
「ジブリ風の画像を生成したい」
「ファインチューニングされたStable Diffusion用のモデルを利用したい」
このような場合には、Ghibli-Diffusionがオススメです。
この記事では、Stable DiffusionでGhibli-Diffusionを利用する方法を解説しています。
本記事の内容
- Ghibli-Diffusionとは?
- Ghibli-Diffusionの利用方法
- Ghibli-Diffusionの動作検証
それでは、上記に沿って解説していきます。
Ghibli-Diffusionとは?
Ghibli-Diffusionとは、スタジオジブリ風の画像が作成できるStable Diffusionのモデルになります。
映画の画像をもとにしてモデルを学習させているようです。
公式ページでは、次のような画像が公開されています。

見事にジブリ風です。
キャラクター以外にも自動車や動物の画像を生成できます。

普通にジブリ映画で出てきそうなリスですね。
Ghibli-Diffusionは、DreamBoothで学習されています。
DreamBoothについては、次の記事で説明しています。

DreamBoothを使えば、大量の画像を用いずにファインチューニングが可能です。
そのため、Ghibli-Diffusionにも大量の画像は用いられていないでしょう。
以上、Ghibli-Diffusionについて説明しました。
次は、Ghibli-Diffusionの利用方法を説明します。
Ghibli-Diffusionの利用方法
Stable Diffusionを動かせる環境が、必要です。
Google Colabではなくローカル環境で動かす場合は、次の記事が参考になります。

Stable Diffusionが動くなら、公式に載っているコードでGhibli-Diffusionを利用できます。
from diffusers import StableDiffusionPipeline
import torch
model_id = "nitrosocke/Ghibli-Diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "ghibli style, a girl"
image = pipe(prompt).images[0]
image.save("./test.png")
ポイントは、「ghibli style」をプロンプトに含むことです。
それ以外は、普通にStable Diffusionを利用するのと変わりません。
また、GPUに余裕があれば、「float16」を「float32」に変更してもよいでしょう。
初めてGhibli-Diffusionを利用する場合は、モデルのダウンロードが始まります。
そのファイル容量は、全部で5.1GBほどです。
上記コードを実行すると、test.pngが作成されます。
test.png

うん、ジブリ映画で出てきそうな「a girl」です。
以上、Ghibli-Diffusionの利用方法を説明しました。
次は、Ghibli-Diffusionの動作検証を説明します。
Ghibli-Diffusionの動作検証
Ghibli-Diffusionの動作検証を進めていきます。
その前に一つ確認ですが、次のような警告が出ていませんか?
これは、新しいDiffusersだと出る可能性があります。
少なくとも0.9.0.dev0ではこの警告がでています。
FutureWarning: The configuration file of the unet has set the default `sample_size` to smaller than 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the following: - CompVis/stable-diffusion-v1-4 - CompVis/stable-diffusion-v1-3 - CompVis/stable-diffusion-v1-2 - CompVis/stable-diffusion-v1-1 - runwayml/stable-diffusion-v1-5 - runwayml/stable-diffusion-inpainting you should change 'sample_size' to 64 in the configuration file. Please make sure to update the config accordingly as leaving `sample_size=32` in the config might lead to incorrect results in future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for the `unet/config.json` file

警告のメッセージ通りにファイルを修正すれば、警告は出なくなります。
場所は、キャッシュ以下で次のようなディレクトリを探しましょう。
.cache\huggingface\diffusers\models--nitrosocke--Ghibli-Diffusion\snapshots\バージョン\unet
このディレクトリには、次のファイルが配置されています。
config.jsonを変更します。
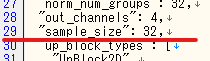
「32」を「64」に変更すれば、警告は出ないようになります。
では、Ghibli-Diffusionの動作検証を進めていきます。
まずは、「Totoro」です。
"ghibli style, Totoro"
このプロンプトで生成した画像は、以下。

どうも微妙な結果です。
そこで、ワード(トークン)の位置を入れ替えてみます。
"Totoro, ghibli style"
「Totoro」が先に来た場合の画像は、以下。

耳が増えたりしているトトロもいますが、総じていい結果です。
「castle」の場合は、「ghibli style」の位置は結果に影響しません。

ところで、天空の城ラピュタが出てくるかと思いきやそうではないのですね。
ただ、同じような城ばかり出るのが気になります。
ここまでの結果より、次の仮説が浮かびます。
- 一般名詞の場合は、「ghibli style」の位置は関係ない
- 固有名詞の場合は、「ghibli style」の位置が関係ある
最後に、キアヌ・リーヴスで検証してみましょう。
まずは、表現したい固定名詞の要素が薄いと想定されるケースです。
固有名詞の前に、「ghibli style」を設定します。
"ghibli style, Keanu Reeves"

キアヌ・リーヴスのファンなら、なんとかわかるレベルでしょうか。
次は、表現したい固定名詞の要素が強いと想定されるケースです。
固有名詞の後に、「ghibli style」を設定します。
"Keanu Reeves, ghibli style"

結果は、想定通りとなりました。
と言っても、Stable Diffusionにおけるプロンプトの仕様通りですけどね。
前のトークンほど、画像に強い影響を与えるというルールのことです。
以上、Ghibli-Diffusionの動作検証を説明しました。

