
「Stable Diffusionで画像の精度を上げたい」
「テキストエンコーダのモデルによる画像精度の影響度を知りたい」
このような場合には、この記事の内容が参考になります。
この記事では、テキストエンコーダの変更が画像精度に与える効果を解説しています。
本記事の内容
- テキストエンコーダの変更
- CLIP-ViT-g-14-laion2B-s12B-b42Kの効果検証
- CLIP-ViT-H-14-laion2B-s32B-b79Kの効果検証
- 効果検証のまとめ
それでは、上記に沿って解説していきます。
テキストエンコーダの変更
Stable Diffusionでは、テキストエンコーダというモノが利用されています。
このテキストエンコーダがあるからこそ、テキストから画像の生成が可能になっています。
デフォルトでは、次のテキストエンコーダ用モデルが利用されています。
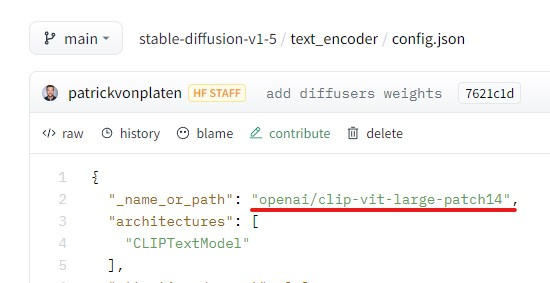
このデフォルトのモデルは、次の表における「ViT-L-14 openai」に該当します。
5番目に精度が良いモデルになります。

上の表は、テキストエンコーダのモデル一覧です。
精度の良いモノから表示されています。
つまり、「mean」が低いほど精度が良いということです。
Stable Diffusionでは、テキストエンコーダのモデルを変更できます。
そのためには、CLIP Guided Stable Diffusionを利用します。
CLIP Guided Stable Diffusionについては、次の記事で詳しく説明しています。
今回は、上位のモデルを利用した場合の効果検証を行います。
利用するのは、2トップのモデルです。
- CLIP-ViT-g-14-laion2B-s12B-b42K
- CLIP-ViT-H-14-laion2B-s32B-b79K
利用するプロンプトについては、上記記事を参考にしてください。
以上、テキストエンコーダの変更を説明しました。
次は、CLIP-ViT-g-14-laion2B-s12B-b42Kの効果検証を説明します。
CLIP-ViT-g-14-laion2B-s12B-b42Kの効果検証
最も良いテキストエンコーダのモデルになります。
ただし、このモデルのサイズは約5.5GBあります。
デフォルトのViT-L-14 openaiが、約1.7GBのサイズです。
よって、さらに追加で約4GBのVRAMが必要になります。
検証マシンは、次のGPUを搭載しています。
> nvidia-smi --query-gpu=name,memory.total,memory.free --format=csv,noheader NVIDIA GeForce RTX 3090, 24576 MiB, 23889 MiB
このGPUでも、torch_dtypeがfloat32ならメモリ不足になりました。
したがって、float16にして処理するように変更しています。
そのように調整して、出来上がった画像は以下。
自然

人工物

人(顔)

以上、CLIP-ViT-g-14-laion2B-s12B-b42Kの効果検証を説明しました。
次は、CLIP-ViT-H-14-laion2B-s32B-b79Kの効果検証を説明します。
CLIP-ViT-H-14-laion2B-s32B-b79Kの効果検証
2番目に精度が良いとされているモデルになります。
このモデルのサイズは、約3.9GBです。
こちらのモデルは、torch_dtypeがfloat32のままで処理できました。
float16とfloat32とでは、生成される画像の精度が若干異なります。
もちろん、float32の方が良いです。
でも、そこまで大きな影響はないと考えています。
よって、その差異は無視して画像をご覧ください。
自然

人工物

人(顔)

以上、CLIP-ViT-H-14-laion2B-s32B-b79Kの効果検証を説明しました。
最後に、効果検証のまとめを説明します。
効果検証のまとめ
確実に言えるのは、上位2つのモデルは精度がUPするということです。
ただし、上位2つのモデルにおいて甲乙は簡単にはつけられません。
「自然」と「人(顔)」では、見る人によって評価は異なるでしょう。
正直、好き嫌いで決まるようなレベルです。
しかし、「人工物」では評価が一致するのではないでしょうか?
全部が全部最高モデルの勝利とは言えませんが、1枚目の画像なんて圧勝だと思います。
左:CLIP-ViT-g-14-laion2B-s12B-b42K
右:CLIP-ViT-H-14-laion2B-s32B-b79K

そうだとしても、CLIP-ViT-H-14-laion2B-s32B-b79Kもかなり精度はUPしています。
Stable Diffusionでは、プロンプトが重要なことに変わりはありません。
ただ、テキストエンコーダも重要な要素だということがわかりました。
採用するモデルによって、精度に大きな差が出てしまいますからね。
以上、効果検証のまとめを説明しました。

