今回は、競馬サイトのnetkeibaをスクレイピングします。
スクレイピング対象は、レース結果ページです。
折角なのでダービーのレース結果を対象にしましょう。
第87回東京優駿(G1)
https://db.netkeiba.com/race/202005021211/
本記事の内容
- netkeibaをスクレイピングする理由
- netkeibaのスクレイピング難易度
- netkeibaのスクレイピング仕様
- 【サンプルコード】netkeibaにおけるレース結果ページのスクレイピング
それでは、上記に沿って解説していきましょう。
netkeibaをスクレイピングする理由
競馬は、今はもうやっていません。
昔は、毎週のようにやっていましたけどね。
そして、今は以前ほど興味がありません。
そのため、スクレイピングする動機が個人的にはありませんでした。
それなのに、スクレイピングをやろうと思いました。
理由は以下の2点です。
- netkeibaのスクレイピングに需要がある
- 競馬データベース(JRA-VANデータラボ)が高過ぎる
これらを詳しく説明していきます。
netkeibaのスクレイピングに需要がある
JRA-VANデータラボ会員になれば、競馬データベースが使いたい放題です。
だから、競馬データのスクレイピングはそれほど需要がないと思い込んでいました。
しかし、そこそこの需要があるということがわかりました。
実際、スクレイピングしている記事が何件か見つかりました。
それならば、記事にしてみようと。
netkeibaのスクレイピングに対する対策具合を確認できるとも思いました。
追記 2024年5月6日
個人的に、再び競馬熱が盛り上がってきました。
そこで、まずは競走馬のデータベース作りからということで。

競馬データベース(JRA-VANデータラボ)が高過ぎる
JRA-VANデータラボ会員
https://jra-van.jp/dlb/feature.html
競馬をやっている時は、約2000円の月額料金はそれほど気になりませんでした。
しかし、競馬をやっていない状態で見るとバカ高いですね。。。
おそらく、競馬をやる上では、2000円なんて屁みたいな金額です。
だから、金銭的な感覚が麻痺していたのかもしれません。
今の私からすれば、「公開されているデータに2000円はないわ」となります。
それなら、スクレイピングで集めてやろうと。
実際、競馬はやらずにレース結果が必要な場合もあります。
競馬のレース結果は、統計や機械学習においては役に立つデータですからね。
このような用途のために、月額2000円(年間24000円!!)は高過ぎです。
netkeibaのスクレイピング難易度
netkeibaのスクレイピング難易度から言いましょう。
正直、簡単です。
レース結果に関しては、すべて静的コンテンツで表示されています。
TwitterやInstagramなどのように動的コンテンツ(Ajaxで表示)ではありません。
動的コンテンツへの対応方法は、これらの記事をご覧ください。


しかし、netkeibaはAmazonのようにはアクセスチェックが厳しいわけでもありません。
Amazonは静的コンテンツが大部分ですが、アクセス媒体(ブラウザ)のチェックがエグイです。
エグイ具合は、次の記事で解説しています。

よって、netkeibaはTwiiter、Instagram、Amazonなどと比べると楽勝です。
ただ、若干htmlコーディングが古いです。
このことが、少々やっかいに感じるかもしれません。
netkeibaのスクレイピング仕様
難易度のところで触れたように、静的コンテンツです。
そのため、Seleniumを利用する必要がありません。
Seleniumに関しては。次の記事で解説しています。

つまり、Pythonである必要もありません。
おそらく、PHPでも簡単にスクレイピングできるでしょう。
でも、Pythonでやります。
今後、netkeibaが動的コンテンツへ切り替えた場合もあるかもしれません。
その場合に、すぐに対応できるようにPythonでやっておきます。
では、仕様について説明していきます。
レース結果を取得します。
ここで言うレース結果とは、全頭分の順位です。
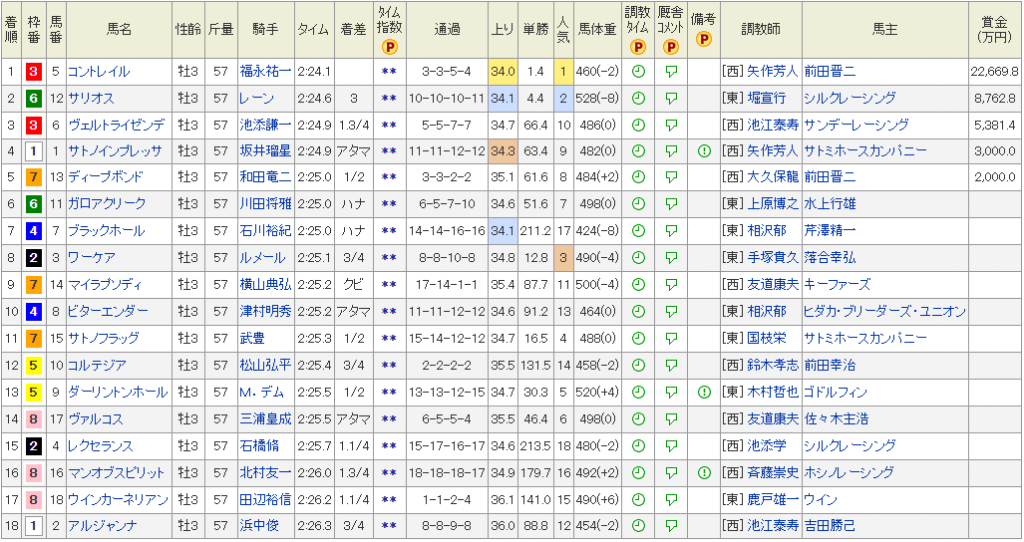
この部分です。
今回はオッズに関しては、取得しません。
オッズはオッズで、順位は順位で分けた方がよいです。
この順位の部分をスクレイピングします。
リスト型の2次元のデータに集約します。
そして、そのリスト型のデータをそのままCSVに出力していきます。
Pythonでやれば、簡単にCSVを作成できます。
for文でグルグル回す必要もありません。
あとは、ポイントはhtmlコーディングが古いということですね。
なんと、取得する箇所はtableタグです。
th、tr、tdなどが出てきます。
懐かしいです。
でも、若い人たちはtableタグなんて使ったことがないのでは?
そのようなWebの歴史にも触れることができます。
それで、基本的にはクラス名が指定されていません。
確かに、trやtdにクラスなんて指定しませんからね。
そこで、今回はtableの特徴を活かしてスクレイピングしています。
基本的には、順番が担保されているという特徴です。
tdを列結合しない限り、順番でデータ内容が担保されていると言えます。
見た限り、対象のtableでは列結合がないようです。
もう実際にコードを見ましょう。
コードを見るのが、何よりも理解を進めます。
【サンプルコード】netkeibaにおけるレース結果ページのスクレイピング
必要なモジュール・ライブラリが揃っていれば、コピペで動きます。
2020年09月26日時点は、モリモリと動いています。
import csv
import requests
import bs4
RACE_ID = "202005021211"
CSV_DIR = "./csv/"
URL_BASE = "https://db.netkeiba.com/race/"
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 '
}
# htmlソース取得
def get_text_from_page(url):
try:
res = requests.get(url, headers=HEADERS)
res.encoding = res.apparent_encoding
text = res.text
return text
except:
return None
# info取得
def get_info_from_text(header_flg, text):
try:
# データ
info = []
soup = bs4.BeautifulSoup(text, features='lxml')
# レース結果表示用のtable
base_elem = soup.find(class_="race_table_01 nk_tb_common")
# 行取得
elems = base_elem.find_all("tr")
for elem in elems:
row_info = []
# ヘッダーを除外するための情報
r_class = elem.get("class")
r_cols = None
if r_class==None:
# 列取得
r_cols = elem.find_all("td")
else:
# ヘッダー(先頭行)
if header_flg:
r_cols = elem.find_all("th")
if not r_cols==None:
for r_col in r_cols:
tmp_text = r_col.text
tmp_text = tmp_text.replace("\n", "")
row_info.append(tmp_text.strip())
info.append(row_info)
return info
except:
print("err")
return None
if __name__ == '__main__':
url = URL_BASE + RACE_ID
text = get_text_from_page(url)
info = get_info_from_text(False, text)
# csvファイル
file_path = CSV_DIR + RACE_ID + ".csv"
with open(file_path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerows(info)
例のごとく、コードの説明はしません。
これぐらいは理解できないと、コピペでの利用は危険だからです。
スクレイピングは使い方によっては、リスクを伴う技術です。
そうは言っても、スクレイピング自体は何も危険ではありません。
ただ、スクレイピングをやるためにアクセス過多になることが危険なのです。
Dos攻撃やF5アタックのようになる可能性があると言うことです。
今回のサンプルコードは、サーバーへの負荷を与えようがありませんけどね。
なぜなら、サイトへは1回しかアクセスしませんので。
あとは、仕様の補足を説明しておきます。
次の部分でCSVを作成しています。
# csvファイル
file_path = CSV_DIR + RACE_ID + ".csv"
with open(file_path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerows(info)
レースID名により、CSVファイルが作成されます。
レースIDは、レースページのURLを見ればわかります。

第87回東京優駿(G1)であれば、202005021211がレースIDです。
それにしても、Pythonは本当に便利です。
2次元のリスト型データ(info)を上記のように関数に渡すだけです。
これだけで、CSVが作成されるのですから。
最後に定数を説明しておきます。
変更すべきは以下の2箇所です。
RACE_ID = "202005021211" CSV_DIR = "./csv/"
RACE_IDは、上記で説明したレースIDです。
CSV_DIRは、CSVが保存されるディレクトリ(フォルダ)となります。
相対パス・絶対パスのどちらでも指定可能です。
追記 2021年2月21日
本記事はレース結果のスクレイピングがメインでした。
それ以前(レースIDを取得する)のスクレイピングに関しては、次の記事のシリーズで解説していきます。