「無料でGPT-3に匹敵する自然言語処理モデルを利用したい」
「Googleが公開している自然言語処理モデルを試したい」
このような場合には、Flan-T5がオススメです。
この記事では、Flan-T5について解説しています。
本記事の内容
- Flan-T5とは?
- Flan-T5のシステム要件
- Flan-T5の動作確認
それでは、上記に沿って解説していきます。
Flan-T5とは?
Flan-T5を知るには、FLANとT5について知っておく必要があります。
FLANとは、FinetunedLAnguage Netの略称です。
FLANを取り入れることで、ゼロショット学習の効果が向上します。
ゼロショット学習により、未知のことに対応できやすくなります。
つまり、FLANによってモデルの精度が上がるということです。
T5とは、Googleが発表した自然言語処理モデルになります。
Googleは、T5以外にも以下の自然言語処理モデルを発表しています。
- BERT
- PaLM
ここまで来れば、Flan-T5のことがわかってきたと思います。
Flan-T5は、T5を改良した自然言語処理モデルということです。
そして、このFlan-T5が一部の処理ではGPT-3よりも優れていると言われています。
本当にAIの世界は進化が速くて、追いかけるのが大変です。
Flan-T5には、以下のモデルが存在しています。
- Flan-T5 small
- Flan-T5 base
- Flan-T5 large
- Flan-T5 XL
- Flan-T5 XXL
これらを含めたFlan系モデルの評価値は、以下となります。
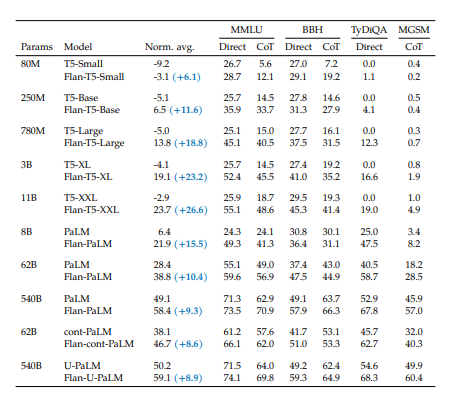
評価項目が複数ありますが、それらはすべて数値が高ければ精度は良いと言えます。
残念ながら、精度の高いPaLMは一つも公開してくれないようです。
以上、Flan-T5について説明しました。
次は、Flan-T5のシステム要件を説明します。
Flan-T5のシステム要件
Flan-T5は、PyTorchで動く言語モデルです。
そのため、PyTorchが必須となります。
そのPyTorchを中心にして、インストールすべきモノが以下。
- PyTorch
- Transformers
- SentencePiece
- Accelerate
これらを以下で説明します。
PyTorch
PyTorchは、CPU・GPUの両方で動きます。
しかし、Flan-T5を利用する処理はかなりの計算量が必要になります。
試していませんが、CPUではまともには動かないでしょう。
よって、基本的にはGPU版のPyTorchを利用しましょう。

Transformers
自然言語処理を行うなら、Transformersは必須です。
Transformersについては、次の記事で解説しています。

SentencePiece
LSTM (RNN)による文章生成において、SentencePieceが利用されています。
SentencePieceについては、次の記事で説明しています。

Accelerate
GPU版PyTorchでFlan-T5を利用する際に、必要となっています。
ここでは、高速に処理を実行するために必要なライブラリだという程度の認識でOKです。
詳細は、次の記事で解説しています。

インストールは、pipコマンドで簡単に行えます。
pip install accelerate
まとめ
システム要件を満たすために利用したコマンドは、以下。
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117 pip install transformers pip install sentencepiece pip install accelerate
PyTorchに関しては、利用しているCUDAやOSによってインストールコマンドは異なります。
各自の環境に合わせたコマンドを利用してください。
以上、Flan-T5のシステム要件を説明しました。
次は、Flan-T5の動作確認を説明します。
Flan-T5の動作確認
今回は、利用できる上位2つのモデルを利用してみましょう。
- Flan-T5 XL
- Flan-T5 XXL
動作確認は、次のコードを用います。
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("指定モデル")
model = T5ForConditionalGeneration.from_pretrained("指定モデル", device_map="auto")
input_text = "What is the highest mountain in Japan?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids, max_length=200, bos_token_id=0)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
「指定モデル」には、次の値を設定します。
| モデル | 指定モデル | サイズ |
| Flan-T5 XL | google/flan-t5-xl | 10.6GB |
| Flan-T5 XXL | google/flan-t5-xxl | 41.9GB |
初めてモデルを利用する場合は、モデルのダウンロードが実施されます。
そのときにダウンロードされるモデルのサイズには、十分注意しましょう。
Flan-T5 XXLは、41.9GBもディスクを消費します。
もちろん、そのサイズをダウンロードするのにも時間はかかります。
また、GPUのメモリサイズで実行できないこともありえます。
検証に用いたマシンで「nvidia-smi」を実行した結果は、以下。
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 512.77 Driver Version: 512.77 CUDA Version: 11.6 | |-------------------------------+----------------------+----------------------+ | GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA GeForce ... WDDM | 00000000:01:00.0 On | N/A | | 0% 40C P8 25W / 350W | 599MiB / 24576MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+
GPUのメモリサイズが不安な場合は、モデルの変更を試してください。
動作確認に話を戻しましょう。
それぞれのモデルを指定してコードを実行した結果は、次のようになりました。
なお、質問には「What is the highest mountain in Japan?」を設定しています。
Flan-T5 XL(12.76833462715149秒)
mount fuji
Flan-T5 XXL(49.02419376373291秒)
mount fuji
質問がシンプルであるために、回答は一致しましたね。
そもそも、Flan-T5 XLとFlan-T5 XXLではそんなに大きな差がありません。

しかし、処理時間は37秒の差があります。
それであれば、Flan-T5 XLを利用した方が良いかもしれません。
モデルのサイズも4分の1で済みます。
ただ、Flan-T5 XLでも12秒かかっています。
もう少し速ければ嬉しいのですけどもね・・・
以上、Flan-T5の動作確認を説明しました。

