
競馬サイトのnetkeibaをスクレイピングします。
それもnetkeibaにばれることなくやります。
今回は、レース結果ページのスクレイピングです。
レース結果ページをスクレイピングすることにより、競馬レース結果を抽出できます。
本記事の内容
- ここまでの流れ【メルカリのスクレイピング】
- レース結果ページのスクレイピング仕様
- レース結果ページから競馬レース結果を抽出する
それでは、上記に沿って解説していきます。
ここまでの流れ【メルカリのスクレイピング】
netkeibaのスクレイピングに関して、段階を踏んで解説してきています。
今回は、そのシリーズの第4弾となります。
一旦、今回の第4弾で同シリーズは完了とします。
今後、騎手一覧、競走馬一覧が必要になればその都度スクレイピングをするかもしれません。
では、下記で同シリーズの過去記事を案内します。
第1弾

第2弾

第3弾

第1弾の記事は、絶対に読んでください。
スクレイピングをする上での心得を記しています。
その心得がないと、犯罪をしてしまうかもしれません。
加えて、スクレイピングを行うための環境面の準備についても説明しています。
Seleniumの導入に関する情報などを記しています。
第2弾の記事は、競馬開催日リストの作成方法の解説です。
netkeibaスクレイピングのロードマップを解説しています。
スクレイピングを行う際の考え方がその解説に詰まっています。
第3弾の記事は、開催一覧ページからrace_idを抽出しています。
race_idからレース結果詳細ページの特定(URL)が可能です。
そして、今回は第4弾となります。
この第4弾では、最終目的となるレース結果のスクレイピングを行います。
このレース結果をスクレイピングするために、今まで準備してきました。
今回のスクレイピングでこれまでの努力が一気に報われます。
では、まずはそのための仕様を確認しましょう。
レース結果ページのスクレイピング仕様
レース結果ページのスクレイピング仕様を説明していきます。
次の2つに分けて説明します。
- レース結果ページのURL作成
- レース結果ページのhtmlタグ分析
それぞれを下記で説明します。
レース結果ページのURL作成
第3弾までを終えて、手元にはrace_idリストがあります。
今回は、「kaisai_date=20180106」で絞ったレース一覧をピックアップします。
具体的には、以下のrace_idです。
['201806010101', '201806010102', '201806010103', '201806010104', '201806010105', '201806010106', '201806010107', '201806010108', '201806010109', '201806010110', '201806010111', '201806010112', '201808010101', '201808010102', '201808010103', '201808010104', '201808010105', '201808010106', '201808010107', '201808010108', '201808010109', '201808010110', '201808010111', '201808010112']
そして、netkeibaにおけるレース結果ページのURLは以下の形式でした。https://race.netkeiba.com/race/result.html?race_id=●
●にrace_idを設定すると、レース結果ページが表示されます。
例えば、「201806010101」を設定してみてください。
https://race.netkeiba.com/race/result.html?race_id=201806010101
上記URLにアクセスすると、以下の画面が表示されます。
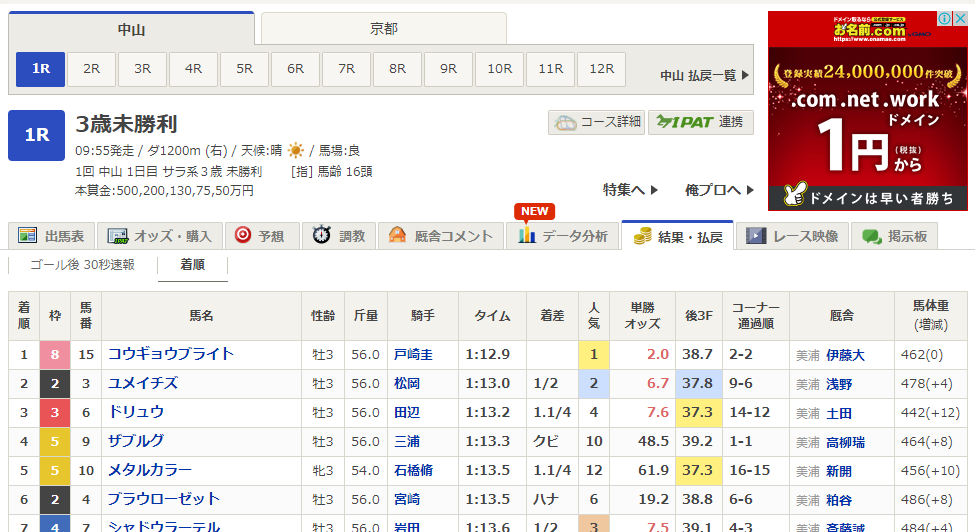
以上より、race_idリストからレース結果ページのURL作成が可能です。
そのため、ここまで段階を踏んできました。
レース一覧ページのhtmlタグ分析
まず、スクレイピングするデータを確認しておきましょう。
- レース情報
- 全着順
- 払い戻し
- ラップタイム
「コーナー通過順位」以外の上記データをスクレイピングします。
個別に解説していきます。
レース情報
レース情報とは、以下のことです。

htmlソースでは、次の部分になります。
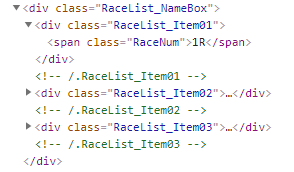
「class=”RaceList_NameBox”」のdivの下がスクレイピング対象です。
「class=”RaceNum”」にレース番号があります。
それ以外は、「class=”RaceList_Item02″」の下の要素を見ていけばよさそうです。
ただし、以下のようにclassで特定が困難なデータも存在しています。
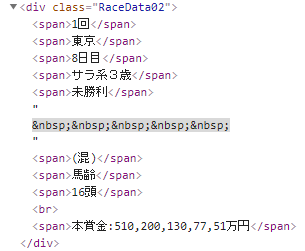
このような場合は、spanの順序でデータを特定するしかありません。
例えば、「(混) 馬齢 16頭」のデータ部分を取得するとします。
「class=”RaceData02″」のdivの下にあるspan一群を取得します。
その一群の6番目と7番目と8番目が取得するデータになります。
実際は、それぞれ分けて取得します。
スクレイピングするときは、できる限りでそのまま取得する方向ということです。
加工は取得した後で、「お好きにどうぞ」という形の方が使いやすいでしょう。
全着順
以下は、全着順の一部です。

htmlソースで確認しましょう。
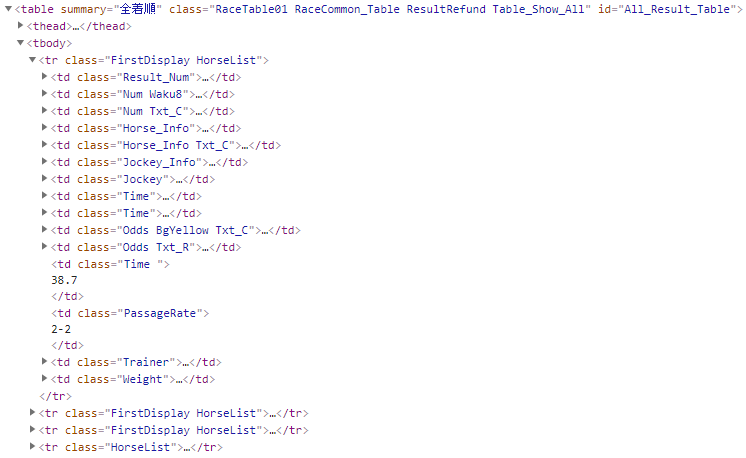
ここは簡単ですね。
「id=”All_Result_Table”」のtableの下にあるtrを対象にします。
「class=”HorseList”」で特定までしてもいいかもしれません。
あとは、そのtrの下の要素をclass名指定でスクレイピングすればOKです。
でも、同じclass名も存在しているのでtdの順番で各項目を認識します。
払い戻し
払い戻しは、次の部分です。
とりあえず、htmlソースを確認します。

二つのtableで表示しているのですね。
ここは、「class=”FullWrap”」のdiv下にあるtrを対象にした方がよさそうです。
若干、クセのあるhtmlコーディングですね。
divで改行したり、brで改行したり、spanで改行したり。。。
もっと担当直入に言いましょう。
かなり酷いhtmlコーディングです。
おそらくエンジニアが強引にコーディングしたのでしょう。
私も過去にそのようなコーディングをしたことがあります。
だからこそ、わかるのです。
ラップタイム
htmlソースでは、以下となります。

「class=”RapPace_Title”」のdiv下のspanからペース(H)は取得できます。
ラップタイムは、「class=”Race_HaronTime”」のtable下で絞ればよさそうです。
ただ、レースの距離によって、列数が可変であることには注意が必要です。
レース結果ページから競馬レース結果を抽出する
レース結果ページから各データを抽出するコードは、以下。
現時点(2021年2月24日)ではモリモリと動いています。
サンプルコード
結構長いコードになっています。
情報量の多いページなので仕方がありません。
import bs4
import traceback
import re
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# ドライバーのフルパス
CHROMEDRIVER = "chromedriver.exeのパス"
# 改ページ(最大)
PAGE_MAX = 2
# 遷移間隔(秒)
INTERVAL_TIME = 3
# ドライバー準備
def get_driver():
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome(CHROMEDRIVER, options=options)
return driver
# 対象ページのソース取得
def get_source_from_page(driver, page):
try:
# ターゲット
driver.get(page)
# class="RaceList_NameBox"の要素が見つかるまで10秒は待つ
target_elem = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.CLASS_NAME, "RaceList_NameBox"))
)
if target_elem:
page_source = driver.page_source
return page_source
else:
return None
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# ソースからスクレイピングする
def get_data_from_source(src):
try:
# スクレイピングする
soup = bs4.BeautifulSoup(src, features='lxml')
info = {}
info["race_info"] = None
info["race_order"] = None
info["payout"] = None
info["rap_pace"] = None
# レース情報取得
info["race_info"] = get_race_info(soup)
# 全着順取得
info["race_order"] = get_order(soup)
# 払い戻し取得
info["payout"] = get_payout(soup)
# ラップタイム取得
info["rap_pace"] = get_rap_pace(soup)
return info
except Exception as e:
print("Exception\n" + traceback.format_exc())
return None
# レース情報の抽出
def get_race_info(soup):
result = {}
result["no"] = None
result["name"] = None
result["time"] = None
result["kind"] = None
result["weather"] = None
result["state"] = None
result["course"] = None
result["etc_1"] = None
result["etc_2"] = None
result["etc_3"] = None
result["etc_4"] = None
result["etc_5"] = None
result["etc_6"] = None
result["etc_7"] = None
result["etc_8"] = None
elem_base = soup.find(class_="RaceList_NameBox")
if elem_base:
tmp_elem = elem_base.find(class_="RaceNum")
if tmp_elem:
tmp_data = tmp_elem.text
result["no"] = my_trim(tmp_data)
tmp_elem = elem_base.find(class_="RaceName")
if tmp_elem:
tmp_data = tmp_elem.text
result["name"] = my_trim(tmp_data)
tmp_elem = elem_base.find(class_="RaceData01")
if tmp_elem:
tmp_data = tmp_elem.text
tmp_data_list = tmp_data.split("/")
if len(tmp_data_list) >= 4:
result["time"] = my_trim(tmp_data_list[0])
result["kind"] = my_trim(tmp_data_list[1])
result["weather"] = my_trim(tmp_data_list[2])
result["state"] = my_trim(tmp_data_list[3])
tmp_elem = elem_base.find(class_="RaceData02")
if tmp_elem:
elems = tmp_elem.find_all("span")
if len(elems) >=9:
result["course"] = my_trim(elems[1].text)
result["etc_1"] = my_trim(elems[0].text)
result["etc_2"] = my_trim(elems[2].text)
result["etc_3"] = my_trim(elems[3].text)
result["etc_4"] = my_trim(elems[4].text)
result["etc_5"] = my_trim(elems[5].text)
result["etc_6"] = my_trim(elems[6].text)
result["etc_7"] = my_trim(elems[7].text)
result["etc_8"] = my_trim(elems[8].text)
return result
# 全着順の抽出
def get_order(soup):
result = []
elem_base = soup.find(id="All_Result_Table")
if elem_base:
tr_elems = elem_base.find_all("tr", class_="HorseList")
for tr_elem in tr_elems:
tmp = {}
td_elems = tr_elem.find_all("td")
if len(td_elems)==15:
tmp["rank"] = my_trim(td_elems[0].text)
tmp["waku"] = my_trim(td_elems[1].text)
tmp["umaban"] = my_trim(td_elems[2].text)
tmp["horse_name"] = my_trim(td_elems[3].text)
tmp["horse_age"] = my_trim(td_elems[4].text)
tmp["jockey_weight"] = my_trim(td_elems[5].text)
tmp["jockey_name"] = my_trim(td_elems[6].text)
tmp["time_1"] = my_trim(td_elems[7].text)
tmp["time_2"] = my_trim(td_elems[8].text)
tmp["odds_1"] = my_trim(td_elems[9].text)
tmp["odds_2"] = my_trim(td_elems[10].text)
tmp["time_3"] = my_trim(td_elems[11].text)
tmp["passage_rate"] = my_trim(td_elems[12].text)
tmp["trainer_name"] = my_trim(td_elems[13].text)
tmp["horse_weight"] = my_trim(td_elems[14].text)
# 馬ID
a_tag = td_elems[3].find("a")
if a_tag:
href = a_tag.attrs['href']
match = re.findall("\/horse\/(.*)$", href)
if len(match) > 0:
tmp_id = match[0]
tmp["horse_id"] = tmp_id
# 騎手ID
a_tag = td_elems[6].find("a")
if a_tag:
href = a_tag.attrs['href']
match = re.findall("\/jockey\/(.*)\/", href)
if len(match) > 0:
tmp_id = match[0]
tmp["jockey_id"] = tmp_id
# 厩舎ID
a_tag = td_elems[13].find("a")
if a_tag:
href = a_tag.attrs['href']
match = re.findall("\/trainer\/(.*)\/", href)
if len(match) > 0:
tmp_id = match[0]
tmp["trainer_id"] = tmp_id
result.append(tmp)
return result
# 払い戻し取得
def get_payout(soup):
result = {}
elem_base = soup.find(class_="FullWrap")
if elem_base:
tr_elems = elem_base.find_all("tr")
for tr_elem in tr_elems:
row_list = []
class_name = tr_elem.attrs["class"]
# class名を小文字にに変換
class_name = class_name[0].lower()
td_elems = tr_elem.find_all("td")
if len(td_elems) == 3:
# Ninkiのspan数が行数と判断可能
span_elems = td_elems[2].find_all("span")
count = len(span_elems)
# Payoutのテキストをbrで分割してできるデータ数とcountが同じ
# ただ、分割は「円」で行う
payout_text = td_elems[1].text
payout_text_list = payout_text.split("円")
if class_name=="tansho" or class_name=="fukusho":
# Resultのdiv数がcountの3倍
target_elems = td_elems[0].find_all("div")
else:
# Resultのul数がcountと同じ
target_elems = td_elems[0].find_all("ul")
for i in range(count):
tmp = {}
tmp["payout"] = my_trim(payout_text_list[i]) + "円"
tmp["ninki"] = my_trim(span_elems[i].text)
target_str = ""
if class_name == "tansho" or class_name == "fukusho":
target_str = my_trim(target_elems[i*3].text)
else:
li_elems = target_elems[i].find_all("li")
for li_elem in li_elems:
tmp_str = my_trim(li_elem.text)
if tmp_str:
target_str = target_str + "-" + tmp_str
# 先頭の文字を削除
target_str = target_str.lstrip("-")
tmp["result"] = target_str
row_list.append(tmp)
result[class_name] = row_list
return result
# ラップタイム取得
def get_rap_pace(soup):
result = []
row_list = []
elem_base = soup.find(class_="Race_HaronTime")
if elem_base:
tr_elems = elem_base.find_all("tr")
counter = 0
for tr_elem in tr_elems:
col_list = []
if counter == 0:
target_elems = tr_elem.find_all("th")
else:
target_elems = tr_elem.find_all("td")
for target_elem in target_elems:
tmp_str = my_trim(target_elem.text)
col_list.append(tmp_str)
row_list.append(col_list)
counter = counter + 1
for i in range(len(row_list[0])):
tmp = {}
tmp["header"] = row_list[0][i]
tmp["haron_time_1"] = row_list[1][i]
tmp["haron_time_2"] = row_list[2][i]
result.append(tmp)
return result
# 数値だけ抽出
def extract_num(val):
num = None
if val:
match = re.findall("\d+\.\d+", val)
if len(match) > 0:
num = match[0]
else:
num = re.sub("\\D", "", val)
if not num:
num = 0
return num
def my_trim(text):
text = text.replace("\n", "")
return text.strip()
# race_idリスト取得
def get_list_id():
return ['201806010101', '201806010102', '201806010103', '201806010104', '201806010105', '201806010106', '201806010107', '201806010108', '201806010109', '201806010110', '201806010111', '201806010112', '201808010101', '201808010102', '201808010103', '201808010104', '201808010105', '201808010106', '201808010107', '201808010108', '201808010109', '201808010110', '201808010111', '201808010112']
if __name__ == "__main__":
# kaisai_dateリスト取得
list_id = get_list_id()
# ブラウザのdriver取得
driver = get_driver()
# ページカウンター制御
page_counter = 0
for race_id in list_id:
page_counter = page_counter + 1
# 対象ページURL
page = "https://race.netkeiba.com/race/result.html?race_id=" + str(race_id)
# ページのソース取得
source = get_source_from_page(driver, page)
# ソースからデータ抽出
data = get_data_from_source(source)
# データ保存
print(data)
# 間隔を設ける(秒単位)
time.sleep(INTERVAL_TIME)
# 改ページ処理を抜ける
if page_counter == PAGE_MAX:
break
# 閉じる
driver.quit()
プログラムの内容は、上記の仕様とコード内のコメントを参考にしてください。
以下の各データは関数にして分けています。
- レース情報
- 全着順
- 払い戻し
- ラップタイム
わからないところがあれば、過去の同シリーズの記事をご覧ください。
詳しく説明している箇所がある可能性があります。
あと、以下の関数は第3弾の「kaisai_dateリストの取得」と同じ考え方です。
# race_idリスト取得 def get_list_id():
各自で適当に改変してください。
同じように、最終的にリスト型でrace_idの一覧を返答すればOKです。
実行結果
サンプルコードを実行した結果は、長すぎるので割愛します。
各自で実行してみてください。
PAGE_MAXは2に設定しているので、最大で2レース分だけの表示です。
それでも、割愛するほど長いデータとなります。
まとめ
今回で、netkeibaのスクレイピングがシリーズとしては完結です。
実行結果は載せていませんが、とにかく実行してみてください。
データがどんどんとスクレイピング(表示)される様子は、爽快感する覚えます。
まさにエンディングという感じです。
さて、今回でnetkeibaのスクレイピングは完了しました。
正直、netkeibaはスクレイピングの難易度としてはそこまで高くありません。
ただし、今回のレース結果ページはかなり手間がかかりました。
手間がかかるのと難しいのは、意味が異なります。
最後に、スクレイピングするのが難しいサイトを紹介しておきます。
Seleniumの機能をフルに使って、スクレイピングしています。
もう一段上のスクレイピングに興味がある場合は、下記をご覧ください。



他にもまだまだあります。
「スクレイピング」で本ブログをサイト内検索してみてください。

