
自然言語処理の分野で大きな注目を集めているのがMetaが開発した大規模言語モデル「LLaMA」です。
このモデルをC++で実装し、Pythonから使えるようにしたのが「llama-cpp-python」になります。
llama-cpp-pythonを使えば、開発者は最先端の言語モデルを自分のプロジェクトに簡単に組み込むことができます。
そのため、多くの開発者から注目を集めています。
今回は、そんなllama-cpp-pythonのインストール方法と動作確認の手順を詳しく解説していきます。
本記事の内容
- llama-cpp-pythonとは?
- llama-cpp-pythonのシステム要件
- llama-cpp-pythonのインストール
- llama-cpp-pythonの動作確認
それでは、上記に沿って解説していきます。
llama-cpp-pythonとは?
LLaMAモデルは、MetaのAI研究所が開発したLLMモデルです。
LLaMAは大量のテキストデータを学習し、自然な文章生成や質問回答、要約などを実行します。
llama-cpp-pythonは、このLLaMAモデルをより多くの開発者が手軽に利用できるよう開発されています。
llama-cpp-pythonには、以下の特徴があります。
- C++で実装されているため、高速に動作します。
- Pythonバインディングが提供されているため、Pythonから簡単に利用できます。
- メモリ使用量を最適化する機能が組み込まれており、消費リソースを抑えられます。
- オープンソースで提供されているため、誰でも自由に利用・改変できます。
llama-cpp-pythonを使うことで、ChatGPTのようなAIアプリケーションを作ることができます。
また、モデルの動作をカスタマイズしたり、独自のデータで追加学習したりすることも可能です。
llama-cpp-pythonのシステム要件
llama-cpp-pythonは、様々なOSに対応しています。
ここでは、Windowsに関してのシステム要件を説明します。
その場合のシステム要件は、以下となります。
- Python 3.8以降
- コンパイラ
- CMake
それぞれを以下で説明します。
Python 3.8以降
Python公式開発サイクルに準じています。
| バージョン | リリース日 | サポート期限 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
| 3.11 | 2022年10月24日 | 2027年10月 |
| 3.12 | 2023年10月2日 | 2028年10月 |
バージョンを上げる必要がある場合は、次の記事が参考になります。

コンパイラ
C++コンパイラが必要となります。
公式では、どちらかのコンパイラが必要と記載されています。
Visual Studio or MinGW
ここでは「Visual Studio」を用います。
まず、インストール済みかどうかを確認しましょう。
C:\>cl Microsoft(R) C/C++ Optimizing Compiler Version 19.29.30151 for x86 Copyright (C) Microsoft Corporation. All rights reserved. 使い方: cl [ オプション... ] ファイル名... [ /link リンク オプション... ]
コマンドプロントで「cl」の実行結果が、上記のようになればOK。
そうでない場合は、次の記事を参考にしてインストールしてください。

CMake
CMakeは、C++プロジェクトを管理するためのビルドツールです。
インストール済みかどうかは、次のコマンドで確認できます。
C:\>cmake --version cmake version 3.25.0-rc1 CMake suite maintained and supported by Kitware (kitware.com/cmake).
未インストールの場合は、次の記事を参考にしてください。

llama-cpp-pythonのインストール
システム要件が整えば、あとはコマンド一発です。
pip install llama-cpp-python
コンパイルをしているため、インストールはそこそこ時間がかかります。
llama-cpp-pythonの動作確認
llama-cpp-pythonの動作確認を行います。
動作確認するためには、LLMのモデルが必要です。
モデルは、以下のページからダウンロードできます。

とりあえず、今回は最も軽量なモデルをダウンロードします。
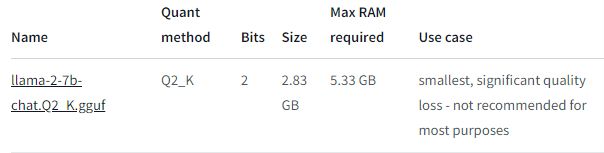
このモデルを動かすコードは、以下となります。
from llama_cpp import Llama
import pprint
llm = Llama(
model_path="llama-2-7b-chat.Q2_K.gguf",
verbose=False
# n_gpu_layers=-1, # Uncomment to use GPU acceleration
# seed=1337, # Uncomment to set a specific seed
# n_ctx=2048, # Uncomment to increase the context window
)
output = llm(
"Q: 日本の首都は? A: ", # Prompt
max_tokens=32, # Generate up to 32 tokens, set to None to generate up to the end of the context window
stop=["Q:", "\n"], # Stop generating just before the model would generate a new question
echo=True # Echo the prompt back in the output
) # Generate a completion, can also call create_completion
pprint.pprint(output)
上記コードを実行すると、次のような結果が表示されます。
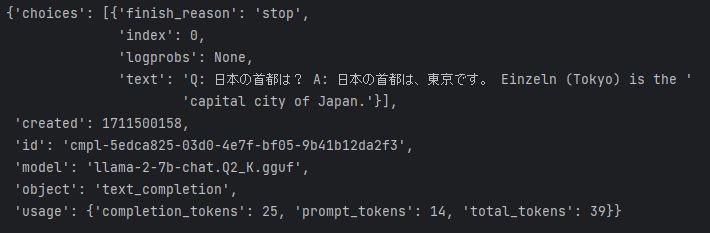
LLMの返答である「A」は、実行毎に内容が異なります。
日本語であるとも限りません。
この辺が、軽量モデルという感じがします。
それでも、一応は質問に回答できています。

