
「音声変換の学習に時間がかかり過ぎだ・・・」
「so-vits-svcよりも性能の音声変換技術を探している」
このような場合には、RVCがオススメです。
この記事では、RVCによる音声変換について解説しています。
本記事の内容
- RVCとは?
- RVC WebUIのインストール
- RVC WebUIの利用方法
それでは、上記に沿って解説していきます。
RVCとは?
RVCとは、Retrieval-based-Voice-Conversionの略称です。
現時点(2023年4月)では、このRVCが最新の音声合成技術と言えます。
つい最近まで、この分野ではso-vits-svcという技術が最新だったはずなんですけどね。
RVCは、so-vits-svcよりも性能が良い言われています。
RVCの性能については、次の音声で確認できます。
岸田首相の声を人気声優の声に変換しています。
なお、人気声優については「RVC WebUIの利用方法」のところでヒントを載せています。
興味がある方は、注意して見てみてください。
さらには、学習時間がso-vits-svcよりも圧倒的にも短くて済みます。
そして、学習に必要な音声ファイルも大量に必要とはしません。
岸田首相の例では、声優の音声データは40分ほどになります。
学習にかかった時間は、10分ほどです。
このRVCについては、ブラウザで動くツール(以降RVC WebUIと呼ぶ)が公開されています。
WebUIという表現は、最近良く見るようになりました。
よって、RVCはこのツールを使えば利用可能です。
以上、RVCについて説明しました。
次は、RVC WebUIのインストールについて説明します。
RVC WebUIのインストール
RVC WebUIは、次のページからダウンロードできます。

ファイルがたくさんあってややこしそうに見えます。
でも、Windowsの場合は「RVC-beta.7z」をダウンロードするだけです。
7z形式は、7-Zipで解凍できます。

解凍すると、次のように展開されます。
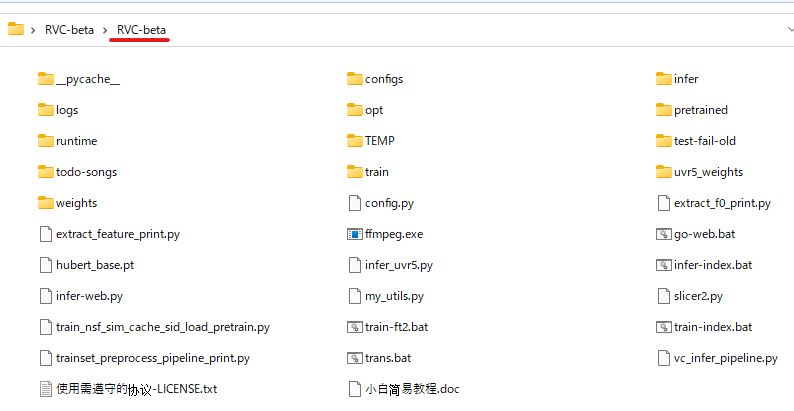
2つ目の「RVC-beta」ディレクトリが、RVC WebUIの本体になります。
これでRVC WebUIのインストールは完了と言えます。
以上、RVC WebUIのインストールを説明しました。
次は、RVC WebUIの利用方法を説明します。
RVC WebUIの利用方法
RVC WebUIの起動は、「RVC-beta」直下にある「go-web.bat」を実行します。
go-web.bat
runtime\python.exe infer-web.py
内容は、単純でPythonコードを実行しているだけです。
正常に起動すると、自動的にブラウザで「http://127.0.0.1:7865/」を開きます。
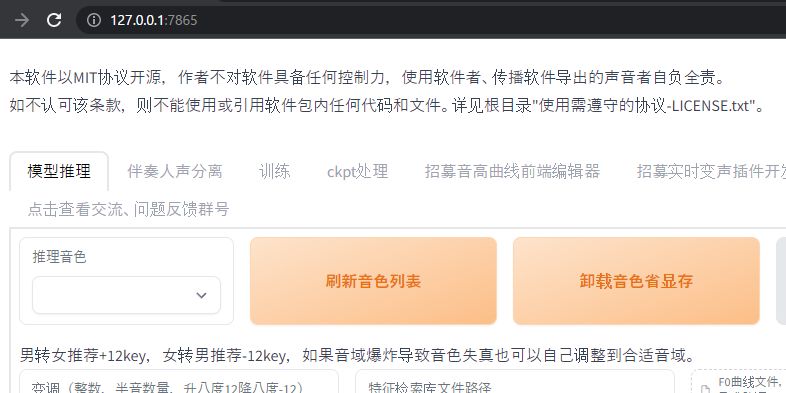
このような画面が確認できれば、OK。
見ればわかるように、中国語だらけです。
追記 2023年4月18日
次の記事では、日本語化された画面で学習データの集め方から解説しています。

そうは言っても、次の処理を行うだけなら問題はありません。
- 学習
- 推論(音声変換)
それぞれを下記で説明します。
その前に、学習させる音声を取得しておきましょう。
追記 2023年4月20日
学習するのが面倒・・・という方は、無料の学習済みモデルを利用しましょう。

とりあえず、wavファイルで10分ほどの音声であればなんとかなります。
もちろん、学習素材となる音声データが多いほどベターです。
そして、ファイル数は1個でも何個でも構いません。
ただし、品質を求めるなら無音を消し去る必要があります。
無音を除去したいなら、発話分割を行いましょう。
また、基本的には、対象者が一人で話している音声が学習素材として使えます。
音楽やエフェクトなどがあると、その分だけ精度は落ちます。
検証では、以下の場所にMP4の動画ファイルを保存しました。
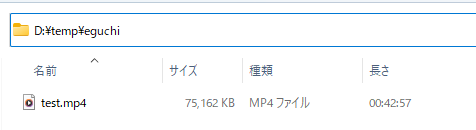
MP4でも、朗読やアカペラなら学習素材として利用可能です。
学習
「训练」タブを開きます。
日本語で言うと、学習・トレーニングとなります。
ここでは、最低限の入力項目を説明します。
- 输入实验名
- 输入训练文件夹路径
输入实验名
日本語で言うと、「実験名を入力」です。
学習させたい人物の名前を入力すると、推論での利用時にわかりやすくなります。
今回は、「eguchi」と入力します。
ここで入力した値のファイルを「推論」で選択することになります。
输入训练文件夹路径
「トレーニングフォルダーパスを入力」を意味します。
今回用意したのは、「D:\temp\eguchi」です。
そのため、次のように値を設定することになります。
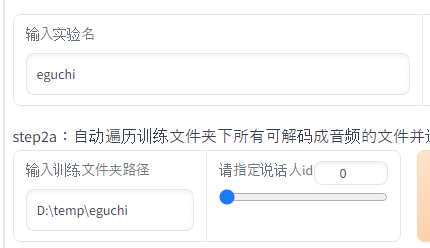
なお、ディレクトリ名と「输入实验名」が一致する必要はありません。
あくまで管理しやすいようにしているだけです。
これらの二つを設定できたら、画面最下部にある次のボタンをクリックします。
「ワンクリックトレーニング」という意味のボタンです。

処理は、ボタンの横にある「输出信息」(出力情報)で確認できます。
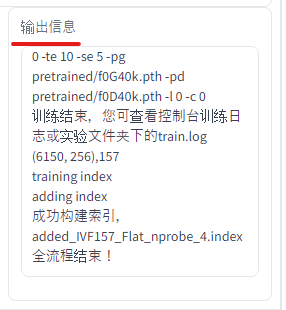
「全流程结束!」(全プロセス終了!)と出れば、処理は完了です。
それまでは気長に待ちましょう。
と言っても、それほどかかりません。 私の環境では、1分ちょっとです。(5分の素材なら1分程度)
40分の学習素材なら、10分程度です。
推論(音声変換)
「模型推理」タブを開きます。
ここでは、次の二つだけを設定します。
- 推理音色
- 输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)
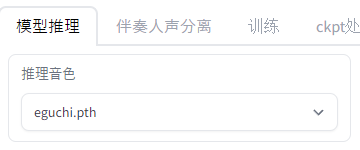
推理音色
推論に用いるファイルの選択です。
まずは、次のボタンをクリック。

日本語だと、「音色リストを更新する」という意味ですね。
これにより、先ほど学習した重みのファイルが選択可能となっています。
输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)
変換する対象の指定によって、利用するエリアが異なります。
- ファイル単位
- ディレクトリ単位
ここでは、ディレクトリ単位の方で説明します。
(※毎回ファイル名を変更するのが面倒なので)
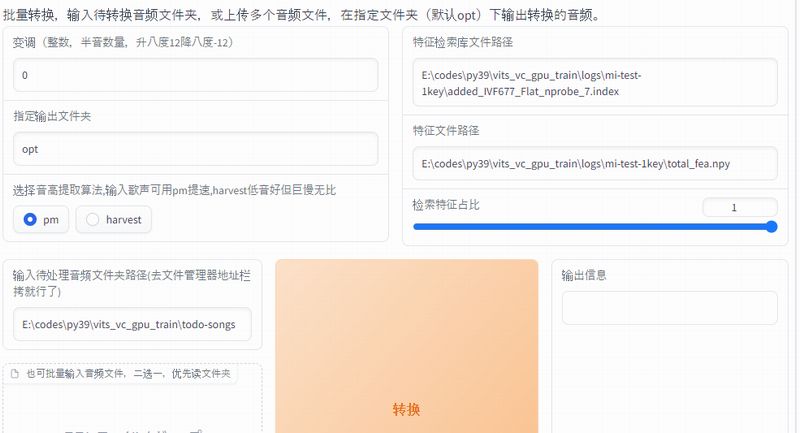
「输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)」は、次のように訳せます。
処理する音声フォルダのパスを入力する(ファイルマネージャのアドレスバーからコピーすればよい)
要するに、音声変換したいファイルの場所(ディレクトリ)を設定するということです。
デフォルトでは「E:\codes\py39\vits_vc_gpu_train\todo-songs」と設定されています。
「RVC-beta」の下に「todo-songs」というディレクトリがあります。
そして、さらにその下にはwavファイルが一つあります。
このファイルは、もともと用意されている音声ファイルです。
内容としては、アカペラですね。
この「todo-songs」ディレクトリのフルパスを入力しましょう。
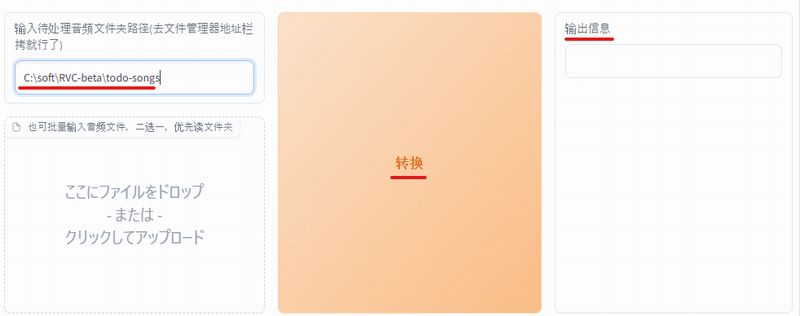
ここまで設定できれば、「转换」ボタンをクリック。
このボタンを押すと、音声を「変換」・「コンバージョン」します。
音声変換が完了したファイルから、「输出信息」に表示されます。
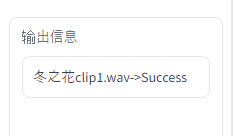
複数のファイルが存在していれば、ファイル数分だけ表示されることになります。
変換されたファイルは、「opt」ディレクトリの下で確認可能です。
なお、この「opt」は以下の項目で設定されています。
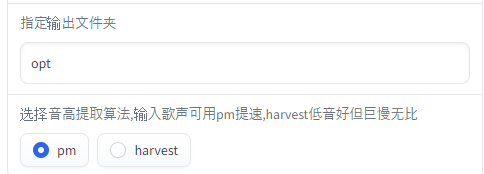
音声ファイルの変換精度を上げたい場合、「harvest」を選択しましょう。
「pm」の場合より、変換処理に時間がかかります。
また、学習データと変換データの性別が異なる場合があるかもしれません。
そのような場合は、次の項目の値を変更します。

推奨されている値は、以下。
- 男性から女性 +12
- 女性から男性 -12
要するに、キーを上げるか下げるかの話ですね。
以上、RVC WebUIの利用方法を説明しました。

