
「AIで簡単に動画を作成したい」
「Stable Diffusionで動画を作成するのは難しそう・・・」
このような場合には、この記事の内容が参考になります。
この記事では、Stable Diffusionで簡単に動画を作成する方法を解説しています。
本記事の内容
- Stable Diffusionによる動画作成
- Diffusersによる連番画像の作成
- Stable Diffusionによる動画作成の実例
それでは、上記に沿って解説していきます。
Stable Diffusionによる動画作成
Stable Diffusionで動画を作成するのは、難しい印象がありませんか?
Stable Diffusionが出た当初は、実際に大変な作業ではありました。
しかし、今では動画も簡単に作成できるようになっています。
ただ、Stable Diffusionはあくまで画像生成AIです。
そのため、画像を連番で作成することしかできません。
それらの連番画像から動画を作成するのは、別のツールを利用します。
無料かつ簡単なツールとしては、FFmpegが存在しています。


画像から動画を作成するのは、FFmpegに任せましょう。
Stable Diffusionは、動画作成に必要な画像を作成するために利用します。
そのための仕組みも何個か公開されています。
この記事では、Diffusersを用いた連番画像の作成を取り上げます。
以上、Stable Diffusionによる動画作成を説明しました。
次は、Diffusersによる連番画像の作成を説明します。
Diffusersによる連番画像の作成
Stable Diffusionを動かせる環境が、必要です。
Google Colabではなくローカル環境で動かす場合は、次の記事が参考になります。

上記記事通りに従えば、必然的にDiffusersをインストールすることになります。

Diffusersのバージョンについては、その時点での最新をインストールしましょう。
ここまで準備ができたら、あとは次のコードを実行するだけです。
from diffusers import DiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
base_dir = "./imgs"
pipe = DiffusionPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16,
safety_checker=None, # Very important for videos...lots of false positives while interpolating
custom_pipeline="interpolate_stable_diffusion",
).to("cuda")
pipe.enable_attention_slicing()
frame_filepaths = pipe.walk(
prompts=["a dog", "a cat", "a horse"],
seeds=[42, 1337, 1234],
num_interpolation_steps=16,
output_dir=base_dir,
batch_size=4,
height=512,
width=512,
guidance_scale=8.5,
num_inference_steps=50,
)
ただし、実行する前に注意点があります。
- GPUメモリが8GB以上
- 利用できるモデルに制限がある
GPUメモリが8GB以上は、大丈夫でしょう。
大抵のGPUではクリアしているはずです。
利用できるモデルは、Stable Diffusion 1.5以下だと考えておきましょう。

Stable Diffusion v2以降では、エラーが出てしまいます。

おそらく、Stable Diffusion 1.5(1.4)をベースにしたモデルなら大丈夫でしょう。
これらをベースにDreamBoothなどでファインチューニングしたモデルのことを指しています。
では、コードを実行してみましょう。
公式のマニュアルでは、5分ほどかかると記載されています。
もちろん、マシンスペックによって処理時間は変わってくるでしょう。
処理が完了すると、指定したディレクトリ(./imgs)以下にディレクトリが作成されています。
ディレクトリ名は、処理日時で構成されています。
そして、そのディレクトリの下には多くの画像を確認できます。
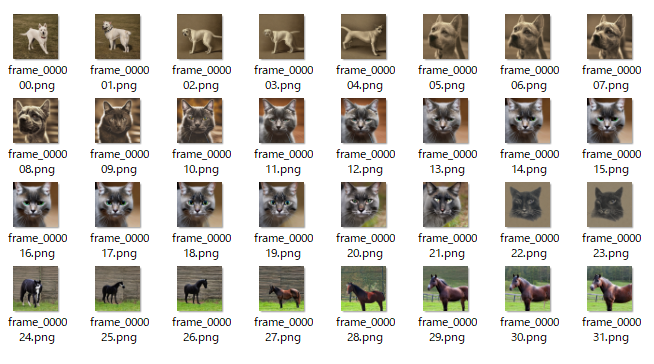
画像枚数は、以下の値によって変わってきます。
- プロンプト数
- num_interpolation_steps
- batch_size
ちなみに、私の環境では約1分半で処理が終わっています。
100%|██████████| 51/51 [00:12<00:00, 4.21it/s] 100%|██████████| 51/51 [00:11<00:00, 4.58it/s] 100%|██████████| 51/51 [00:11<00:00, 4.50it/s] 100%|██████████| 51/51 [00:11<00:00, 4.52it/s] 100%|██████████| 51/51 [00:11<00:00, 4.55it/s] 100%|██████████| 51/51 [00:11<00:00, 4.55it/s] 100%|██████████| 51/51 [00:11<00:00, 4.54it/s] 100%|██████████| 51/51 [00:11<00:00, 4.54it/s]
また、 利用しているGPUはNVIDIA GeForce RTX 3090となります。
> python -m xformers.info WARNING:root:A matching Triton is not available, some optimizations will not be enabled. Error caught was: No module named 'triton' xFormers 0.0.14.dev memory_efficient_attention.flshatt: available - requires GPU with compute capability 7.5+ memory_efficient_attention.cutlass: available memory_efficient_attention.small_k: available is_triton_available: False is_functorch_available: False pytorch.version: 1.13.0+cu116 pytorch.cuda: available gpu.compute_capability: 8.6 gpu.name: NVIDIA GeForce RTX 3090
その上で、xFormersによりPyTorchの高速化を実施済みです。

以上、Diffusersによる連番画像の作成を説明しました。
最後に、Stable Diffusionによる動画作成の実例を説明します。
Stable Diffusionによる動画作成の実例
モデルは、Analog Diffusionを利用します。

また、コードを管理しやすいように変更しています。
from diffusers import DiffusionPipeline
import torch
model_id = "wavymulder/Analog-Diffusion"
base_dir = "./imgs"
prompt_list = [
"analog style, a mouse",
"analog style, a cat",
"analog style, a cheetah",
]
seed_list = [
1112,
1112,
1112,
]
pipe = DiffusionPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16,
safety_checker=None, # Very important for videos...lots of false positives while interpolating
custom_pipeline="interpolate_stable_diffusion",
).to("cuda")
frame_filepaths = pipe.walk(
prompts=prompt_list,
seeds=seed_list,
num_interpolation_steps=64,
output_dir=base_dir,
batch_size=8,
height=512,
width=512,
guidance_scale=8.5,
num_inference_steps=50,
)
batch_sizeとnum_interpolation_stepsを倍にしています。
これにより、より滑らかな動画になるはずです。
もちろん、その分だけ処理時間はかかります。
処理にかかった時間は、約5分20秒です。
100%|██████████| 51/51 [00:21<00:00, 2.33it/s] 100%|██████████| 51/51 [00:20<00:00, 2.47it/s] 100%|██████████| 51/51 [00:20<00:00, 2.45it/s] 100%|██████████| 51/51 [00:20<00:00, 2.45it/s] 100%|██████████| 51/51 [00:20<00:00, 2.45it/s] 100%|██████████| 51/51 [00:20<00:00, 2.44it/s] 100%|██████████| 51/51 [00:20<00:00, 2.43it/s] 100%|██████████| 51/51 [00:20<00:00, 2.43it/s] 100%|██████████| 51/51 [00:20<00:00, 2.43it/s] 100%|██████████| 51/51 [00:21<00:00, 2.43it/s] 100%|██████████| 51/51 [00:21<00:00, 2.43it/s] 100%|██████████| 51/51 [00:20<00:00, 2.44it/s] 100%|██████████| 51/51 [00:21<00:00, 2.43it/s] 100%|██████████| 51/51 [00:20<00:00, 2.44it/s] 100%|██████████| 51/51 [00:20<00:00, 2.44it/s] 100%|██████████| 51/51 [00:20<00:00, 2.45it/s]
また、今回の処理ではseedを統一しています。
seedを統一した方が、背景が一致しやすくなります。
結果として、画像は128枚です。

では、これらの連番画像を用いて動画を作成します。
動画作成には、すでに紹介したFFmpegを利用します。
実行するコマンドは、以下。
ffmpeg -framerate 8 -i frame_%06d.png -vcodec libx264 -pix_fmt yuv420p out.mp4
上記のコマンドについては、次の記事で説明しています。

フレームレートは、コマ撮りアニメーションとして成立する8FPSを設定済みです。
8FPSであれば、かなりそれっぽく見えますね。
以上、Stable Diffusionによる動画作成の実例を説明しました。

