
「YouTubeチャンネル分析を行いたい」
「競合チャンネルにおける全動画の再生数と評価を取得したい」
「YouTubeのAPIが使いモノにならない」
「YouTubeをスクレイピングしようと考えている」
このような場合には、この記事が参考となるでしょう。
この記事では、チャンネル分析のためにデータ収集する方法を解説しています。
本記事の内容
- YouTubeチャンネル分析とは?
- YouTubeチャンネル分析用のデータ収集
- データ収集に必要なモノ
- 【動作確認】データ収集のコード
それでは、上記に沿って解説していきます。
YouTubeチャンネル分析とは?
ここでいうYouTubeチャンネル分析とは、特定チャンネルの動画を分析することです。
高評価の動画・再生回数の多い動画などを見つけたりすることが、主な作業になります。
競合調査で行われることが、多いでしょう。
チャンネル分析を行うためには、対象チャンネルの動画情報が必要になります。
- タイトル
- サムネイル
- 評価
- 再生回数
これらの情報があれば、最低限のYouTubeチャンネル分析ができます。
また、評価とはaverageRatingというデータのことです。
averageRatingは、高評価と低評価の数をもとに算出されている値になります。
具体的な計算式は、わかりません。
でも、動画の質を評価するのに使えそうな値と言えます。
例えば、次のような評価の動画があるとします。

この場合のaverageRatingは、次の値となります。
5に近いほど高評価率が高い動画のようです。

なお、averageRatingは基本的にはユーザーが目にすることはありません。
htmlソースにjson形式で出力されています。
Chromeなら、「ページのソースを表示」でhtmlソースを表示することが可能です。
以上、YouTubeチャンネル分析について説明しました。
次は、YouTubeチャンネル分析用のデータ収集について確認します。
YouTubeチャンネル分析用のデータ収集
YouTubeからデータを集めるには、基本的にはAPIの利用が考えられます。
YouTubeでは、YouTube Data APIが一般に公開されています。
しかし、大抵の場合にAPIは使い物になりません。
なぜなら、利用制限などがあるからです。
それに大量のデータを取得するという用途では、APIが設計されていません。
よって、APIの利用は却下です。
(※ただし、pytube内部でAPIを利用している可能性あり)
そうなると、スクレイピングとなります。
実際、スクレイピングでもデータを集めることは可能です。
ただ、YouTubeは動的にコンテンツが作成されます。
スクロールする度にコンテンツが追記されていきますよね。
このような動的ページの場合は、スクレイピングの難易度が一気に上がります。
それでも、Seleniumを使えば対応可能ですけどね。
Seleniumについては、次のページで解説しています。

Seleniumを使う手段もありますが、今回はもっと簡単にできる方法を採用します。
以下では、そのために必要なモノを説明します。
データ収集に必要なモノ
まずは、必要なモノを挙げます。
Pythonの利用は、大前提とします。
- pytube
- SQLite
それぞれを以下で説明します。
pytube
YouTubeからデータを集めてくるのは、pytubeを利用します。
pytubeについては、次の記事で説明しています。

pytubeは、動画のダウンロードがフォーカスされがちです。
しかし、ダウンロード以外でも、利用することができます。
SQLite
対象のチャンネルに数個の動画しかないなら、SQLiteは不要です。
ただ、そんなことは実際にはないでしょう。
数個の動画しかないなら、そもそも分析なんてする価値がありません。
通常は、数多くの動画が存在しているはずです。
そうなってくると、取得したデータをどこかに保存する必要が出てきます。
そこで、簡易データベースであるSQLiteを利用します。
Pythonであれば、追加インストールなしでSQLiteを利用できます。
そのことについては、次の記事で説明しています。

ただ、GUIでSQLiteを操作できた方が便利です。
Windowsであれば、HeidiSQLを管理ツールとして利用するのもアリです。

ソフトウェアのインストールが嫌であれば、sqlite-webがおススメです。
sqlite-webは、WindowsでもLinux・macOSでも利用できます。

以上、データ収集に必要なモノを説明しました。
次は、動作確認のために用意したデータ収集のコードを確認します。
【動作確認】データ収集のコード
まずは、動画情報を取得したいチャンネルのURLを用意します。
料理研究家リュウジのバズレシピ
https://www.youtube.com/channel/UCW01sMEVYQdhcvkrhbxdBpw
検証では、上記のチャンネルを分析するためにデータ収集を行います。
2021年11月時点でのチャンネル登録者数は、 240万人の大きなチャンネルです。
動画も全部で600個以上あります。
それでは、この600個オーバーの動画情報を取得していきます。
そのためのコードは、以下。
from pytube import Channel
import sqlite3
import traceback
# sqlite3
DB_NAME = "youtube.sqlite3"
# チャンネルURL
CHANNEL_URL = 'https://www.youtube.com/channel/UCW01sMEVYQdhcvkrhbxdBpw'
# データ登録
def entry_data(conn, info):
sql = "INSERT INTO video (video_id, title, publish_date, description, thumbnail_url, rating, views) "
sql = sql + "VALUES( ?, ?, ?, ?, ?, ?, ?);"
insert_data = [info.video_id, info.title, info.publish_date, info.description, info.thumbnail_url, info.rating, info.views]
try:
cur = conn.cursor()
cur.execute(sql, insert_data)
except Exception as e:
print("Exception\n" + traceback.format_exc())
print(sql)
c = Channel(CHANNEL_URL)
# チャンネル名
print(f'チャンネル名: {c.channel_name}')
# データベースファイルの指定
dbname = DB_NAME
# DB接続
conn = sqlite3.connect(dbname, isolation_level=None)
print(c.videos)
# for video in c.videos:
# # 動画情報を登録
# entry_data(conn, video)
# DB切断
conn.close()
上記を実行すると、予め用意したSQLiteにデータが登録されていきます。
全動画の情報を取得するまで、プログラムが動きます。
結果的には、643個の動画情報を取得しています。
そのうちの一部が、以下のように保存されています。
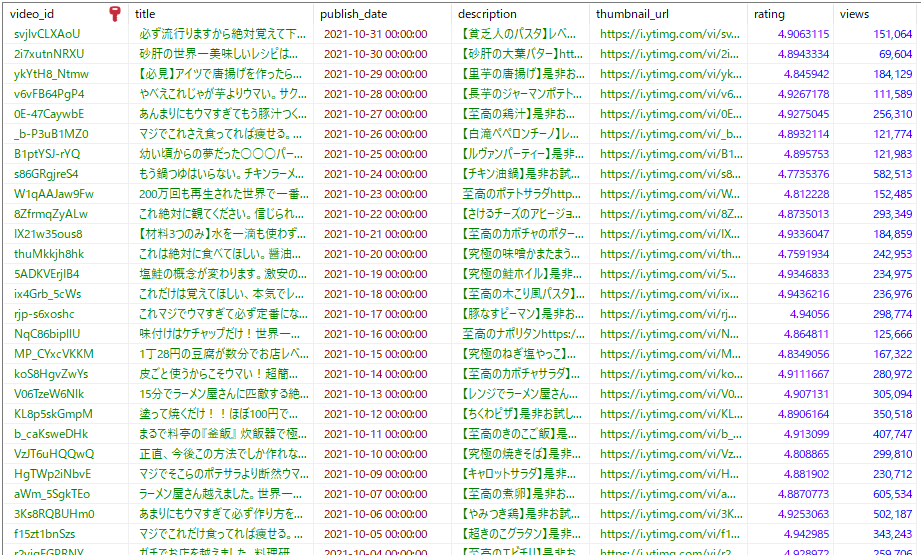
上記は、コード上に出てくる「video」テーブルです。
「video」テーブルのテーブル定義は、以下。
CREATE TABLE "video" ( "video_id" VARCHAR(255) NULL, "title" VARCHAR(255) NULL, "publish_date" DATETIME NULL, "description" TEXT NULL, "thumbnail_url" TEXT NULL, "rating" REAL NULL, "views" INTEGER NULL ) ;
あと、「video_id」にはユニーク制約を付けています。
上記にあるデータ以外には、動画の長さなどもあります。
他にも取得可能なデータは、次のページで確認できます。
pytube公式のドキュメント
https://pytube.io/en/latest/api.html#youtube-object
以上、【動作確認】データ収集のコードについて説明しました。

