
「Pythonで文字コードの判定を行いたい」
「文字コード判定用のライブラリ・ツールを探している」
このような場合には、charset-normalizerがオススメです。
この記事では、charset-normalizerについて解説しています。
本記事の内容
- charset-normalizerとは?
- charset-normalizerのシステム要件
- charset-normalizerのインストール
- charset-normalizerの動作確認
それでは、上記に沿って解説していきます。
charset-normalizerとは?
charset-normalizerは、文字コード判定を行うPythonライブラリです。
同じような機能を持つライブラリに、chardetが存在します。
charset-normalizerは、chardetの代替品であると公式では主張しています。
chardetについては、次の記事で解説しています。

機能的には、chardetよりもcharset-normalizerの方が勝っているようです。
また、パフォーマンスもcharset-normalizerの方が優れているという結果が出ています。
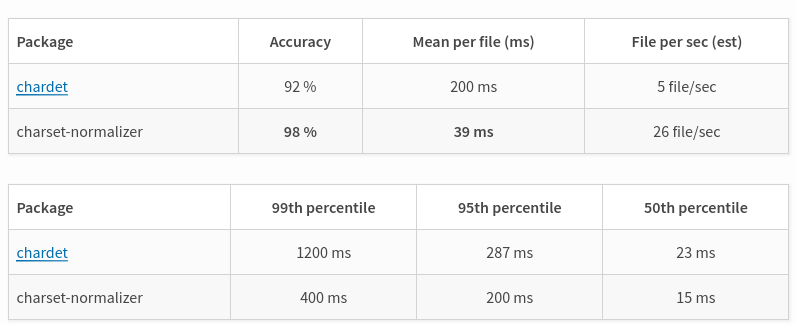
ただ、知名度の点ではchardetが圧勝です。
それぞれのGitHub上の評価は、以下となります。
chardetの評価
charset-normalizerの評価
charset-normalizerは、まだまだ知る人ぞ知るというライブラリかもしれません。
以上、charset-normalizerについて説明しました。
次は、charset-normalizerのシステム要件を説明します。
charset-normalizerのシステム要件
現時点(2022年8月)でのcharset-normalizerの最新バージョンは、2.1.0となります。
この最新バージョンは、2022年6月20日にリリースされています。
サポートOSに関しては、以下を含むクロスプラットフォーム対応です。
- Windows
- macOS
- Linux
サポート対象となるPythonのバージョンは、以下となっています。
- Python 3.6
- Python 3.7
- Python 3.8
- Python 3.9
- Python 3.10
- Python 3.11
以下は、Python公式開発サイクルです。
| バージョン | リリース日 | サポート期限 |
| 3.6 | 2016年12月23日 | 2021年12月23日 |
| 3.7 | 2018年6月27日 | 2023年6月27日 |
| 3.8 | 2019年10月14日 | 2024年10月 |
| 3.9 | 2020年10月5日 | 2025年10月 |
| 3.10 | 2021年10月4日 | 2026年10月 |
Python公式開発サイクルに従うなら、Python 3.7以降となります。
ただ、現時点(2022年8月)でPython 3.11はまだ開発中ですけどね。
以上、charset-normalizerのシステム要件を説明しました。
次は、charset-normalizerのインストールを説明します。
charset-normalizerのインストール
検証は、次のバージョンのPythonで行います。
$ python -V Python 3.10.2
まずは、現状のインストール済みパッケージを確認しておきます。
$ pip list Package Version ---------- ------- pip 22.2.1 setuptools 63.4.0 wheel 0.36.2
次にするべきことは、pipとsetuptoolsの更新です。
pipコマンドを使う場合、常に以下のコマンドを実行しておきましょう。
python -m pip install --upgrade pip setuptools
では、charset-normalizerのインストールです。
charset-normalizerのインストールは、以下のコマンドとなります。
pip install charset-normalizer
charset-normalizerのインストールは、すぐに終わります。
終了したら、どんなパッケージがインストールされたのかを確認します。
$ pip list Package Version ------------------ ------- charset-normalizer 2.1.0 pip 22.2.1 setuptools 63.4.0 wheel 0.36.2
charset-normalizerは、依存するパッケージがありません。
そのため、既存環境にも容易にcharset-normalizerを導入可能です。
以上、charset-normalizerのインストールを説明しました。
次は、charset-normalizerの動作確認を説明します。
charset-normalizerの動作確認
charset-normalizerには、以下の二つの利用方法があります。
- コマンドラインツール
- Python API
それぞれのパターンを確認しましょう。
コマンドラインツール
バージョンは、以下で確認可能です。
$ normalizer --version Charset-Normalizer 2.1.0 - Python 3.10.2 - Unicode 13.0.0
では、nkfコマンドのように利用してみましょう。
まず、文字コードUTF-8のファイルを用意します。
test.txt(UTF-8)
テスト
このファイルを対象にして、文字コードの自動検出を行います。
$ normalizer /tmp/test.txt
{
"path": "/tmp/test.txt",
"encoding": "utf_8",
"encoding_aliases": [
"u8",
"utf",
"utf8",
"utf8_ucs2",
"utf8_ucs4",
"cp65001"
],
"alternative_encodings": [],
"language": "Unknown",
"alphabets": [
"Katakana"
],
"has_sig_or_bom": false,
"chaos": 0.0,
"coherence": 0.0,
"unicode_path": null,
"is_preferred": true
}
実行した結果は、JSON形式で出力されています。
どうやら、日本語とまでは判定できなかったようです。
情報(文字数)が不足しているのかもしれません。
Python API
次のコードでは、ある企業のWebサイトにおける文字コードを検出しています。
今回は、PC用ページが対象です
from charset_normalizer import detect
import urllib.request
rawdata = urllib.request.urlopen("https://www.forval.co.jp/").read()
result = detect(rawdata)
print(result)
上記を実行した結果は、以下。
{'encoding': 'EUC-JP', 'language': 'Japanese', 'confidence': 1.0}
charset-normalizerは、100%の信頼性で「EUC-JP」だと判定しています。
凄い自信ですね。
さらには、日本語とも判定しています。
それでは、実際に株式会社フォーバルのサイトを確認してみましょう。

metaタグでは、「euc-jp」が記述されています。
では、レスポンスヘッダを確認します。
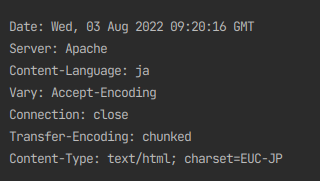
こちらでも「EUC-JP」ですね。
よって、charset-normalizerの判定は正しいと言えます。
令和の時代にいくらPCサイトと言え、「EUC-JP」は厳しいモノがあります。
一応この企業(株式会社フォーバル)は、東証1部上場企業ですからね。
あと、wikipediaには次のように記載されています。
株式会社フォーバル (FORVAL Corporation) は、中小企業に対し、主にビジネスフォン、OA機器、セキュリティーシステムやウェブサイト作成サービスなどの卸売販売を行う企業。
卸売販売とは言え、一応ウェブサイトを扱う以上は自社のサイトにもっと配慮が必要でしょう。
以上、charset-normalizerの動作確認を説明しました。

