
OCR(光学文字認識)は、画像内のテキストを自動的に認識・抽出する技術です。
本記事では、PaddleOCRを用いて、日本語の画像からテキストを抽出する方法を解説します。
PaddleOCRとは
PaddleOCRは、Baidu(百度)が開発したオープンソースのOCRライブラリです。
多言語対応しており、日本語にも対応しています。
高精度なテキスト認識が可能で、角度のある文字列も適切に処理できます。
このPaddleOCRの利用には、PaddlePaddleが必須となります。
PaddlePaddleについては、次の記事内で説明しています。

PaddlePaddleのインストールは、環境に合わせて行います。
PaddlePaddle(CPUのみを使用する場合)
pip install paddlepaddle
PaddlePaddle-GPU(GPUを使用する場合)
pip install paddlepaddle-gpu
PaddlePaddleがインストールできたら、PaddleOCRのインストールを行います。
pip install paddleocr
処理が完了したら、PaddleOCRのインストールは完了です。
画像からのテキスト抽出
PaddleOCRを使って、画像からテキストを抽出するPythonコードの例を以下に示します。
from paddleocr import PaddleOCR
def ocr_extract_text(image_path, lang='japan'):
"""
指定された画像ファイルからテキストを抽出します。
Args:
image_path (str): テキスト抽出対象の画像ファイルのパス
lang (str): 抽出するテキストの言語(デフォルトは'japan')
Returns:
str: 抽出されたテキスト、改行で区切られる
"""
# PaddleOCRインスタンスの生成、角度調整を有効化しGPUは使用しない
ocr = PaddleOCR(use_angle_cls=True, lang=lang, use_gpu=False)
# 画像からテキストを抽出、角度調整も適用
results = ocr.ocr(image_path, cls=True)
# 結果からテキストのみを抽出し、リストに格納
texts = []
for line in results:
for element in line:
texts.append(element[1][0]) # element[1] は ('テキスト', 確信度) のタプル
# テキストリストを改行文字で連結し、1つの文字列として返す
extracted_text = '\n'.join(texts)
return extracted_text
# 使用例
image_path = 'japanese.jpg'
text = ocr_extract_text(image_path)
print("抽出されたテキスト:")
print(text)
このコードでは、ocr_extract_text関数が画像ファイルのパスを受け取り、以下の処理を行います。
- PaddleOCRのインスタンスを生成。角度調整を有効化し、GPUは使用しない設定。
- ocrメソッドで画像からテキストを抽出。角度調整も適用。
- 抽出結果からテキストのみを取り出し、リストに格納。
- テキストリストを改行文字で連結し、1つの文字列として返す。
使用例では、japanese.jpgという画像ファイルからテキストを抽出し、結果を表示しています。
japanese.jpg

上記コードを実行した結果は、次のような結果となります。
抽出されたテキスト: ポイ捨て禁止 NO LITTER 清潔できれい な港区を の港 区 MINATO CITY
オープンソースの中では、もっとも精度が高いのではないでしょうか?
他の有力なオープンソースOCRであるEasyOCRの結果は、次の記事で説明しています。

記事的には古いですが、最新のバージョンでやっても同じ結果となります。
まとめ
PaddleOCRを使うことで、日本語を含む多言語の画像からテキストを簡単に抽出できます。
角度のある文字列にも対応しているため、幅広いシーンで活用できるでしょう。
本記事で紹介したコード例を参考に、ぜひ実際の画像でOCRを試してみてください。
なお、さらに精度の高いOCRがあります。
それは、Claude 3 Opus(課金)です。

完璧な結果となっています。
Claude 3については、次の記事で説明しています。

また、ChatGPT 4(課金)だと以下の結果となります。
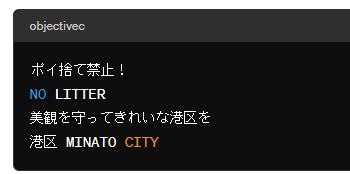
勝手に解釈していますよね。
「美観を守って」なんてどこにもありません。
ある意味、スゴイです。

