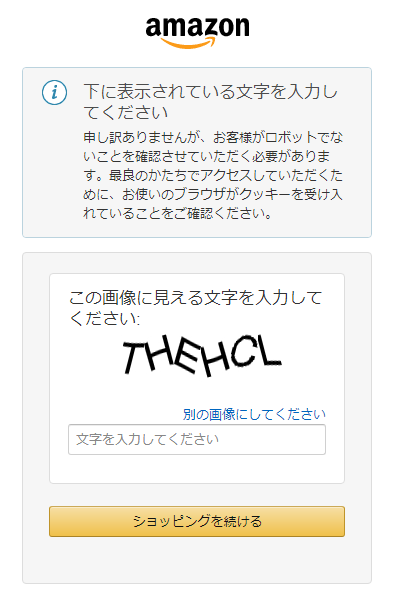
ロボット対策のヤツです。
Google検索では、よく見ます。
でも、Amazonでは初めて見ました。
ただ、実際にブラウザで見たわけではありません。
PythonでAmazonのページをスクレイピングした際に出てきたページです。
もっと正確に言えば、プログラムが取得したhtmlソースとなります。
そのhtmlを再現して、ブラウザで確認したモノが上の画面です。
このページのタイトルは「Amazon CAPTCHA」となっています。
あと、htmlソース上に以下のコメントがあります。
<!--
To discuss automated access to Amazon data please contact api-services-support@amazon.com.
For information about migrating to our APIs refer to our Marketplace APIs at https://developer.amazonservices.jp/ref=rm_c_sv, or our Product Advertising API at https://affiliate.amazon.co.jp/gp/advertising/api/detail/main.html/ref=rm_c_ac for advertising use cases.
-->
ざっくり言うと、「APIを利用しろ」と言うことですね。
でも、プログラムによるアクセスを強く否定するメッセージではありません。
「please」とあるようにお願いしています。
利用規約に同意(ログイン)していない以上、そうそう強くは言えません。
いくら天下のAmazonと言えども。
このあたりの解釈については、次の記事にまとめています。

なお、Amazonがスクレイピング対策をしてきた正確な日時はわかりません。
少なくとも以下の記事を作成する際には、まだ対策はされていませんでした。

つまり、2020年7月6日時点では、まだ対策されていませんでした。
ここで言うスクレイピング対策とは、次のコードが動かなくなったことの原因を言います。
requests.get(url)
PythonのRequestsライブラリを利用しています。
2020年7月6日までは、これでAmazonのページを取得できていました。
しかし、現在(2020年7月14日)は上記コードでは取得できません。
取得できたのは、「Amazon CAPTCHA」のページです。
よって、7月6日から7月14日の間でスクレイピング対策をしてきたと言えます。
以上が、Amazonがスクレイピング対策をしてきた事実です。
では、次以降でこのスクレイピング対策を攻略しましょう。
Amazonのスクレイピング対策への攻略法
これは、簡単です。
Seleniumを利用するだけです。
Seleniumに関しては、次の記事で解説しています。

Seleniumを使えば、どんなページでもスクレイピング可能だと思います。
これを禁止にすれば、ブラウザでアクセスできないことになりますからね。
Seleniumを使って、Amazonのスクレイピング対策を攻略する方向性は決まりました。
では、具体的に攻略していきましょう。
攻略法の実例【ASINを取得する】
商品ページからASINを取得します。
次の記事では、取得したASINをもとに対象サイトをスクレイピングしています。
もちろん、上の記事内のコードも動きません。
理由は、以下でページを取得しているからです。
requests.get(url)
それを動くようにします。
次の関数を追加します。
# ASIN取得2
def get_asin_from_amazon_2(url):
asin = ""
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome("chromedriver.exeのパス", options=options)
driver.get(url)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
elem_base = driver.find_element_by_id('ASIN')
if elem_base:
asin = elem_base.get_attribute("value")
else:
print("NG")
# ブラウザ停止
driver.quit()
return asin
そして、新たに追加した関数を利用します。
修正前のコード
asin = get_asin_from_amazon(url)
修正後のコード
asin = get_asin_from_amazon_2(url)
この対応により、上記2つの記事内のコードが動くようになりました。
ただ、速度は落ちますね。
Amazon側でいろいろとチェックしているのでしょう。
その分だけ、ページ取得の速度が落ちています。
しかし、これは仕方がないでしょう。
攻略法の実例【レビューを取得する】
こちらも同じく関数を追加します。
Selenium関連のモジュールの読み込みを記述します。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# Amazonページ取得
def get_page_from_amazon(url):
text = ""
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome("chromedriver.exeのパス", options=options)
driver.get(url)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
text = driver.page_source
# ブラウザ停止
driver.quit()
return text
同じように、新たに追加した関数を利用します。
修正前のコード
res = requests.get(url)
amazon_soup = bs4.BeautifulSoup(res.text, features='lxml')
修正後のコード
text = get_page_from_amazon(url)
amazon_soup = bs4.BeautifulSoup(text, features='lxml')
これで修正前と同じように、レビューを取得できるようになりました。
こっちの修正において、Seleniumはページのソースを取得するために用いています。
スクレイピングは、今まで通り「Beautiful Soup」で行います。
ケースバイケースで使い分けです。
Amazonのスクレイピング対策を攻略するのまとめ
おそらく、これからもAmazonはスクレイピングの対策をしてくるでしょう。
ただ、個人的にはムダな抵抗だと思います。
ブラウザでページを見れる以上は、プログラムでも同じように見れるはずです。
そして、それはSeleniumを使えば簡単に実現できます。
私自身は、スクレイピング自体は何も悪いと思いません。
悪いのは、サーバーへの大量アクセスです。
ここでは、公開されている情報についてのスクレイピングに言及してます。
非公開情報へのスクレイピングは、ダメです。
そもそも、非公開情報へアクセスするにはログインしないといけません。
ログインする(アカウントを作成する)時点で、利用規約に同意しています。
おそらく利用規約には、スクレイピングは禁止事項にあるでしょう。
だから、非公開情報のスクレイピングはNGと言えます。
話を大量アクセスに戻しましょう。
大量アクセスの定義ですよね。
人間がアクセスできる間隔なら、それは問題なしと認識しています。
速い人なら、1秒に1ページはアクセスできるでしょう。
よって、1秒の間隔を設ければ、セーフだと思います。
1秒間隔に耐えられないサーバーなんて、今時ありません。
昔ならいざ知らず、この令和の時代にそんなサーバーはヤバイです。
以上をまとめます。
スクレイピングは、何も悪くありません。
短時間での大量アクセスが、悪いのです。

