
Twitterのスクレイピングに興味がありますか?
それなら、まずは次の記事をご覧ください。

上の記事では、本記事を読む上で必ず理解しておくべき内容を記載しています。
面倒だとは思いますが、流し読みでも構いませんので一読を。
では、この記事の内容に話を戻しましょう。
ズバリ、Twitterをスクレイピングする方法を解説しています。
コードも載せています。
本記事の内容
- Twitterのスクレイピング戦略
- JavaScriptによる動的コンテンツの読み込み
- スクロールによる追加コンテンツの読み込み
- IDやCLASS名で特定困難なタグ構成への対応
- 完成したコード
それでは、上記に沿って解説を行っていきます。
Twitterのスクレイピング戦略
戦略とは、大袈裟ですね。
仕様だと思ってください。
まず、初めに言っておきます。
関連記事でも言ったかもしれませんが。
Twitterは、最高レベルのスクレイピング防御力を誇ります。
私は、スクレイピングが本業(?)ではありません。
でも、かれこれ10年ほどの経験があります。
PHPで対応可能なら、PHPを利用。
PHP単独で無理なら、PhantomJSの力を借りていました。
現在は、Pythonでスクレイピングをしています。
理由は簡単。
Seleniumを用いるからです。
Seleniumに関しては、次の記事でまとめています。

話を戦略に戻しましょう。
戦略は、「ブラウザを使ってTwitterを見るように、スクレイピングを行う」です。
よって、本当にブラウザを動かす必要があります。
そのためには、Seleniumが必須です。
Seleniumなしでは、Twitterをスクレイピングはできません。
技術的には可能かもしれませんが、かなり面倒になるでしょう。
なぜ、Seleniumが必須なのか?
それは、以下の理由です。
- JavaScriptにより動的コンテンツを表示している
- スクロールにより追加コンテンツを表示している(改ページの概念がない)
動的コンテンツは、Seleniumなしでも何とかなります。
でも、スクロール処理はSeleniumの力が必要です。
他には、Node.jsと言う手があるかもしれませんけどね。
では、Seleniumを使ってTwitterを攻略していきます。
上記であげた2点がポイントです。
JavaScriptによる動的コンテンツの読み込み
「JavaScriptにより動的コンテンツを表示している」に対応します。
まずは、ツイートのタグ構成を確認しましょう。
各ツイートは、articleタグで表現されています。
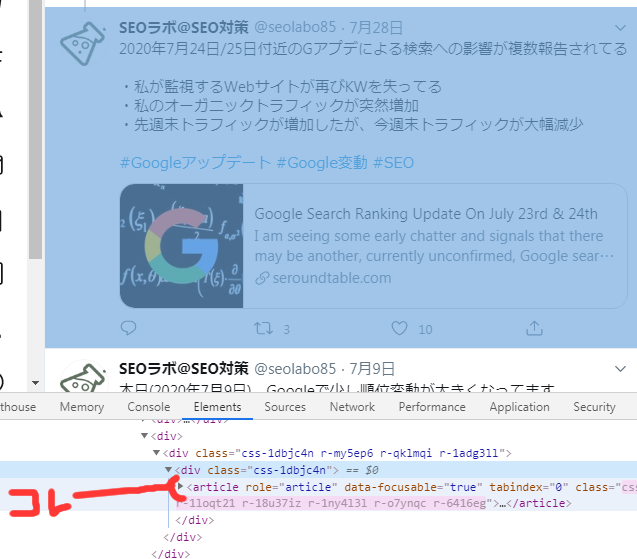
これらは、jsで読み込んだコンテンツです。
動的コンテンツ(js)に対応していないと、プログラムでは認識ができません。
そして、プログラムで認識するタイミングも問題となります。
早すぎるとarticleタグは一つも認識できません。
よって、articleタグが出てくるまで待つ必要があります。
それを以下のコードで実現しています。
なお、コード全体は最後にまとめて載せています。
# articleタグが読み込まれるまで待機(最大15秒)
WebDriverWait(driver, 15).until(EC.visibility_of_element_located((By.TAG_NAME, 'article')))
このコードにより、articleタグが出てくるまで読み込み(処理)を待機するのです。
スゴイですね~
動的コンテンツをスクレイピングするのは、以下の2つが必要な要素となります。
- jsに対応している
- 読み込み完了のタイミングを細かく設定できる
Seleniumだと、これらに簡単に対応可能です。
スクロールによる追加コンテンツの読み込み
「スクロールにより追加コンテンツを表示している(改ページの概念がない)」に対応します。
Twitterをスクレイピングする上では、最大の難関です。
スクロール毎に何個かツイートを読み込んで表示しています。
ページにアクセスした時点では、5個のツイートが読み込まれています。
このとき、DOM上には、articleタグが5個存在しています。
そして、スクロールすると追加でツイートが何個か読み込まれます。
もっと正確に言いいます。
表示されているarticleタグの末尾付近までスクロールすると、新たに追加でツイートが読み込まれます。
なお、末尾までスクロールするとツイートが何個か飛ばされてしまいます。
ある程度の閾値があるはずですが、そこまでは把握できませんでした。
そのため、ツイートが歯抜けにならないように小細工が必要になります。
末尾ではなく、末尾から2個目を対象とします。
そうすれば、ツイートが歯抜けになることはありません。
これらの動きをまとめます。
- 末尾から2個目のarticleタグを認識する
- 末尾から2個目のarticleタグまでスクロールする
プログラム上で、上記が実現できないとダメなのです。
Seleniumなら、これが可能になります。
末尾から2個目のarticleタグを認識する
これは単純です。
# 最後の要素の一つ前までスクロール
elems_article = driver.find_elements_by_tag_name('article')
last_elem = elems_article[-2]
末尾から2個目のarticleタグまでスクロールする
コードだけなら、以下で済みます。
last_elemは上記で認識したモノです。
actions = ActionChains(driver);
actions.move_to_element(last_elem);
actions.perform();
なお、articleタグが出てくる仕組みは、単純な話ではありません。
スクロールしてarticleタグが増えれば、それまで存在していたaritcleはDOMから消えていきます。
スクロールする度、articleタグから情報を取得する必要があるのです。
スクロールをやり尽くした後に、まとめてarticleタグから情報を取得ということができません。
これを知ったとき、Twitterの本気を理解しました。
「本当にスクレイピングさせたくないのだなー」と。
IDやCLASS名で特定困難なタグ構成への対応
これは、Seleniumを使う必要がありません。
そのため、BeautifulSoupを使っています。
やはり、ここでもTwitterはスクレイピングをさせたくないようです。
基本的には、タグにはIDが指定されていません。
そして、CLASS名は「css-1dbjc4n」のように命名ルールがわからないモノです。
よって、CLASS名などで要素を特定することが、基本的には不可能です。
できるとしたら、何番目のaタグなどの指定になります。
例えば、ツイートの内容を取得するコードは以下のようになります。
まずは、role=groupのdivタグ(これが1つだけだったのでラッキー)の親要素を特定します。
その要素の(子供である)最初の要素のテキストを取得という流れになります。
# 投稿
base_elem = soup.find("div", role="group").parent
tweet = base_elem.find("div").text
だから、泥臭いコーディングになってしまいます。
もともとスクレイピングは泥臭い作業ですが、さらにドロドロという感じです。
完成したコード
完成したコードは以下です。
ここでは、一つ一つは説明しません。
わからない部分がある方は、紹介した過去記事を参考にしてください。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
import time
import pandas as pd
twitter_id = "seolabo85"
file_path = "./data/" + twitter_id + ".json"
scroll_count = 5
scroll_wait_time = 2
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
# tweet
def get_tweet(twitter_id):
url = 'https://twitter.com/' + twitter_id
id_list = []
tweet_list = []
# ヘッドレスモードでブラウザを起動
options = Options()
options.add_argument('--headless')
# ブラウザーを起動
driver = webdriver.Chrome("chromedriver.exeのパス", options=options)
driver.get(url)
# articleタグが読み込まれるまで待機(最大15秒)
WebDriverWait(driver, 15).until(EC.visibility_of_element_located((By.TAG_NAME, 'article')))
# 指定回数スクロール
for i in range(scroll_count):
id_list, tweet_list = get_article(url, id_list, tweet_list, driver)
# スクロール=ページ移動
scroll_to_elem(driver)
# ○秒間待つ(サイトに負荷を与えないと同時にコンテンツの読み込み待ち)
time.sleep(scroll_wait_time)
# ブラウザ停止
driver.quit()
return tweet_list
def scroll_to_elem(driver):
# 最後の要素の一つ前までスクロール
elems_article = driver.find_elements_by_tag_name('article')
last_elem = elems_article[-2]
actions = ActionChains(driver);
actions.move_to_element(last_elem);
actions.perform();
def get_info_of_article(data):
soup = BeautifulSoup(data, features='lxml')
elems_a = soup.find_all("a")
# 名前
name_str = elems_a[1].text
id = ''
name = ''
if name_str:
name_list = name_str.split('@')
name = name_list[0]
id = name_list[1]
# リンク
link = elems_a[2].get("href")
# 投稿日時
datetime = elems_a[2].find("time").get("datetime")
# 投稿
base_elem = soup.find("div", role="group").parent
tweet = base_elem.find("div").text
info = {}
info["user_id"] = id
info["user_name"] = name
info["link"] = link
info["datetime"] = datetime
info["tweet"] = tweet
return info
def get_article(url, id_list, tweet_list, driver):
elems_article = driver.find_elements_by_tag_name('article')
for elem_article in elems_article:
tag = elem_article.get_attribute('innerHTML')
elems_a = elem_article.find_elements_by_tag_name('a')
href_2 = elems_a[1].get_attribute("href")
href_tweet = ""
if href_2 == url:
# tweet
href_tweet = elems_a[2].get_attribute("href")
if href_tweet in id_list:
print("重複")
else:
# tweet情報取得
info = get_info_of_article(tag)
id_list.append(href_tweet)
tweet_list.append(info)
return id_list, tweet_list
if __name__ == '__main__':
# tweet情報をlist型で取得
tweet_list = get_tweet(twitter_id)
# データフレームに変換
df = pd.DataFrame(tweet_list)
# jsonとして保存
df.to_json(file_path, orient='records')
次の部分は、説明しておきます。
twitter_id = "seolabo85" file_path = "./data/" + twitter_id + ".json" scroll_count = 5 scroll_wait_time = 2
twitter_id
スクレイピング対象のアカウントの識別コードです。
https://twitter.com/seolabo85
上記アカウントであれば、「seolabo85」の部分です。
file_path
スクレイピングした内容をjsonファイルに保存します。
そのjsonファイルのパスの設定です。
scroll_count
スクロール回数です。
5が設定されていれば、追加で5回のコンテンツ読み込みが実施されます。
ちなみに1000回と指定した場合、819個のツイートが取得できました。
ただし、ツイートの長さ(画像ありなし)に依存するため、一概にこうだとは言えません。
scroll_wait_time
スクロールを何秒間隔で行うかという設定です。
これは、ページアクセスを何秒間隔で行うかと同じ意味です。
1秒以上開ければ、問題はないと考えています。
しかし、今回は2秒の設定にしています。
動的コンテンツがDOMに反映されることも加味すれば、2秒ぐらいが妥当です。
2秒だと、かなり優しいスクレイピングです。
2秒だと、人間が実際にブラウザで見るときより、遅い可能性すらあり得ます。
一気にスクロールをしますよね。
多分、それよりは優しいアクセスになっています。

