
PyAutoGUIの画像認識は、「ハンパねぇ」です。
この記事では、たった一つのことだけを学んで帰ってください。
それは、locateOnScreenによる画像認識です。
この機能を知って思わず、「マジか」と独り言を漏らしてしまいました。
本記事の内容
- PyAutoGUIの動作環境を整える
- 画像認識はあくまで認識に過ぎない
- 画像認識をアクションに結びつけるlocateOnScreen
- PyAutoGUIで画像認識のまとめ
それでは、上記に沿って解説していきます。
PyAutoGUIの動作環境を整える
動作環境を整えるのは、次の記事を参考にしてください。

上記記事を参考にすれば、早い人なら数分で終わります。
これ以降を読み進めるならば、是非ともPyAutoGUIの動作環境を整えてください。
「マジか」と漏らしたほどの機能を、みなさんにも実際に試して欲しいのです。
これが本当の画像認識だと感動します。
あと、OpenCVもインストールしておいてください。
こちらもコマンド一つで一瞬です。

OpenCVが必要な理由は、後ほど説明します。
それでは、以下でその感動する画像認識を説明していきます。
画像認識はあくまで認識に過ぎない
一般に画像認識と言うと、画像に何が写っているのかを認識する技術のことを指します。
画像に猫が写っているのか?
画像に犬が写っているのか?
このような感じですね。
そして、OCRも画像認識になるのでしょうね。
文字認識と表現した方が、身近なモノかもしれません。
OCRに関しては、次の記事で解説しています。

また、顔認識も画像認識の一つです。
OpenCVで簡単に行える顔認識を次の記事で解説しています。

今は何と言っても、ディープラーニングによる画像認識になります。
このように、画像認識に関しては身近な技術になってきています。
私自身もそこそこ触ってきています。
しかし、PyAutoGUIの画像認識は別次元です。
おそらく、画像認識の精度は機械学習の画像認識と比べて低いかもしれません。
でも、次元が違います。
認識精度という次元ではなく、PyAutoGUIの画像認識は行動につながっているのです。
画像を認識後に、何らかのアクション(処理)につなげることが簡単にできます。
認識と処理を連携させるプログラミングを簡単にコーディングできます。
この部分に感動して、「マジか」と漏らしました。
「認識と処理の連携」、この部分があまりにもスムーズに実現可能なのです。
是非、実際に手を動かしてその感動を体験してください。
以下では、その手順を説明します。
画像認識をアクションに結びつけるlocateOnScreen
まずは、仕様を定めましょう。
仕様は、何をどうするかということです。
仕様
今回は、次の仕様にしました。
「Evertnoteの新規ノートを自動で作成する」
不足していると思いますので、説明を追加しておきます。
普段、Evertnoteでブログを執筆しています。
以下は、EvernoteをPC上で起動させた状態です。
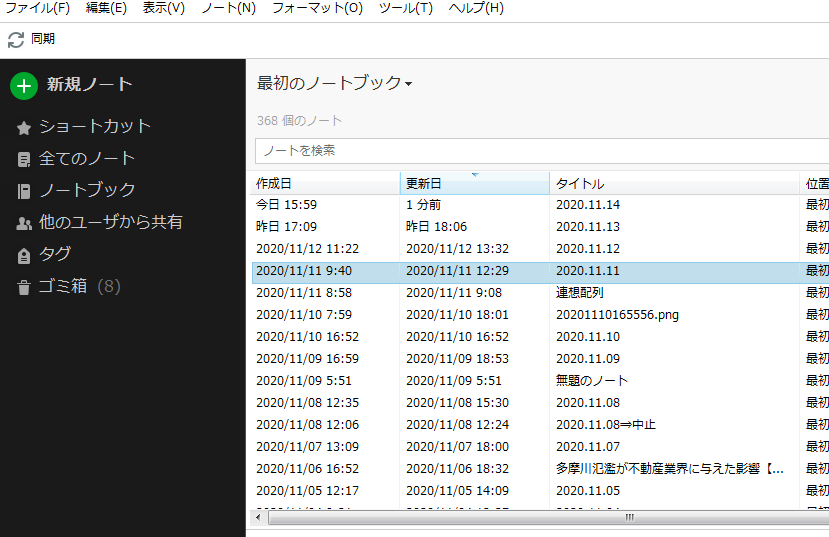
この状態から、次のボタンを自動でクリックするということを自動化します。
よって、スタートは上記画面の状態(アプリは起動後)です。
なお、「新規ノート」ボタンをクリックすると新規ノートが立ち上がります。
サンプルコード
クリックするボタン画像を用意します。
今回のケースならば、次の画像となります。
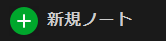
これをbtn.pngとします。
これが、仕様を実現するコードです。
import pyautogui
p = pyautogui.locateOnScreen("./img/btn.png")
x, y = pyautogui.center(p)
pyautogui.click(x, y)
コードの説明をしておきます。
ボタン画像の座標を取得して、x座標、y座標を取得。
その座標をクリックする、というだけです。
さらっと書きましたが、凄いと思いませんか?
用意したボタン画像を画面上から探しだして、座標を取得するのです。
そして、その座標位置をクリックするという流れになります。
さて、実際に動かしてみてどうでしょうか?
動きましたか?
動いたら、ラッキーです。
私の環境では、動きませんでした。
動かすためには、locateOnScreenにオプション追加する必要がありました。
それぞれ、両方で動作することを確認できています。
confidenceのみ追加
p = pyautogui.locateOnScreen("./img/btn.png",confidence=.5)
grayscaleとconfidenceを追加
p = pyautogui.locateOnScreen("./img/btn.png", grayscale=True, confidence=.6)
それぞれのオプションの説明は以下。
confidence
公式サイトより
https://pyautogui.readthedocs.io/en/latest/screenshot.html
画像を読み込めないときに、調整する変数ということです。
confidenceのみ追加の場合、0.5まで下げればコードが動きました。
画像の画質によって、その値は変わる可能性がありますね。
このconfidence変数の利用には、OpenCVが必須です。
だからこそ、OpenCVのインストールも案内しておきました。
grayscale
白黒にして、余計な情報を取り除くということです。
高速化するけど、誤検出もするかもしれないようになるかもということですね。
今回は、grayscale=Trueにすることで、confidenceの値が0.6で済みました。
白黒にすれば、精度を少しだけ下げる必要がなかったという結果です。
この部分の調整は、状況に応じて変更していくしかないでしょうね。
PyAutoGUIで画像認識のまとめ
一つだけ学べたでしょうか?
変数がどうのこうのとありましたが、言いたいことは以下の一つだけです。
「PyAutoGUIを使えば、画像認識からの処理への連携が容易に実現できる」
これだけでも学んで帰ってもらえたら、記事を書いた甲斐があります。
プログラマーとして、必ずどこかで役に立つ知識だと考えています。
私は、PyAutoGUIにかなり可能性を感じました。
プログラミングをする上で、新たな扉を開くことができたという感覚です。
Seleniumを使ってWebページをスクレイピングすることは、容易に実現可能です。
Seleniumに関しては、散々このブログでは記事にしています。



このSeleniumとPyAutoGUIを組み合わせれば、できることの幅が広がります。
結局、PyAutoGUIは実際に処理を行なえるというのがデカイのですよね。
あんなことや、こんなことや、いろいろとできそうです。
追記 2021年11月21日
次の記事では、PyAutoGUIによる画像認識の精度を上げる方法をまとめています。


