
「動画・音声の文字起こしを自動で行いたい」
「AIを使って、無料で精度の高い音声認識を試したい」
このような場合には、Whisperがオススメです。
この記事では、ほぼ完璧な文字起こしができるWhisperについて解説しています。
本記事の内容
- Whisperとは?
- Whisperのシステム要件
- Whisperのインストール
- Whisperの動作確認
それでは、上記に沿って解説していきます。
Whisperとは?
Whisperとは、汎用的な音声認識モデルになります。
Whisperは、OpenAIによって開発されています。
OpenAIと言えば、「DALL・E 2」や「GPT-3」の開発で有名ですね。
そこにWhisperも投入してきたという流れになります。
OpenAIによる、Whisperの紹介ページは以下。
Introducing Whisper
https://openai.com/blog/whisper/
このページでは、音声認識(文字起こし)のデモを確認できます。
ただ、日本語のデモはありません。
でも、安心してください。
Whisperは、日本語に対応しています。
以下のグラフは、言語毎のWhisperの性能(WER)を表しています。
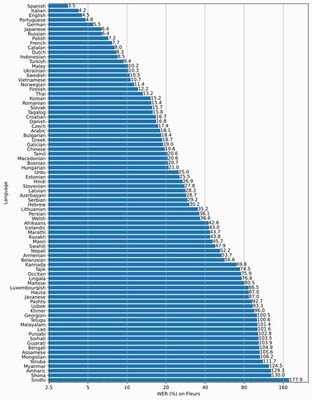
この中でも、日本語はかなり上位に位置付けられています。
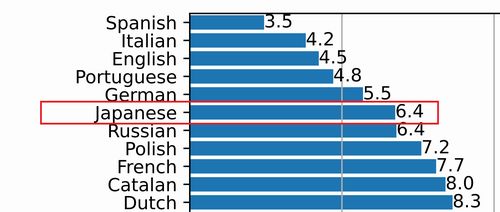
WERとは、Word Error Rateの略称になります。
そして、日本語の単語誤り率は6.4%ということです。
この場合、日本語の単語認識率は以下の計算式で求められます。
単語認識率 = 1.0 - 0.064 = 0.936
よって、日本語の単語認識率は約94%となります。
ある研究によると、次のような結果が公開されています。

話し言葉の音声認識の進展
https://www.code.ouj.ac.jp/media/pdf/vol9no1_shotai_1.pdf
この結果によると、94%は「ほぼ完璧」と言ってよいでしょう。
議会の会議録作成であれば、十分に利用可能になります。
このようなレベルの音声認識が、Whisperでは実現されているということです。
以上、Whisperについて説明しました。
次は、Whisperのシステム要件を説明します。
Whisperのシステム要件
現時点(2022年9月)でのWhisperの最新バージョンは、1.0となります。
GitHubを見ると、2022年9月22日に公開されています。
今後、さらなる改良が実施されるのを期待しましょう。
と言っても、現時点でも普通に動きます。
このWhisperのシステム要件は、以下がポイントになります。
- OS
- Pythonバージョン
- PyTorch
- FFmpeg
それぞれを以下で説明します。
OS
サポートOSに関しては、以下を含むクロスプラットフォーム対応になります。
- Windows
- macOS
- Linux
基本的には、OSは問わないということです。
Pythonバージョン
サポート対象となるPythonのバージョンは、Python 3.7以降と考えてよいでしょう。
一応、setup.pyを見る限りPython 3.7以降が必須というわけではありません。
ただ、Pyton 3.7以降が望ましいと公式には記載されています。
それに、以下のPython公式開発サイクルを意識するべきです。
| バージョン | リリース日 | サポート期限 |
| 3.6 | 2016年12月23日 | 2021年12月23日 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
Python公式開発サイクルを意識するなら、Python 3.7以降の利用が望ましいと言えます。
PyTorch
PyTorchに関しても、特にバージョンは明記されていません。
ただ、モデルの学習にはPyTorch 1.10.1を利用したことが記載されています。
そうは言っても、PyTorchはなるべく最新を利用すべきです。
パフォーマンスは、やはり最新バージョンの方が勝っているでしょう。
あと、WhisperはGPU版PyTorchの利用が前提となっています。
そのため、GPU版PyTorchをインストールします。
GPU版PyTorchについては、次の記事で解説しています。

FFmpeg
Whisperでは、動画・音声ファイルの処理にはFFmpegが利用されています。
具体的には、ffmpegコマンドをプログラム上でコールしているようです。
そのため、システム要件としてFFmpegのインストールが必須となります。
FFmpegのインストールは、以下の記事で説明しています。




以上、Whisperのシステム要件を説明しました。
次は、Whisperのインストールを説明します。
Whisperのインストール
Whisperのインストールを行っていきます。
システム要件であるPyTorchとFFmpegはインストール済みとします。
その状態において、次のコマンドを実行します。
pip install git+https://github.com/openai/whisper.git
このコマンドにより、次のファイル内のパッケージがインストールされます。
requirements.txt
numpy torch tqdm more_itertools transformers>=4.19.0 ffmpeg-python==0.2.0
処理完了後、インストール済みパッケージの状況を確認します。
> pip list Package Version ------------------ ------------ certifi 2022.9.14 charset-normalizer 2.1.1 requests 2.28.1 setuptools 65.3.0 tokenizers 0.12.1 torch 1.12.1+cu113 torchaudio 0.12.1+cu113 torchvision 0.13.1+cu113 tqdm 4.64.1 transformers 4.22.1 typing_extensions 4.3.0 urllib3 1.26.12 wheel 0.37.1 whisper 1.0
それほど多くのパッケージが、インストールされるわけではありません。
ただ、Python仮想環境を利用することを推奨します。

以上、Whisperのインストールを説明しました。
次は、Whisperの動作確認を説明します。
Whisperの動作確認
Whisperには、次の2つの利用方法があります。
- コマンドラインツール
- Python API(モジュール)
それぞれを下記で説明します。
ただし、その前に音声(もしくは動画)ファイルを用意しましょう。
YouTubeから動画をダウンロードするという手段があります。

小さな容量のMP3を用意したければ、gTTSを利用するという方法もあります。
これは、テキストから音声ファイルを生成する方法です。

今回は、このgTTSで作成した音声ファイルを用います。
この音声ファイルは、次のテキストをもとに生成しています。
過去最強クラスの台風14号が近づいてきています。九州南部、そして北部の皆さんを中心に暴風、高波、高潮や大雨などに最大級の警戒をしてください。
コマンドラインツール
公式では、次のコマンドが紹介されています。
whisper japanese.wav --language Japanese
ファイル名をtest.mp3に変更して実行した結果は、以下。
なお、初回時はモデル(未指定時はsmall)のダウンロードに時間がかかってしまいます。
> whisper test.mp3 --language Japanese [00:00.000 --> 00:05.700] 過去最強クラスの台風14号が近づいてきています。 [00:05.700 --> 00:27.180] 9周南部、そして北部の皆さんを中心に防風、高波、高潮や大雨などに最大級の警戒をしてください。
結果は、「9周」以外はパーフェクトです。
次は、モデルを「medium」に指定してみましょう。
モデルのダウンロードに時間がかかかるのは、同様です。
モデルのファイルサイズは、1.42GBになります。
> whisper test.mp3 --language Japanese --model medium [00:00.000 --> 00:10.800] 過去最強クラスの台風14号が近づいてきています 九州南部そして北部の皆さんを中心に暴風 [00:10.800 --> 00:32.240] 高波高潮や大雨などに最大級の警戒をしてください
先ほどより、結果が改善されました。
なお、モデルに関しては次のような記載が公式にあります。
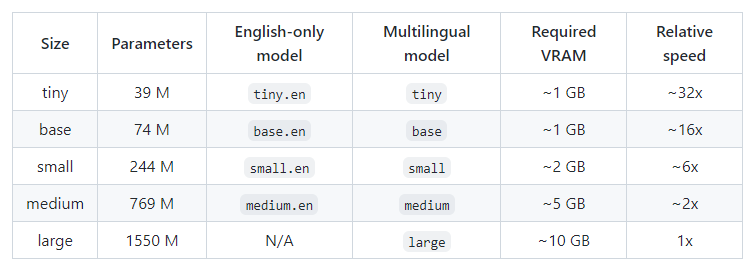
検証マシンのGPUは、メモリが8GBです。
「large」を試してみましたが、やはり8GBではダメでした。
次のエラーが出てしまいます。
RuntimeError: CUDA out of memory.
Python API(モジュール)
動作確認用コードは、以下となります。
import whisper
model = whisper.load_model("base")
result = model.transcribe("test.mp3")
print(result["text"])
上記を実行した結果は、以下。
Detected language: japanese 過去最強クラスの台風14号が近づいてきています。九州南部、そして北部の皆さんを中心に防風、高波、高市屋や大雨などに最大級の警戒をしてください。
上記結果は、モデルに「base」を指定しています。
モデルを変更した結果は、以下となります。
「small」を指定した場合の結果
Detected language: japanese 過去最強クラスの台風14号が近づいてきています。9周南部、そして北部の皆さんを中心に防風、高波、高潮や大雨などに最大級の警戒をしてください。
「medium」を指定した場合の結果
Detected language: japanese 過去最強クラスの台風14号が近づいてきています。九州南部、そして北部の皆さんを中心に暴風、高波、高潮や大雨などに最大級の警戒をしてください。
まとめ
検証結果を見ると、Python API(モジュール)の「medium」が最強です。
完全に一致しています。
もちろん、用意した音声ファイルが認識しやすいということはあるでしょう。
それでも、無料でこのレベルの音声認識は素晴らしいの一言です。
以上、Whisperの動作確認を説明しました。

