「RVCやso-vits-svcの学習素材として音声を分割したい」
「朗読や演説などを機械学習の学習素材として用いたい」
このような場合には、この記事の内容が参考になります。
この記事では、Pythonを用いた発話分割について解説しています。
本記事の内容
- 発話分割とは?
- 発話分割のためのシステム要件
- Pythonによる発話分割
それでは、上記に沿って解説していきます。
発話分割とは?
発話分割とは、音声を発話単位に分割することを意味します。
まあ、そのまんまですね。
発話分割は、音声データを扱う際に重要なプロセスとなります。
発話分割を行う利点には、以下があります。
- 音声認識の精度向上
- 音声対話システムの応答性向上
- 音声分析の正確性向上
- 音声データの編集や整理の効率化
- トランスクリプションの正確性向上
迅速で正確な音声データの解析・処理には、発話分割が欠かせないということです。
そんな発話分割を行うには、次のようなアプリを利用するのもありでしょう。
- Audiobook Cutter(デスクトップアプリケーション)
- Audacity(オープンソースの音声編集ソフトウェア)
しかし、個人的にはPythonで行いたいです。
そちらの方が拡張性がありますからね。
あとは、Pythonは自動化なども簡単に対応できます。
そのため、この記事ではPythonを用いた発話分割を説明します。
以上、発話分割について説明しました。
次は、発話分割のためのシステム要件を説明します。
発話分割のためのシステム要件
まずは、Pythonが何よりも必要となります。
以下は、Python公式開発サイクルになります。
| バージョン | リリース日 | サポート期限 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
| 3.11 | 2022年10月25日 | 2027年10月 |
Python 3.7については、サポート対象外とするライブラリが増えてきました。
したがって、Python 3.8以降を利用するようにしましょう。
そして、発話分割に必要となるのは次のライブラリです。
- Pydub
- librosa
これらのインストールが必要です。
それぞれのインストール方法は、以下で解説しています。


バージョンは、現時点での最新版をインストールしましょう。
以上、発話分割のためのシステム要件を説明しました。
次は、Pythonによる発話分割を説明します。
Pythonによる発話分割
システム要件が整っていれば、次のコードを実行するだけです。
もちろん、音声ファイル(input/test.wav)と出力先のディレクトリ(output)は用意しましょう。
import librosa
from pydub import AudioSegment
from pydub.silence import split_on_silence
# 音声ファイルを読み込む
file_path = 'input/test.wav'
audio, sr = librosa.load(file_path, sr=None)
# 音声ファイルの長さを取得
duration = librosa.get_duration(y=audio, sr=sr)
# pydub用にAudioSegmentオブジェクトに変換
audio_segment = AudioSegment.from_wav(file_path)
# 音声ファイルを発話単位に分割
chunks = split_on_silence(
audio_segment,
min_silence_len=500, # 無音の最小長さ(ミリ秒)
silence_thresh=-40 # 無音と判断する音量閾値(dBFS)
)
# 分割した発話を個別のファイルに保存
for i, chunk in enumerate(chunks):
chunk.export(f"output/speech_{i}.wav", format="wav")
処理が完了すると、出力先のディレクトリには連番でファイルが保存されています。
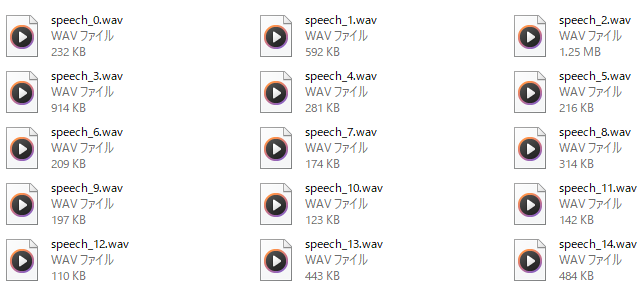
40分ほどの音声データ(朗読)でも、2分ほどで処理が終わっています。
マシンスペックにもよって、多少は処理時間が異なるでしょう。
ちなみに40分の音声データは、1090個のWAVファイルに分割されました。
以上、Pythonによる発話分割を説明しました。