この記事は、pytrendsの使い方をまとめています。
pytrendsのインストールは、次の記事にまとめています。
pytrendsのインストール方法【グーグル(検索)トレンド】
インストールがまだの場合、上記記事をご覧ください。
インストールしている前提で話を進めていきます。
本記事の内容
- APIへの接続
- APIの共通パラメータ
- API関数
API関数は、実際に動くコードとともに説明しています。
APIへの接続
Googleへ接続
pytrendsを利用する際は、必ず記述します。
このコードにより、Google Trendsに接続しています。
from pytrends.request import TrendReq pytrends = TrendReq(hl='ja-JP', tz=-540)
基本的には、上記のコードでGoogleへ接続可能です。
しかし、Googleから利用制限を受けている場合は、そうではありません。
短時間の間に、Googleに対してプログラムなどでアクセスすれば利用制限を受けることがあります。
このように利用制限を受けている場合の抜け道が、用意されています。
そのコードが以下。
from pytrends.request import TrendReq pytrends = TrendReq(hl='ja-JP', tz=-540, timeout=(10,25), proxies=['https://34.203.233.13:80',], retries=2, backoff_factor=0.1)
抜け道のポイントは、proxiesです。
プロキシ設定ですね。
複数のプロキシを指定する場合は、次のように記述します。
[‘https://34.203.233.13:80′,’https://35.201.123.31:880’, …, …]
要するに、プロキシ経由でGoogleに接続するということです。
そうすれば、利用制限も関係なくなりますよね。
余談になりますが、プロキシ経由で利用制限を突破するケースが多いです。
Googleの画像認証を突破するサービスでも、プロキシ経由のオプションがありました。
そのサービスに関しては、下記記事で説明しています。

Googleのサービスへプログラムで大量にアクセスする場合、プロキシ経由は必要ということなのでしょう。
検索条件の事前セット
Google Trendsで検索する情報をセットするコードです。
関数においてもセットするパターン、事前にセットするパターンが存在します。
kw_list = ["Twitter"] pytrends.build_payload(kw_list, cat=0, timeframe='today 5-y', geo='JP', gprop='')
パラメータについては、以下で説明します。
APIの共通パラメータ
関数で共通に用いられるパラメータを説明していきます。
kw_list
検索するキーワードです。
複数指定は、以下のようにリストで記述します。
kw_list = ["Twitter","Facebook","Instagram","LINE","YouTube"]
cat
対象とするカテゴリーです。
これを指定すれば、検索範囲を絞ることができます。
指定する値は、以下ページを参照。
https://github.com/pat310/google-trends-api/wiki/Google-Trends-Categories
または、API関数categories()の戻り値を参照。
指定しない場合は、カテゴリー指定なしとなります。
また、「0」は、カテゴリー指定なしと同じことです。
timeframe
対象とする期間です。
指定しない場合は、5年間です。
指定方法は、以下。
| 設定値 | 対象期間 |
| 2019-01-01 2020-05-22 | 2019-01-01 2020-05-22(期間により変動) |
| today 5-y | 5年間(1週間毎) |
| today #-m | #(1,2,3のみ指定可)ヶ月間(1日毎) |
| now #-d | #(1,7のみ指定可)日間(8分、1時間毎) |
| now #-H | #(1,4のみ指定可)時間(1分毎) |
設定値により、データの粒度も変わります。
ここで言う粒度には、1週間毎、1日毎、8分毎、1分毎の時間間隔です。
対象期間が270日より大きくなれば、粒度は1週間になります。
逆に言えば、270日以内であれば、粒度は1日毎ということです。
geo
対象とする地域です。
指定しない場合は、全世界対象です。
日本のみを対象とする場合、「JP」と記述します。
また、さらに地域を絞ることができます。
2文字の略称を追加すれば、絞り込みが可能のようです。
アラバマ州(Alabama:AL)なら、 「US-AL」と記述します。
しかし、日本においては指定方法が異なります。
そもそも、都道府県の英字2文字の略称なんて見たこともありません。
日本の場合は、都道府県コードを設定します。
正確には、ISO 3166-2:JPを記述すればよいです。

例えば、大阪を指定する場合は、「JP-27」と記述します。
これにより、大阪まで地域を絞り込むことが可能となります。
gprop
対象とするフィルターです。
以下のことですね。

指定しない場合は、「すべて」となります。
設定できる値は、以下。
| 設定値 | フィルター名 |
| images | 画像 |
| youtube | 動画 |
| news | ニュース |
| froogle | ショッピング |
tz
世界標準時(UTC)に合わせる場合に指定します。
設定する値は、分単位です。
日本の標準時(JST)は、「UTC」よりも 9時間進んでいるため「UTC+09:00」と表示されます。
そして、9時間をマイナスにすればUTCに合わせることができます。
9時間は、540分です。
そのため、「-540」と設定することになります。
ただ、このパラメータの値による効果があるのかは不明です。
API関数
関数にパラメータがない場合は、次のコードで事前に設定します。
pytrends.build_payload(kw_list, cat=0, timeframe='today 5-y', geo='JP', gprop='')
また、関数の戻り値の構造は、DataFrame(Pandas)と辞書型の二つです。
Interest Over Time
戻り値:DataFrame
トレンドの時系列変化を取得します。
Google Trends上では、「Interest over time」項目のデータです。
実際の使い方は、build_payloadの後になるでしょう。
kw_list = ["Twitter"] pytrends.build_payload(kw_list, cat=0, timeframe='2020-05-10 2020-05-20', geo='JP', gprop='') df = pytrends.interest_over_time() print(df)
上記コードの実行結果です。
Twitter isPartial
date
2020-05-10 99 False
2020-05-11 97 False
2020-05-12 92 False
2020-05-13 100 False
2020-05-14 98 False
2020-05-15 92 False
2020-05-16 91 False
2020-05-17 95 False
2020-05-18 89 False
2020-05-19 93 False
Historical Hourly Interest
pytrends.get_historical_interest(kw_list, year_start=2018, month_start=1, day_start=1, hour_start=0, year_end=2018, month_end=2, day_end=1, hour_end=0, cat=0, geo='', gprop='', sleep=0)
戻り値:DataFrame
指定期間における1時間毎の時系列データを取得します。
1時間単位でデータを取得するため、指定する期間には注意です。
kw_list
必須項目です。
year_start, month_start, day_start, hour_start, year_end, month_end, day_end, hour_end
必須ではありませんが、設定しましょう。
そうしないと、Googleから返答が戻ってきません。
そして、設定する期間はなるべく短くしましょう。
sleep
Googleから利用制限を受けた場合に設定します。
設定する値(数値)が大きいほど、Googleへのアクセスする間隔時間を大きくするようです。
キーワードに「Twitter」を設定します。
期間は、10日間です。
kw_list = ["Twitter"]
df = pytrends.get_historical_interest(kw_list,
year_start=2020,
month_start=5,
day_start=10,
hour_start=0,
year_end=2020,
month_end=5,
day_end=20,
hour_end=0,
geo='JP',
sleep=0)
print(df)
上記コードの実行結果です。
Twitter isPartial
date
2020-05-10 00:00:00 0 False
2020-05-10 01:00:00 0 False
2020-05-10 02:00:00 49 False
... ...
2020-05-19 22:00:00 71 False
2020-05-19 23:00:00 69 False
2020-05-20 00:00:00 59 False
Interest by Region
pytrends.interest_by_region(resolution='COUNTRY', inc_low_vol=True, inc_geo_code=False)
戻り値:DataFrame
地域毎のデータを取得します。
Google Trends上では、「Interest by subregion」項目のデータです。
resolution
設定可能な値は以下。
- CITY
- COUNTRY
- DMA
- REGION
機能しているを確認できたのは、COUNTRYとCITYだけです。
実行の箇所で説明します。
inc_low_vol
TrueとFalseのどちらかを設定します。
しかし、機能していません。
inc_geo_code
Trueの場合、地域のISOコードを取得します。
Falseの場合、地域のISOコードを取得しません。
【COUNTRYの場合】
kw_list = ["Twitter"] pytrends.build_payload(kw_list, timeframe='2020-04-01 2020-05-20', geo='') df = pytrends.interest_by_region(resolution='COUNTRY', inc_low_vol=True, inc_geo_code=True) print(df)
上記コードの実行結果です。
geoCode Twitter
geoName
アイスランド IS 15
アイルランド IE 49
アゼルバイジャン AZ 10
アフガニスタン AF 18
アメリカ合衆国 US 22
アラブ首長国連邦 AE 30
アルジェリア DZ 10
アルゼンチン AR 32
アルバ AW 13
アルバニア AL 9
【CITYの場合】
kw_list = ["Twitter"] pytrends.build_payload(kw_list, timeframe='2020-04-01 2020-05-20', geo='JP') df = pytrends.interest_by_region(resolution='CITY', inc_low_vol=True, inc_geo_code=True) print(df.head(10))
上記コードの実行結果です。
geoCode Twitter
geoName
三重県 JP-24 67
京都府 JP-26 71
佐賀県 JP-41 70
兵庫県 JP-28 69
北海道 JP-01 78
千葉県 JP-12 74
和歌山県 JP-30 66
埼玉県 JP-11 74
大分県 JP-44 74
大阪府 JP-27 66
Related Topics
pytrends.related_topics()
戻り値:DataFrame
キーワードの関連トピックを取得します。
Google Trends上では、「Related topics」項目のデータです。
「Top」と「Rising」を同時に取得します。
次のコードは結果を工夫して、表示するようにしています。
Pandasのデータフレーム操作の理解が必要です。
keyword = "SEO" kw_list = [keyword] pytrends.build_payload(kw_list, timeframe='2019-01-01 2019-12-31', geo='JP') df = pytrends.related_topics() print(df[keyword]['top'].loc[:,['topic_title','value']].head(10)) print(df[keyword]['rising'].loc[:,['topic_title','value']].head(10))
上記コードの実行結果です。
上の表示部分は、「Related topics」の「Top」です。
下の表示部分は、「Related topics」の「Rising」です。
topic_title value 0 検索エンジン最適化 100 1 株式 8 2 ウェブサイト 7 3 Google 検索 6 4 WordPress 5 5 ViVi 4 6 ホームページ 3 7 検索エンジン 3 8 ニャース 2 9 広告 2 topic_title value 0 モデーア 41250 1 ジオコード 2550 2 ViVi 300 3 MEO 250 4 索引語 190 5 パク・ソジュン 180 6 見出し 150 7 会社 130 8 はてなブログ 110 9 筆記 90
Related Queries
戻り値:DataFrame
キーワードの関連キーワードを取得します。
Google Trends上では、「Related queries」項目のデータです。
「Top」と「Rising」を同時に取得します。
次のコードは結果を工夫して、表示するようにしています。
Pandasのデータフレーム操作の理解が必要です。
keyword = "SEO" kw_list = [keyword] pytrends.build_payload(kw_list, timeframe='2019-01-01 2019-12-31', geo='JP') df = pytrends.related_queries() print(df[keyword]['top'].head(10)) print(df[keyword]['rising'].head(10))
上記コードの実行結果です。
上の表示部分は、「Related queries」の「Top」です。
下の表示部分は、「Related queries」の「Rising」です。
query value
0 seo 対策 100
1 seo 会社 44
2 seo 対策 会社 34
3 google seo 22
4 逆 seo 対策 21
5 seo 対策 nya s com ニャース vivi 21
6 seo 検索 20
7 ブログ seo 18
8 seo チェキ 16
9 wordpress 13
query value
0 ジオコード seo 対策 という ワード で 1 位 取れ ない 101350
1 モデーア ワンダーランド 33250
2 逆 seo nya s com vivi 専門 24950
3 逆 seo 株式 会社 ニャース 相談 vivi 18700
4 誹謗 中傷 対策 seo 対策 vivi 株式 会社 ニャース nya s com 画像 検... 17800
5 逆 seo 対策 vivi 集客 ニャース 17400
6 逆 seo vivi 集客 ニャース 17150
7 知恵袋 削除 seo 対策 vivi 株式 会社 ニャース nya s com 風評 対策 ... 15600
8 逆 seo 管理 nya s com vivi 14350
9 知恵袋 削除 seo 対策 vivi 株式 会社 ニャース nya s com 虫眼鏡 出来... 12750
Trending Searches
pytrends.trending_searches(pn='japan') # Japan
戻り値:DataFrame
Googleトレンドを取得します。
Google Trends上では、「Recently trending」項目のデータです。
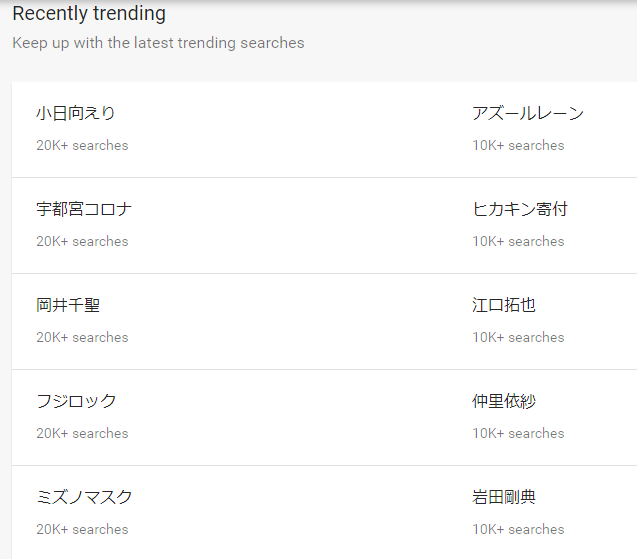
pnを指定します。
アメリカのGoogleトレンドを取得する場合、「united_states」を指定します。
df = pytrends.trending_searches(pn='japan') # Japan print(df)
上記コードの実行結果です。
0
0 小日向えり
1 宇都宮コロナ
2 岡井千聖
3 フジロック
4 ミズノマスク
5 アズールレーン
6 ヒカキン寄付
7 江口拓也
8 仲里依紗
9 岩田剛典
10 大阪緊急事態宣言
11 賭博罪
12 高嶋ちさ子
13 ムビラ
14 装甲娘
15 バーガーキング
16 名探偵ピカチュウ
17 安倍昭恵
18 新た真剣佑
19 種苗法
上の画像と同じ結果ですね。
上位20個まで取得できます。
Top Charts
pytrends.top_charts(date, hl='en-US', tz=300, geo='GLOBAL')
戻り値:DataFrame
トップチャートを取得します。
しかし、動きません。
おそらく、Google側におけるトップチャートの仕様が変更したためだと思います。
月間トップチャートなるものが、Google Trends上では存在しません。
どうやら、以前には存在したようですが・・・
今でも、年間トップチャートは見れるようです。
ただ、仕様が変更したので年間トップチャートも取得できないものだと思われます。
Suggestions
pytrends.suggestions(keyword)
戻り値:dictionary
サジェストキーワードを取得します。
keyword
必須項目です。
複数指定は、不可。
「Twitter」を設定します。
dc= pytrends.suggestions('Twitter')
print(dc)
上記コードの実行結果です。
[{'mid': '/m/0289n8t', 'title': 'Twitter', 'type': 'ソーシャル・ネットワーキング・サービス'},
{'mid': '/m/0hn1vcg', 'title': 'Twitter', 'type': 'ソーシャル・ネットワーキング・サービス'},
{'mid': '/g/1hf2gj_r3', 'title': 'Twitter', 'type': 'トピック'},
{'mid': '/g/11c70hxsh1', 'title': 'Twitter', 'type': 'インド ムザファルプルのメディア会社'},
{'mid': '/m/065_v72', 'title': 'Eial Strahman', 'type': 'サッカー選手'}]
結果は、Googleのサジェストとは明らかに違います。
キーワードプランナーで出力されるものを使う方がよいでしょう。
Categories
pytrends.categories()
戻り値:dictionary
Google Trends上のカテゴリ一覧を取得します。
dc = pytrends.categories() print(dc)
上記コードの実行結果です。
{'children': [{'children': [{'children': [{'name': 'クラブ、ナイトライフ', 'id': 188}, {'name': 'コンサート、音楽祭', 'id': 891}, {'name': 'スポーツ観戦', 'id': 1273}, {'name': 'チケット販売', 'id': 614},
... ...
省略していますが、大きいデータが取得されています。

