今回のスクレイピングの対象は、DMMから名前を変えたFANZA動画です。
でも、やはりDMMの印象が強く残っています。
そのため、FANZA動画と言ってもピンとは来ません。
さて、今回でFANZA動画のスクレイピングを取り扱うのは2回目です。
前回の記事は以下をご覧ください。

本記事の内容
- 動画(商品)ページにおけるレビューをスクレイピングする理由
- 動画(商品)ページにおけるレビューのスクレイピング仕様
- 【サンプルコード】動画(商品)ページにおけるレビューのスクレイピング
それでは、上記に沿って解説していきます。
動画(商品)ページにおけるレビューをスクレイピングする理由
今回は、動画(商品)ページでの商品レビューをスクレイピングしていきます。
ちなみに、前回はレビューワー毎のスクレイピングでした。
前回にレビューワーのページを対象にした理由は、単純に個人的な過去の恨みです。
詳細は、前回記事をご覧ください。
そして、なぜ今回、動画(商品)ページにおけるレビューをスクレイピングするのか?
「FANZA動画のスクレイピングは意外と需要がある」
このことが、当サイトのアクセス分析でわかりました。
それなら、もっと需要のある動画(商品)ページのレビューを対象にしようと。
これが大きな理由です。
動画(商品)ページにおけるレビューのスクレイピング仕様
基本的には、前回記事からは大きく変わりません。
同じように、動的コンテンツ対策としてPythonでSeleniumを使います。

そして、やはり今回も改ページ処理がポイントになります。

「次へ」ボタン(リンク)をSeleniumでクリックして、遷移します。
遷移と言っても、実際にページ遷移は発生しません。
JavaScriptにより、コンテンツを取得して、表示し直しているだけです。
簡潔に言えば、「Ajaxで動的コンテンツ対応している」ですね。
前回も、ここまでは対応しています。
ただ、前回までの対応だと不備があることが判明しました。
運が良ければ、別にそのままでも問題はありません。
でも、サイトが遅い場合などには、問題として発覚してきます。
それは、タイミングの問題です。
「次へ」をクリックして、コンテンツを取得しようとする際のタイミングです。
「次へ」をクリックして、すぐにコンテンツが表示されれば何も問題ありません。
しかし、コンテンツが表示される前にスクレイピングすればどうなるでしょうか?
それは、全く同じコンテンツが取得できるだけです。
そこで、今回はこのタイミングの問題の対応を行ないます。
コンテンツの更新を待ってスクレイピングする
以下は、レビュー部分のhtmlタグです。
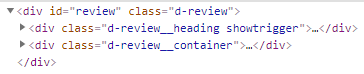
「次へ」ボタンをクリックすると、id=reviewの内部を丸ごと置き換えています。
その中に改ページ部分やレビューが記述されています。
この状況において、キーとなるのは「前へ」ボタンです。

「前へ」ボタンがクリックできるようになっていれば、レビュー(コンテンツ)の更新が完了しているはずです。
このような処理を今回のコードでは追加しています。
【サンプルコード】動画(商品)ページにおけるレビューのスクレイピング
サンプルコードは以下。
2020年09月25日時点は、動いています。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import bs4
import re
import time
CONTENT_ID = "jufd00558"
FANZA_BASE = "https://www.dmm.co.jp/digital/videoa/-/detail/=/"
CHROMEDRIVER = "chromedriver.exeのパス"
def get_driver(init_flg):
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
# ページ取得
def get_page_from_url(driver, url):
try:
# ターゲット
driver.get(url)
driver.implicitly_wait(10) # 見つからないときは、10秒まで待つ
text = driver.page_source
return text
except:
return None
def get_search_value(ptn, str):
result = re.search(ptn, str)
if result:
return result.group(1)
else:
return None
def extract_date(s):
date_pattern = re.compile('(\d{4})/(\d{1,2})/(\d{1,2})')
result = date_pattern.search(s)
if result:
y, m, d = result.groups()
return str(y) + str(m.zfill(2)) + str(d.zfill(2))
else:
return None
# info取得
def get_review_from_text(text):
review = []
if text==None:
text = driver.page_source
soup = bs4.BeautifulSoup(text, features='lxml')
try:
base_elem = soup.find(class_="d-review__list")
# レビュー
elems = base_elem.find_all(class_="d-review__unit")
for elem in elems:
r_dict = {}
r_title = None
r_comment = None
r_postdate = None
r_service = None
r_used = False
r_reviewer_id = None
r_rating = None
# レビュータイトル
target_elem = elem.find(class_="d-review__unit__title")
if target_elem:
r_title = target_elem.text
# レビューコメント
target_elem = elem.find(class_="d-review__unit__comment fn-d-review__unit__caution")
if target_elem:
# ネタバレ警告あり
target_elems = elem.find_all(class_="d-review__unit__comment")
if target_elems[1]:
r_comment = target_elems[1].text
else:
# ネタバレ警告なし
target_elem = elem.find(class_="d-review__unit__comment")
r_comment = target_elem.text
# レビュー投稿日
target_elem = elem.find(class_="d-review__unit__postdate")
if target_elem:
r_postdate = target_elem.text
r_postdate = extract_date(r_postdate)
# カテゴリー
target_elem = elem.find(class_="d-review__unit__service")
if target_elem:
r_service = target_elem.text
r_service = r_service.replace("-", "")
# 購入実績
target_elem = elem.find(class_="d-review__unit__used")
if target_elem:
r_used = True
# レビューワー
target_elem = elem.find(class_="d-review__unit__reviewer")
if target_elem:
a_tag_elem = target_elem.find("a")
href = a_tag_elem.get("href")
r_reviewer_id = get_search_value("id=(.*)\/", href)
# 評価
target_elems = elem.find_all("span")
if target_elems[0]:
rating_dic = target_elems[0].get("class")
if rating_dic:
r_rating = rating_dic[0]
r_rating = r_rating.replace("d-rating-", "")
r_dict["title"] = r_title
r_dict["comment"] = r_comment
r_dict["postdate"] = r_postdate
r_dict["service"] = r_service
r_dict["used"] = r_used
r_dict["reviewer_id"] = r_reviewer_id
r_dict["rating"] = r_rating
review.append(r_dict)
return review
except:
print("err")
return None
def next_btn_click(driver):
# クラスが読み込まれるまで待機(最大10秒)
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CLASS_NAME, "d-boxpagenation")))
try:
elem_pagenation = driver.find_element_by_class_name("d-boxpagenation")
elem_next = elem_pagenation.find_element_by_link_text("次へ")
if elem_next:
elem_next.click()
# 読み込み完了を待つ
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.LINK_TEXT, "前へ")))
return True
else:
return False
except:
return False
if __name__ == "__main__":
# Driver
driver = get_driver(True)
# cid
cid = CONTENT_ID
# URL
content_url = FANZA_BASE + "cid=" + cid + "/"
# htmlソース取得
content_text = get_page_from_url(driver, content_url)
# レビュー取得
review_list = []
review = get_review_from_text(content_text)
review_list.extend(review)
# 次ページへ
next_flg = next_btn_click(driver)
while next_flg:
time.sleep(1)
# レビュー取得
review = get_review_from_text(None)
review_list.extend(review)
next_flg = next_btn_click(driver)
# ブラウザ停止
driver.quit()
必要なモジュール・ライブラリがあれば、コピペで動きます。
対象ページのレビューをすべてスクレイピングします。
基本的に、Pythonコードの説明はしません。
なぜなら、この程度のコードを理解できないなら、スクレイピングはやるべきではありません。
スクレイピングは、使い方を間違えば、相手方サーバーへの攻撃になりかねません。
よって、その内容を理解せずに利用することは危険です。
ただ、Seleniumに関する部分は説明しておきます。
特に「コンテンツの更新を待ってスクレイピングする」の部分ですね。
def next_btn_click(driver):
# クラスが読み込まれるまで待機(最大10秒)
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CLASS_NAME, "d-boxpagenation")))
try:
elem_pagenation = driver.find_element_by_class_name("d-boxpagenation")
elem_next = elem_pagenation.find_element_by_link_text("次へ")
if elem_next:
elem_next.click()
# 読み込み完了を待つ
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.LINK_TEXT, "前へ")))
return True
else:
return False
except:
return False
上記の関数内でコンテンツの更新を待っています。
elem_next.click()
# 読み込み完了を待つ
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.LINK_TEXT, "前へ")))
「次へ」ボタンがクリックされた後、「前へ」ボタン(リンク)がクリック可能になるまで待ちます。
10秒以内に「前へ」ボタンがクリック可能にならないと、例外エラーとなります。
なお、他の動画(商品)ページを対象に変更する場合は、以下の値を変更します。
CONTENT_ID = "jufd00558"
この値は、cidとしてサイト内では扱われています。