
スクレイピングをしていく上で、アクセス拒否・制限は避けられない問題です。
厳しいところなんて、1秒間隔でのアクセスでもアウトにします。
これは、かなり厳しい例ですけどね。
このアクセス拒否・制限で一番困るのは、開発段階です。
開発段階でアクセス制限を受けた場合、その日は開発作業が進みません。
24時間のペナルティを課すサイトもありますので。
なお、運用段階であれば、大体の規則性を掴んでいるはずです。
規則性とは、アクセス拒否・制限を受ける基準になります。
本記事では、このアクセス拒否・制限をクリアする方法を解説しています。
本記事の内容
- プロキシ経由でサイトへアクセスするメリット
- 【サンプルコード】Pythonでプロキシ経由のアクセス・スクレイピングを行う
- 【サンプルコード】複数のプロキシをランダムに利用する
- 【おまけ】自分専用のプロキシを持つ
それでは、上記に沿って説明を行っていきます。
プロキシ経由でサイトへアクセスするメリット

上記の記事で詳細をまとめています。
PHPと書いていますが、メリットに関する部分は言語依存ではありません。
参考にご覧ください。
【サンプルコードあり】Pythonでプロキシ経由のアクセス・スクレイピングを行う
まずは、コードから。
2020年08月09日時点では元気に動いています。
import requests
from bs4 import BeautifulSoup
URL = "https://www.cman.jp/network/support/go_access.cgi"
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"
proxies = {
'http':'https://140.227.237.154:1000',
'https':'https://140.227.237.154:1000'
}
# User-Agentの設定
headers = {"User-Agent": USER_AGENT}
resp = requests.get(URL, proxies=proxies, headers=headers, timeout=10)
resp.encoding = 'utf8'
soup = BeautifulSoup(resp.text, "html.parser")
# IP表示部分の取得
ip = soup.find(class_="outIp").text
print(ip)
実行してみて、「140.227.237.154」と表示されれば成功です。
IPアドレス140.227.237.154のプロキシ経由でサイトにアクセスできています。
アクセス先は以下です。
https://www.cman.jp/network/support/go_access.cgi
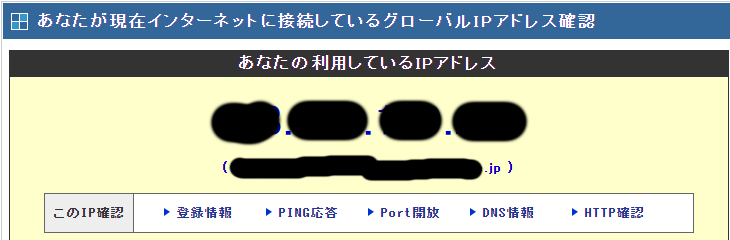
アクセスすると、上のようにアクセス元のIPアドレスが表示されます。
サンプルコードでは、このIPアドレスの部分をスクレイピングしています。
proxies = {
'http':'https://140.227.237.154:1000',
'https':'https://140.227.237.154:1000'
}
このプロキシで設定しているIPアドレスがスクレイピングできれば、すべてOKということです。
すべてとは、以下のことです。
- プロキシ経由で対象サイトにアクセスする
- プロキシ経由で対象サイトをスクレイピングする
一石二鳥のサンプルコードです。
もし、動かないならプロキシサーバーを変更してください。
Myプロキシサーバーがあれば、それを使ってみてください。
Myプロキシサーバーがない場合は、以下から適当に選んでください。
http://proxy.moo.jp/ja/?c=&pt=&pr=&a%5B%5D=0&a%5B%5D=1&a%5B%5D=2&u=60
稼働率60%以上で抽出しています。
以上より、Pythonでプロキシ経由によりスクレイピングが簡単だとわかりました。
すぐにでも対応できるはずです。
ただ、プロキシサーバーが一つだと心もとないケースもあります。
その一つのプロキシがアクセス拒否・制限されるというリスクですね。
そこで、複数のプロキシサーバーを利用する手段を考える必要があります。
それについては、以下で解説しています。
【サンプルコードあり】複数のプロキシをランダムに利用する
複数のプロキシをランダムに利用すれば、もうアクセス拒否・制限とはサヨナラです。
これなら、スクレイピングされる側は対応のやりようがありません。
さきほどのコードを改良しています。
import requests
import json
import random
from bs4 import BeautifulSoup
FILE_PATH = "ip_list.json"
URL = "https://www.cman.jp/network/support/go_access.cgi"
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36"
# jsonからproxyの情報取得
json_open = open(FILE_PATH, 'r')
proxy_list = json.load(json_open)
# ランダムに一つ選択
proxy_info =random.choice(proxy_list)
# proxy情報作成
ip = proxy_info["ip"]
port = proxy_info["port"]
protocol = proxy_info["protocol"]
proxy = protocol + "://" + str(ip) + ":" + port
proxies = {
'http':proxy,
'https':proxy
}
# User-Agentの設定
headers = {"User-Agent": USER_AGENT}
resp = requests.get(URL, proxies=proxies, headers=headers, timeout=10)
resp.encoding = 'utf8'
soup = BeautifulSoup(resp.text, "html.parser")
# IP表示部分の取得
ip = soup.find(class_="outIp").text
print(ip)
改良ポイントは、プロキシの自動設定です。
プロキシの情報は、jsonとしてファイルに保存しています。
FILE_PATH = "ip_list.json"
ip_list.jsonの内容は以下。
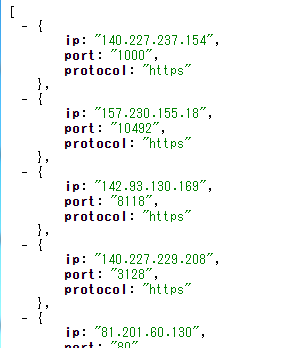
この中から、ランダムに一つ選択しています。
あとは、上記で説明した仕様になります。
なお、ip_list.jsonは、上記で紹介したプロキシサーバー一覧をスクレイピングして作成しました。
とりあえず、ip_list.jsonを公開しておきます。
ダウンロードして使っても構いません。
ただ、このip_list.jsonはあくまで検証用として使ってください。
これをもとに運用するのは、危険すぎます。
所詮は無料のプロキシです。
いつ止まっても文句は言えません。
それに、世界中から利用されているので負荷が尋常ではないでしょう。
そして、遅延もしばしば生じます。
そのため、サンプルコードではタイムアウトを10秒にしています。
これを設定しないと永遠と待たされることになりかねません。
そのため、私はMyプロキシをおススメします。
私もMyプロキシを所有しています。
自分専用のプロキシに関しては、以下で説明します。
【おまけ】自分専用のプロキシを持つ
自分専用のプロキシであれば、サーバー停止や遅延を気にする必要もありません。
なお、プロキシだけの用途だけではなく、普通にサーバーとしても利用できます。
今は、サーバーも本当に安く借りれます。
私は以下でプロキシを構築しています。
月額300円ちょっとです。

ただし、格安のため、ほぼ自分でやる必要があります。
Linuxの素人では、厳しいかもしれません。
でも、こういうのをキッカケにLinuxについて学ぶのもアリだと思います。
OSの初期設定に関しては、以下の記事が参考になります。
初心者でも頑張れば、なんとかなるようにはまとめています。

プロキシサーバーを構築する作業に関しては、以下です。


