
「すべてのファイルが、UTF-8で保存される世界なら・・・」
このような世界なら、文字コードの判定なんて必要ありません。
でも、日本語を扱う以上はそんな世界を諦めましょう。
当面は、まだまだShift-JISが頑張るはずです。
したがって、Pythonでも文字コードの判定が必要になります。
その際に役に立つのが、chardetライブラリです。
本記事の内容
- chardetとは?
- chardetのシステム要件
- chardetのインストール
- chardetの動作確認
それでは、上記に沿って解説していきます。
chardetとは?
chardetとは、文字コードの自動検出を行うPythonライブラリです。
オープンソースとして開発されています。
自動検出が可能な文字コードは、以下。
- ASCII, UTF-8, UTF-16 (2 variants), UTF-32 (4 variants)
- Big5, GB2312, EUC-TW, HZ-GB-2312, ISO-2022-CN (Traditional and Simplified Chinese)
- EUC-JP, SHIFT_JIS, CP932, ISO-2022-JP (Japanese)
- EUC-KR, ISO-2022-KR, Johab (Korean)
- KOI8-R, MacCyrillic, IBM855, IBM866, ISO-8859-5, windows-1251 (Cyrillic)
- ISO-8859-5, windows-1251 (Bulgarian)
- ISO-8859-1, windows-1252 (Western European languages)
- ISO-8859-7, windows-1253 (Greek)
- ISO-8859-8, windows-1255 (Visual and Logical Hebrew)
- TIS-620 (Thai)
そして、chardetの文字コード検出の精度はFireFoxと同レベルと言えます。
なぜなら、chardetはMozillaの自動検出コードを移植しているからです。
ただ、文字コードの検出をchardet任せにするのは違うようです。
明示的に指定されている場合は、そちらを優先することも必要になります。
例えば、以下のような明示的なケースです。
- HTTPプロトコルにおけるContent-Typeヘッダーのcharset
- HTML文書における<meta http-equiv=”content-type”>
- XML文書における<?xml version=”1.0″ encoding=”●●●” ?>
そうは言っても、FifeFoxと同じレベルで検出できるなら、そっちに任せたいと感じます。
それは、各自で判断してください。
また、chardetには二つの利用パターンがあります。
- コマンドラインツール
- Python API
それぞれを以下で説明します。
コマンドラインツール
簡単に言うと、nkfコマンドです。
nkfコマンドが使えれば、それほど意味がないのかもしれません。
でも、多言語対応とその精度を考えると、nkfコマンドより使える可能性はあります。
nkfコマンドに不満がある場合は、chardetをコマンドラインツールとして使うのはアリですね。
Python API
やはり、断然こちらの方がchardetを使うケースは多いでしょう。
文字コードを判定して、何かしら次の処理に進みます。
一般的には、ファイルの読み込み時に利用するでしょうね。
ファイルの文字コードに応じて、処理を分岐させるなど。
まとめ
chardetには、FireFoxレベルの文字コード検出が期待できます。
だからかどうかわかりませんが、他ライブラリから利用(依存)されているのを見かけます。
以上、chardetに関する説明でした。
次に、chardetのシステム要件を確認します。
chardetのシステム要件
サポートOSに関しては、以下を含むクロスプラットフォーム対応です。
- Windows
- macOS
- Linux
Pythonが動けば、OSは問わないようです。
ただ、サポート対象となるPythonのバージョンには注意が必要となります。
Python 3.6以降のみサポート対象となっています。
バージョンの範囲が狭くて、厳しいと思う方もいるかもしれません。
でも、これは以下のPythonの公式開発サイクルに準じているだけです。
| バージョン | リリース日 | サポート期限 |
| 3.6 | 2016年12月23日 | 2021年12月 |
| 3.7 | 2018年6月27日 | 2023年6月 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
そのため、chardetのサポート対象範囲は全然厳しくもありません。
むしろ、理想的と言えます。
セキュリティやパフォーマンスを考えたら、公式開発サイクルを守ることがベターです。
以上、chardetのシステム要件の説明でした。
次は、chardetのインストールに関してです。
chardetのインストール
最初に、現状のインストール済みパッケージを確認しておきます。
>pip list Package Version ---------- ------- pip 21.0.1 setuptools 54.2.0
次にするべきことは、pip自体の更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip
では、chardetのインストールです。
chardetのインストールは、以下のコマンドとなります。
pip install chardet
インストールは、一瞬で終わります。
では、どんなパッケージがインストールされたのかを確認しましょう。
>pip list Package Version ---------- ------- chardet 4.0.0 pip 21.0.1 setuptools 54.2.0
chardetだけですね。
依存関係のあるパッケージはないということです。
依存関係と言うと、chardetが他のライブラリなどから依存されるケースが多いです。
それだけ文字コードの判別では、優秀なライブラリと言えます。
以上、chardetのインストールの説明でした。
最後は、chardetの動作確認を行います。
chardetの動作確認
chardetには、以下の二つの利用パターンがありました。
- コマンドラインツール
- Python API
それぞれのパターンを確認しましょう。
コマンドラインツール
バージョンは、以下で確認可能です。
>chardetect --version chardetect 4.0.0
次は、nkfコマンドのように利用してみましょう。
まず、文字コードUTF-8のファイルを用意します。
test.txt(UTF-8)
テスト
文字コードの自動検出を実行します。
>chardetect text.txt text.txt: utf-8 with confidence 0.87625
上手く検出できたようです。
信頼性が数字で出るのは、nkfとは違いますね。
Python API
HOYA株式会社のWebサイトの文字コードを検出しています。
import urllib.request
import chardet
rawdata = urllib.request.urlopen("https://www.hoya.co.jp/").read()
print(chardet.detect(rawdata))
上記を実行した結果は、以下。
{'encoding': 'SHIFT_JIS', 'confidence': 0.99, 'language': 'Japanese'}
大企業であるHOYAのwebサイトは、SHIFT_JISという判定が出ています。
念のため、次の情報も確認しました。
- HTTPプロトコルにおけるContent-Typeヘッダーのcharset
- HTML文書における<meta http-equiv=”content-type”>
HTTPプロトコルにおけるContent-Typeヘッダーのcharset
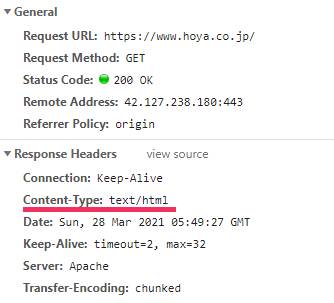
未設定です。
HTML文書における<meta http-equiv=”content-type”>

Shift_JISが設定されています。
上記より、HOYA株式会社のWebサイトはShift_JISだと断定できます。
そして、chardetが問題なく動作していると言えます。
まとめ
コマンドラインツールとPython APIの両方において、 chardetの動作確認を行いました。
使い方次第では、コマンドラインツールもそれなりに需要はありそうです。
そうは言っても、Python APIとしての利用の方が多くなるでしょう。
上記で行ったように、スクレイピングする場合にchardetは効果を発揮しそうです。
すべてのWebサイトがUTF-8というわけではありません。
HOYAのような大企業であっても、 Shift_JISであるというが日本の現状かもしれません。
そうだとしたら、不特定多数のWebサイトをスクレイピングする際にはchardetが活躍しそうです。

