
「DreamBoothの本当の実力はどうなの?」
「DreamBoothの実践的な利用方法を知りたい」
このような場合には、この記事の内容が参考になります。
この記事では、DreamBoothの実践的な利用方法を解説しています。
本記事の内容
- DreamBooth利用における参考情報
- DreamBoothにおける学習画像の収集
- DreamBoothにおける学習の実行
- 学習済みモデルの利用(推論)
それでは、上記に沿って解説していきます。
DreamBooth利用における参考情報
DreamBoothについては、次の記事で説明しています。

ただし、実際にDreamBoothを利用する際は次の記事を参考にしてください。

こちらの記事の方法の方が、断然簡単にDreamBoothを利用できます。
それに、Stable Diffusion 2.0に対応しています。
とりあえず、DreamBoothが動くまでは確認できたでしょうか?
環境が構築できても、DreamBoothは漠然と意味不明な部分があります。
そんな場合には、次のページが参考になります。
トレーニングガイドをNitrosocke氏が記載してくれています。
GitHub – nitrosocke/dreambooth-training-guide
https://github.com/nitrosocke/dreambooth-training-guide
Nitrosocke氏が公開したモデルは、次のページで確認できます。
https://huggingface.co/nitrosocke
TOP3を見てみると、3万回近くダウンロードされています。
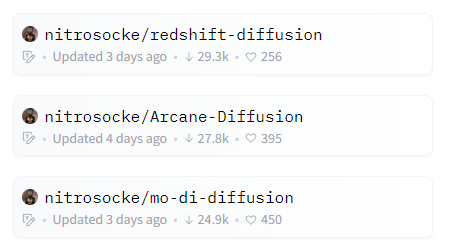
モデル生成の実績では、Nitrosocke氏がおそらくNo.1ではないでしょうか。
ベースとしては、上記のトレーニングガイドを参考します。
それに加えて、次のページも参考になります。
I was wrong – classifier/regularization images DO matter. New advice + examples
https://www.reddit.com/r/StableDiffusion/comments/z9g46h/i_was_wrong_classifierregularization_images_do/
このページでは、クラス分類・正則化画像についての説明が行われています。
イマイチ、これらの存在が不明なところがあります。
これらを利用しなくても、学習が実行されているケースもあります。
実際にそのような説明記事が、ググれば出てきます。
ここは、非常に混乱し易いポイントです。
実際、上記のRedditにおけるスレッドの投稿主もそのように主張していました。
しかし、それは間違いだったと訂正しています。
多くの検証結果をもとに必要説を説明しています。
以上、DreamBooth利用における参考情報を説明しました。
次は、DreamBoothにおける学習画像の収集を説明します。
DreamBoothにおける学習画像の収集
今回の学習では、11枚の画像を用意しました。
漫☆画太郎氏が芸能人を描いた画像を利用しています。
作品からは1枚も取得していないと言えます。
おそらく、著作権はどこにも属していないはずです。
仮にあったとしても、AIに学習させる場合には問題はありません。
著作物を機械学習に利用することは著作権法で認められています。
しかし、法律は権利者の利益を害することまでは許容しません。
あくまで、権利者に損害を与えない程度での利用ということですね。
次のようなバランスをイメージしておけば、暴走はしないと思います。
著作権者の利益 VS 社会の利益(公共の福祉)
とにかく、たった11枚の顔画像だけを収集しました。
すべて、512 x 512のサイズにしています。
その際、次のツールを利用しています。

自動的に512 x 512のサイズで顔だけを切り取ってくれます。
以上、DreamBoothにおける学習画像の収集を説明しました。
次は、DreamBoothにおける学習の実行を説明します。
DreamBoothにおける学習の実行
利用したコマンドは、以下。
accelerate launch train_dreambooth.py ` --class_data_dir=./regularization_images/person ` --pretrained_model_name_or_path="stabilityai/stable-diffusion-2-base" ` --instance_data_dir=./training_images ` --output_dir=./model ` --instance_prompt "man_ga_taro person" ` --class_prompt "person" ` --resolution=512 ` --train_batch_size=1 ` --gradient_accumulation_steps=1 ` --learning_rate=1e-6 ` --lr_scheduler constant ` --lr_warmup_steps=0 ` --max_train_steps=4000 ` --with_prior_preservation --prior_loss_weight=1.0 ` --gradient_checkpointing
基本的には、Nitrosocke氏の推奨する値を設定しています。

「class_prompt」には、正則化画像のカテゴリー名を設定します。
以下は、Nitrosocke氏が公開してくれている正則化画像の一覧です。
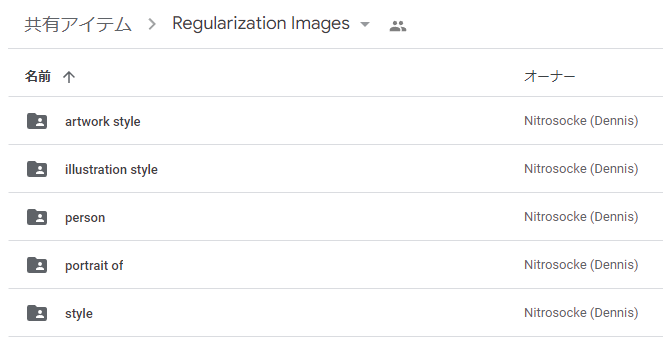
このディレクトリ名が、「class_prompt」に設定されています。
したがって、「person」を利用しているので次のように設定しています。
--instance_prompt "man_ga_taro person" ` --class_prompt "person" `
また、「instance_prompt」には独自の造語を設定する必要があります。
今回であれば、「man_ga_taro」だけでも十分だったでしょう。
しかし、念のために「man_ga_taro person」という複合ワードの組み合わせを設定しています。
上記のコマンドを実行した結果、40分程度の時間がかかっています。
条件を整理すると、以下。
| 学習画像 | 11枚 |
| 正則化画像 | 1000枚 |
| max_train_steps | 4000回 |
なお、GPUはNVIDIA GeForce RTX 3090を利用しています。
NVIDIA GeForce RTX 4090を利用したら、どれほど速くなるのでしょうかね?
すでにRTX 4090搭載のマシンが販売されています。
でも、まだ高いですね・・・
以上、DreamBoothにおける学習の実行を説明しました。
最後は、学習済みモデルの利用(推論)を説明します。
学習済みモデルの利用(推論)
Stable Diffusion 2.0(512 x 512)をベースに追加学習をしています。
そのため、Stable Diffusion 2.0を利用する環境が必要になります。

実際のコードは、「【Stable Diffusion v2対応】WindowsでDreamBoothを動かす」の記事を参考にしてください。
まずは、「instance_prompt」に指定したプロンプトをそのままを出してみましょう。
man_ga_taro person
学習した画像に近いです。

次は、「man」を表示するように指定します。
a man, man_ga_taro person

カラーでも出るのですね。
「black and white」で白黒指定にした方がよかったかもしれません。
同じように「woman」を指定すると、老婆が出てしまいます。
そのため、「girl」を指定します。
a girl, man_ga_taro person

なんと、モンスターがあまり出ません。
「man」の場合は、ほぼ100%でモンスターが出ていましたが・・・
最後に固有名詞を指定してみましょう。
固有名詞, man_ga_taro person
結論から言うと、イマイチです。

確かに、漫画風として出力することが多いです。
しかし、漫☆画太郎らしさが全くありません。
そこで、感情を表現するワードを追加して試してみました。
漫☆画太郎氏のキャラクターは何かしらキレているのが多いですからね。
Elon Musk in a rage, man_ga_taro person, black and white
このようなプロンプトで試した結果は、以下。

なかなかいい感じになりました。
特にイーロン・マスク氏は最高にハマりました。
それだけ喜怒哀楽の表情(の画像)が豊富なのかもしれません。
以上、学習済みモデルの利用(推論)を説明しました。

