
PythonでWord Cloud(ワードクラウド)を作成できます。
それも次のような特徴あるWord Cloudが作成できるのです。

しかし、これを自力でやろうとすると大変です。
そこで、ライブラリの出番となります。
Pythonには、便利なライブラリがすでに用意されています。
それは、word_cloudライブラリです。
- word_cloudとは?
- word_cloudのシステム要件
- word_cloudのインストール
- word_cloudの動作確認
- word_cloudの課題
それでは、上記に沿って解説していきます。
word_cloudとは?
Word Cloud(ワードクラウド)は、もう一般的な用語になっていますよね。
それだけで伝わる人には伝わります。
用語は知らなくても、見たらわかるぐらいに普及しているレベルです。
そのワードクラウドをPythonで作るためのライブラリが、存在しています。
それが、word_cloudとなります。
word_cloudの公式ページ
http://amueller.github.io/word_cloud/
word_cloudとは、PythonでWordCloud(ワードクラウド)を作成するためのライブラリです。
特徴としては、以下の4つが公式に記載されています。
- 利用可能なスペースをすべて埋める
- 任意のマスクを利用できる
- 容易に変更可能な単純なアルゴリズムである
- Pythonである
任意のマスクだけ説明が、必要かもしれません。
以下を見れば、その意味がわかるでしょう。

上記のようなマスク用の画像を用意するのです。
そうすれば、冒頭に載せたWord Cloudが出来上がります。
※マスクは、画像である必要はありません。
確かに、これは特筆すべきポイントでしょう。
では、こんな特徴のあるword_cloudはどのような環境で動くのでしょうか?
word_cloudのシステム要件を確認しましょう。
word_cloudのシステム要件
word_cloudのGitHubページ
https://github.com/amueller/word_cloud
word_cloudの最新バージョンは、1.8.1となります。
この最新バージョンは、2020年11月12日にリリースされています。
対応OSでは、注意が必要です。
word_cloudが対応しているOSは、以下。
- Windows
- Linux
macOSが対応していません。
もしかしたら、依存ライブラリの数が多いことが影響しているのかもしれません。
依存ライブラリに関しては、word_cloudのインストールのところで確認しましょう。
あと、Pythonのバージョンは以下がテスト済みとのこと。
- Python 2.7
- Python 3.4
- Python 3.5
- Python 3.6
- Python 3.7
上記の実績があるなら、最新版でも問題ないでしょう。
ちなみに、私の環境は以下。
以上、word_cloudのシステム要件です。
次では、word_cloudをWindows環境でインストールしていきます。
>python -V Python 3.9.1
word_cloudのインストール
最初に、現状のインストール済みパッケージを確認しておきます。
>pip list Package Version ---------- ------- pip 21.0 setuptools 52.0.0
次にするべきことは、pip自体の更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
pip install wordcloud
インストールは、そこそこ時間がかかります。
では、どんなパッケージがインストールされたのかを確認しましょう。
>pip list Package Version --------------- ------- cycler 0.10.0 kiwisolver 1.3.1 matplotlib 3.3.3 numpy 1.19.5 Pillow 8.1.0 pip 21.0 pyparsing 2.4.7 python-dateutil 2.8.1 setuptools 52.0.0 six 1.15.0 wordcloud 1.8.1
これだけ依存するライブラリが多いのは、なかなか珍しいです。
word_cloudがmacOSをサポートできていない原因かもしれません。
あくまで、個人的な推測です。
以上、word_cloudのインストールでした。
最後に、word_cloudの動作確認を行います。
word_cloudの動作確認
word_cloudの動作確認用プログラムは、以下。
from wordcloud import WordCloud
# テキストファイル読み込み
text = open("constitution.txt", encoding="utf8").read()
# 画像作成
wordcloud = WordCloud(max_font_size=40).generate(text)
# 画像保存
wordcloud.to_file("result.png")
上記プログラムのスクリプトと同じ場所に「constitution.txt」を用意します。
このファイルは、以下のURLからダウンロードできます。
https://github.com/amueller/word_cloud/blob/master/examples/constitution.txt
「constitution.txt」を設置したら、プログラムを実行します。
実行した結果、同じ場所に「my.png」が作成されます。
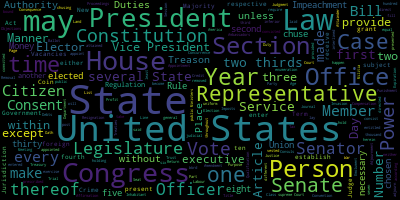
簡単にワードクラウドが作成できました。
以上、word_cloudの動作確認は完了です。
確かに、動作はこれでOK。
しかし、このままでは肝心の日本語で使い物になりません。
そのことは、日本人の我々からしたら非常に大きな課題です。
この課題について、最後に説明しておきます。
word_cloudの課題
上記の動作確認用プログラムでは、ファイルを便宜上ファイルを読み込んでいます。
しかし、別にファイルを読み込む必要はありません。
変数「text」に文字列が入れば、それでOKです。
その文字列から単語を取得して、 word_cloudは頻出率を計算しています。
そして、その頻出率に応じて、 word_cloudはフォントの大きさを決定しているのでしょう。
「文字列から単語を取得」
このことは、英語なら何も問題はありません。
なぜなら、英語では文字列から単語を抽出できるからです。
「constitution.txt」より、一部を表示しています。
We the People of the United States
「We」と「People」の間には、スペースが区切りとなって存在しています。
だから、文字列から単語を抜き出すことができます。
しかし、日本語ではそれができません。
先ほどの例文を日本語に訳すと以下となります。
私たちはアメリカ人です
区切りとなるスペースが存在しません。
さて、困りました。
これが、word_cloudの課題となります。
この課題の解決方法は、別の記事で解説します。
追記 2021年1月29日
課題を解決する方法を次の記事でまとめています。


