「WebページをPythonでPDFに変換したい」
「Pythonを用いてHTMLコンテンツからPDFを生成したい」
このような場合には、pdfkitがオススメです。
この記事では、pdfkitのインストールについて解説しています。
本記事の内容
- pdfkitとは?
- pdfkitのシステム要件
- pdfkitのインストール
- pdfkitの動作確認
それでは、上記に沿って解説していきます。
pdfkitとは?
pdfkitとは、HTMLをPDFに変換するためのPythonライブラリです。
ただし、pdfkit単体ではHTMLをPDFに変換することはできません。
HTMLをPDFに変換する処理は、wkhtmltopdfで行います。
wkhtmltopdfについては、次の記事で説明しています。

Pythonからwkhtmltopdfを扱うために、pdfkitが存在するということです。
つまり、pdfkitはwkhtmltopdfのためのラッパーと言えます。
そのため、pdfkitを利用するためにはwkhtmltopdfの存在が前提となります。
別途、wkhtmltopdfをインストールしておく必要があるということです。
HTMLをPDFに変換するとは、具体的には次の3パターンがあります。
- URLからPDFへ
- HTMLからPDFへ
- 文字列からPDFへ
外部コンテンツをPDFとして保存する場合は、「URLからPDFへ」を用います。
この際には、遅延読み込みなどの動的処理を用いる必要があるかもしれません。
内部コンテンツをPDFファイルとして生成する場合は、残りの二つを用いることになります。
一旦HTMlファイルとして保存するのか、そのままPDFとして出力するのかの違いです。
以上、pdfkitについて説明しました。
次は、pdfkitのシステム要件を説明します。
pdfkitのシステム要件
現時点(2023年8月7日)でのpdfkitの最新バージョンは、1.0.0となります。
2021年11月15日に1.0.0をリリースして以降は、動きがありません。

もしかしたら、1.0.0で完成したということかもしれません。
言い方はあれですが、所詮はwkhtmltopdfのラッパーということでしょうか。
サポートOSに関しては、以下を含むクロスプラットフォーム対応です。
- Windows
- macOS
- Linux
サポート対象となるPythonのバージョンは、Python 3.9までとなっています。
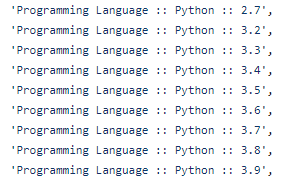
これは、2021年11月15日で開発が止まっているからでしょう。
単純にPython 3.10以降でテストをしてないというだけです。
実際、Python 3.11でも動作はできています。
そのため、Python 3.10以降でも問題はなりでしょう。
あと、システム要件で最も重要なことはwkhtmltopdfとなります。
wkhtmltopdfがインストール済みであることがmustです。
もっと具体的に言うと、以下のコマンドがOSのどこからでも利用できる必要があります。
>wkhtmltopdf -V wkhtmltopdf 0.12.6 (with patched qt)
以上、pdfkitのシステム要件を説明しました。
次は、pdfkitのインストールを説明します。
pdfkitのインストール
検証は、次のバージョンのPythonで行います。
> python -V Python 3.11.0
まずは、現状のインストール済みパッケージを確認しておきます。
> pip list Package Version ---------- ------- pdfkit 1.0.0 pip 23.2.1 wheel 0.38.4
次にするべきことは、pipとsetuptoolsの更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip setuptools
では、pdfkitのインストールです。
pdfkitのインストールは、以下のコマンドとなります。
pip install pdfkit
pdfkitのインストールは、すぐに終わります。
終了したら、どんなパッケージがインストールされたのかを確認します。
> pip list Package Version ---------- ------- pdfkit 1.0.0 pip 23.2.1 setuptools 68.0.0 wheel 0.38.4
pdfkitは、他に依存関係もなく簡潔ということがわかりますね。
以上、pdfkitのインストールを説明しました。
次は、pdfkitの動作確認を説明します。
pdfkitの動作確認
pdfkitの動作確認を行います。
pdfkitの機能としては、以下の3パターンがありましたね。
- URLからPDFへ
- HTMLからPDFへ
- 文字列からPDFへ
それぞれの動作を確認します。
URLからPDFへ
def from_url(url: Any,
output_path: Any = None,
options: Any = None,
toc: Any = None,
cover: Any = None,
configuration: Any = None,
cover_first: bool = False,
verbose: bool = False) -> bytes | bool
URLからPDFへ変換するには、上記関数を用います。
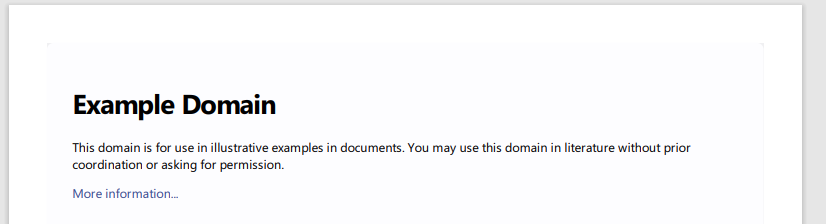
import pdfkit # 変換したいURL url = 'https://example.com' # 出力となるPDFファイルのパス output_path = 'url.pdf' # URLからPDFに変換 pdfkit.from_url(url, output_path)
このコードを実行すると、次の内容を持つPDFが作成されます。
url.pdf
HTMLからPDFへ
def from_file(input: Any,
output_path: Any = None,
options: Any = None,
toc: Any = None,
cover: Any = None,
css: Any = None,
configuration: Any = None,
cover_first: bool = False,
verbose: bool = False) -> bytes | bool
HTMLからPDFへ変換するには、上記関数を用います。
コードを確認する前に、変換対象となるHTMLファイルを用意します。
今回は、「Example Domain」のソースをもとに次のようなファイルを生成しています。
example.html
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>例 Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
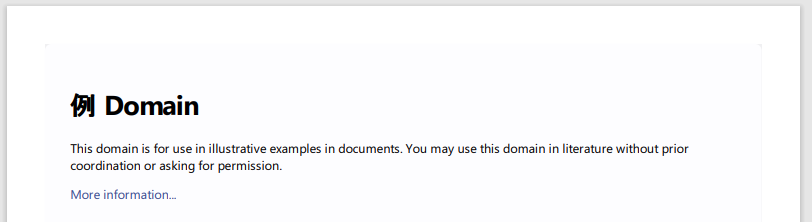
これは、以下のように変更しているだけです。
日本語の検証にもなります。
<h1>Example Domain</h1>
↓ ↓↓
<h1>例 Domain</h1>
実行するコードは、以下。
import pdfkit # 入力となるHTMLファイルのパス input_path = 'example.html' # 出力となるPDFファイルのパス output_path = 'html.pdf' # HTMLファイルをPDFに変換 pdfkit.from_file(input_path, output_path)
このコードを実行すると、次の内容のPDFが作成されます。
html.pdf
文字列からPDFへ
def from_string(input: Any,
output_path: Any = None,
options: Any = None,
toc: Any = None,
cover: Any = None,
css: Any = None,
configuration: Any = None,
cover_first: bool = False,
verbose: bool = False) -> bytes | bool
文字列からPDFへ変換するには、上記関数を用います。
import pdfkit
# 変換したいHTML文字列
html_string = '''
<!DOCTYPE html>
<html>
<head>
<title>Sample Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML string.</p>
</body>
</html>
'''
# 出力となるPDFファイルのパス
output_path = 'string.pdf'
# HTML文字列からPDFに変換
pdfkit.from_string(html_string, output_path)
このコードを実行すると、次の内容を持つPDFが作成されます。
string.pdf

以上、pdfkitの動作確認を説明しました。